
LeCun预言的自监督模型来了:首个多模态高性能自监督算法,语音、图像文本全部SOTA
人类似乎对不同的学习模式有着相似的认知,机器也应该如此!


论文地址:https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
项目地址:https://github.com/pytorch/fairseq/tree/main/examples/data2vec
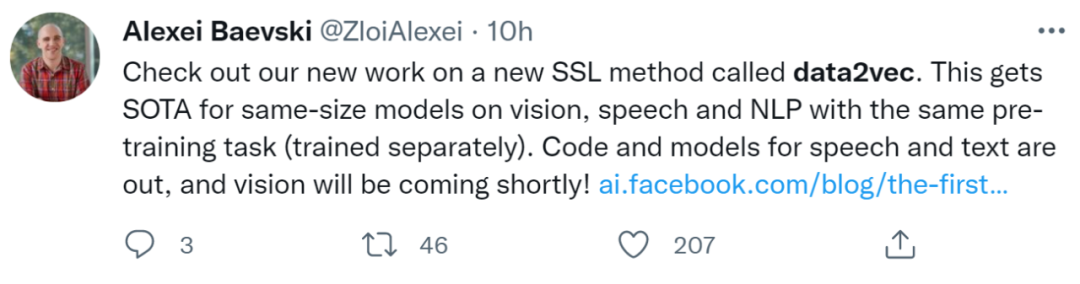



