
LeCun怒斥Sora是世界模型,自回归LLM太简化了
来源:机器之心
LeCun 对「世界模型」给出了最新定义。
最近几天,Sora 成为了全世界关注的焦点。与之相关的一切,都被放大到极致。Sora 如此出圈,不仅在于它能输出高质量的视频,更在于 OpenAI 将其定义为一个「世界模拟器」(world simulators)。

英伟达高级研究科学家 Jim Fan 甚至断言:「Sora 是一个数据驱动的物理引擎」,「是一个可学习的模拟器,或『世界模型』」。


「Sora 是世界模型」这种观点,让一直将「世界模型」作为研究重心的图灵奖得主 Yann LeCun 有些坐不住了。在 LeCun 看来,仅仅根据 prompt 生成逼真视频并不能代表一个模型理解了物理世界,生成视频的过程与基于世界模型的因果预测完全不同。
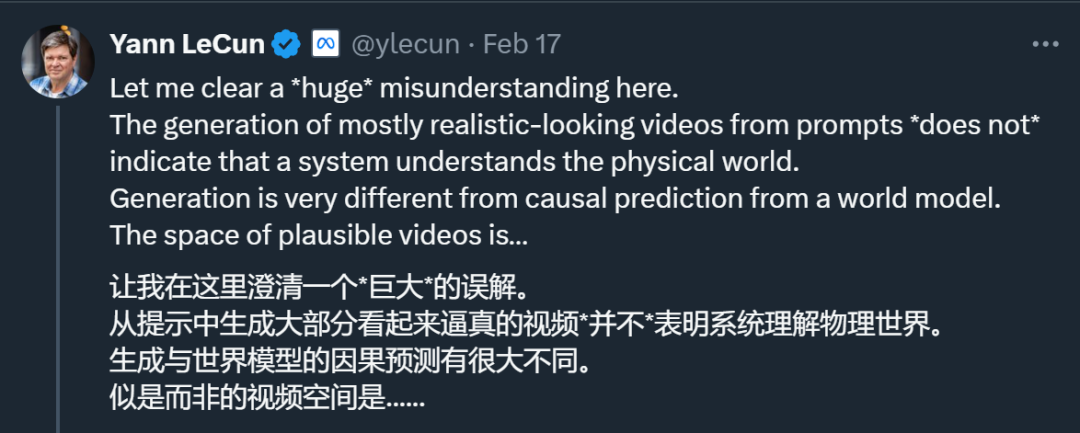 图源:https://twitter.com/ylecun/status/1758740106955952191
图源:https://twitter.com/ylecun/status/1758740106955952191 虽然 Sora 的发布让整个 AI 界为之疯狂,但 LeCun 并不看好。他不止一次的公开表达过对自回归和 LLM 的批评,而自回归模型是包括 Sora 等在内的 GPT 系列 LLM 模型所依赖的学习范式,也就是说,从 ChatGPT 到 Sora,OpenAI 都是采用的自回归生成式路线。
然而 LeCun 多次唱衰这种技术路线,他曾表达过一些不满,比如「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」「自回归生成模型弱爆了!(Auto-Regressive Generative Models suck!)」「LLM 对世界的理解非常肤浅。」等言论。
世界模型和自回归 LLM 到底该如何定义?身为全球知名的 AI 研究学者,LeCun 自然不是一位全然的批评家,最近,他给出了世界模型的新定义。在他看来,自回归生成模型仅仅是世界模型的一种简化的特殊情况。与大家在互联网上看到的动不动就是长篇大论的科普不同,LeCun 以一种简单直白的方式给出了世界模型的定义。
 图源:https://twitter.com/ylecun/status/1759933365241921817
图源:https://twitter.com/ylecun/status/1759933365241921817 对于给定的:
- 观察值 x (t);
- 对世界状态的先前估计 s (t);
- 动作建议 a (t);
- 潜在变量建议 z (t)。
世界模型需要计算出:
- 表征:h (t) = Enc (x (t));
- 给出预测:s (t+1) = Pred ( h (t), s (t), z (t), a (t) )。
其中,
- Enc () 是一个编码器(我们可以理解为一个可训练的确定性函数,例如神经网络);
- Pred () 是一个隐藏状态预测器(也是一个可训练的确定性函数);
- 潜在变量 z (t) 代表未知信息,可以准确预测将来会发生什么。z (t) 变量必须从一个分布中进行采样,或者在一组中变化。它参数化了(或分布)一系列可能的预测。换句话说,变量 z (t) 定义了一个可能性空间,我们根据这个空间来预测未来可能发生的情况。
诀窍是通过观察三元组 (x (t),a (t),x (t+1)) 来训练整个模型,同时防止 Encoder 坍缩。
自回归生成模型(例如 LLM,Sora 就是这种路线)是一种简化的特殊情况,原因在于:
1. Encoder 是恒等函数:h (t) = x (t); 2. 状态是过去输入的窗口; 3. 没有动作变量 a (t); 4. x (t) 是离散的; 5. 预测器计算 x (t+1) 结果的分布,并使用潜在 z (t) 从该分布中选择一个值。
方程简化为:
s (t) = [x (t),x (t-1),...x (t-k)] x (t+1) = Pred ( s (t), z (t), a (t) )
在这种情况下不存在坍缩问题。
这可能就是 LeCun 极力反对 Sora 是世界模型这种说法的一个重要原因 —— 它只是世界模型中一种简化的特殊情况。
不过话说回来,Jim Fan 又在 LeCun 的这条推文下方留言,他坚持道:「Sora 本质上是一种无操作(no-op)的世界模型。你可以设置世界的初始状态,在潜在空间中运行模拟,并被动地观察会发生什么。现在没有办法进行积极干预。」
至于 Sora 到底是不是世界模型我们暂且不议,混淆大家多时的「世界模型」的定义,现在终于被 LeCun 讲明白了。
——The End——

分享
收藏
点赞
在看
评论