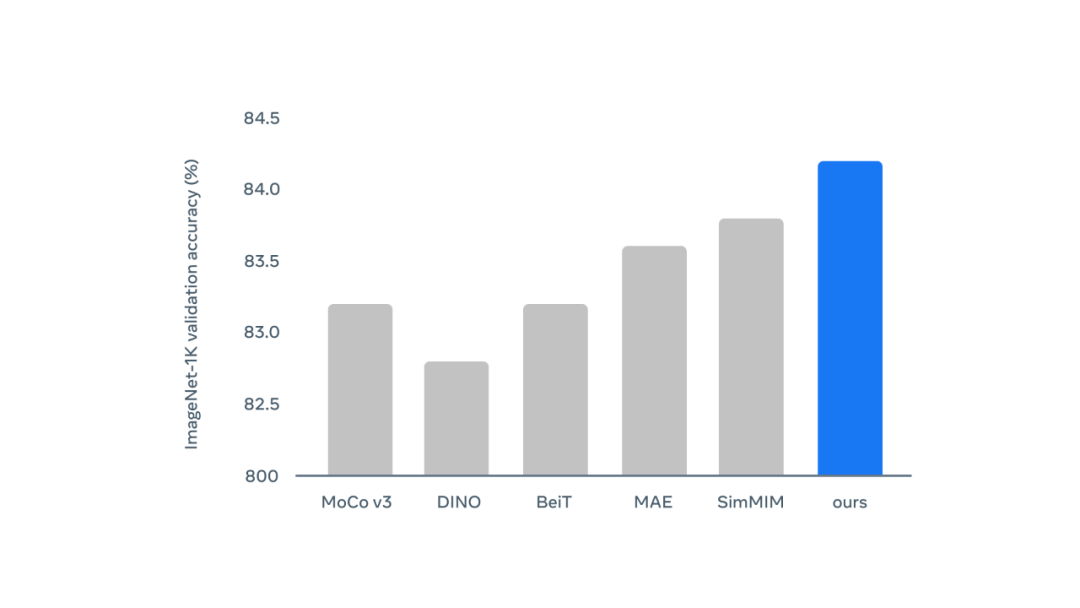
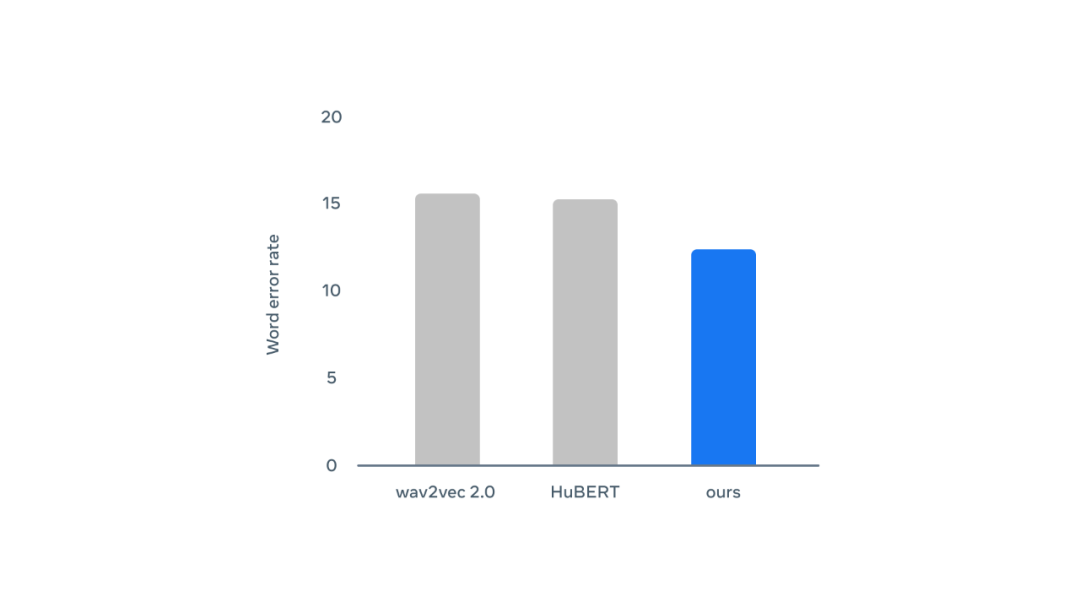
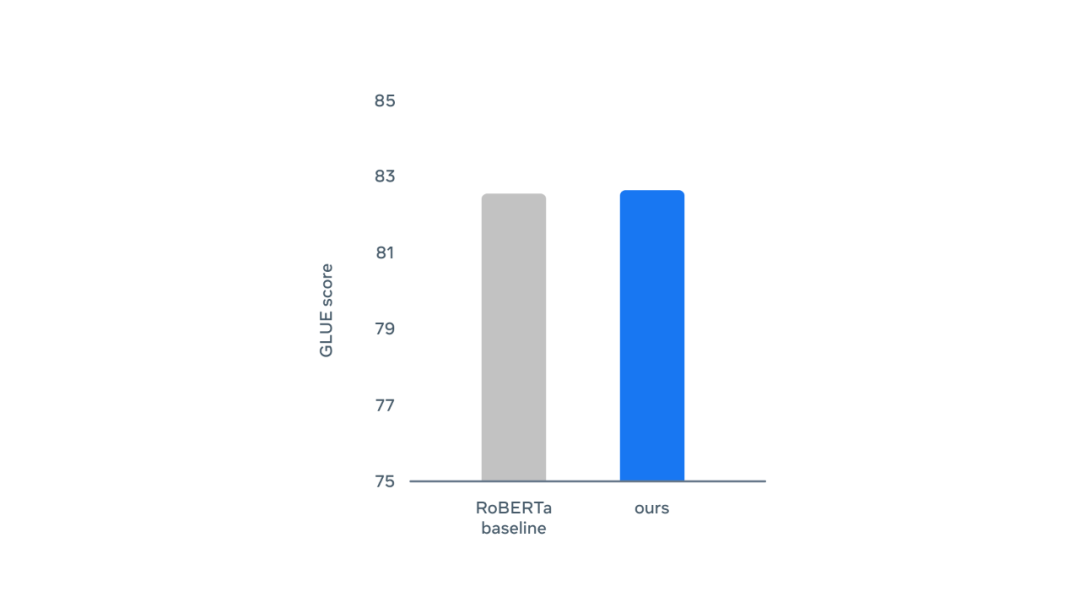

评论