
2022 Top10自监督学习模型发布!美中两国8项成果霸榜
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
【导读】2022年十大自监督学习模型出炉!中国清华大学、北京大学和香港中文大学(深圳)项目入选,荣登亚洲第一,世界第二。微软公司成为上榜最多的公司,共有三项成果。

Data2vec

论文链接:https://arxiv.org/pdf/2202.03555.pdf
开源代码:https://t.co/3x8VCwGI2x pic.twitter.com/Q9TNDg1paj
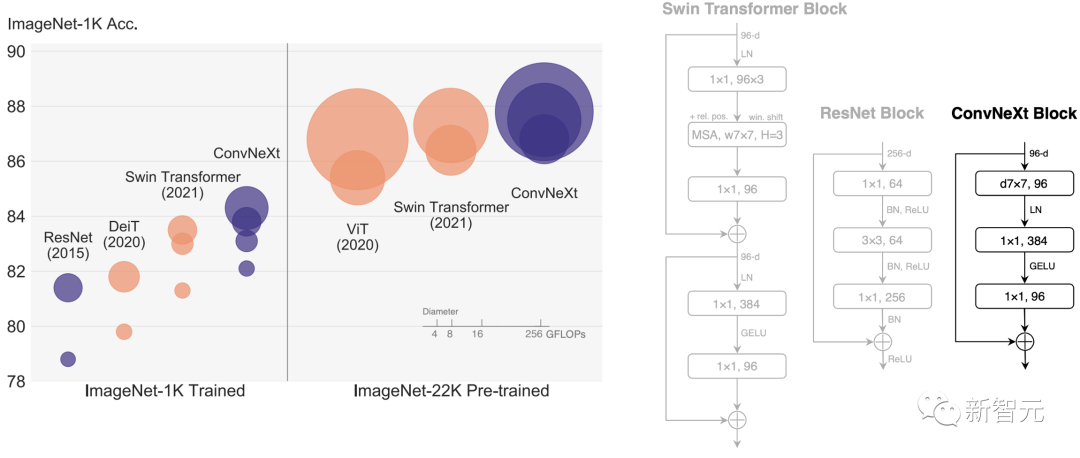
Meta AI 在一月份发布了 data2vec 算法,用于语音、图像和文本相关的计算机视觉模型。据AI团队表示,该模型在NLP任务中具有很强的竞争力。


论文链接:https://arxiv.org/pdf/2201.03545.pdf








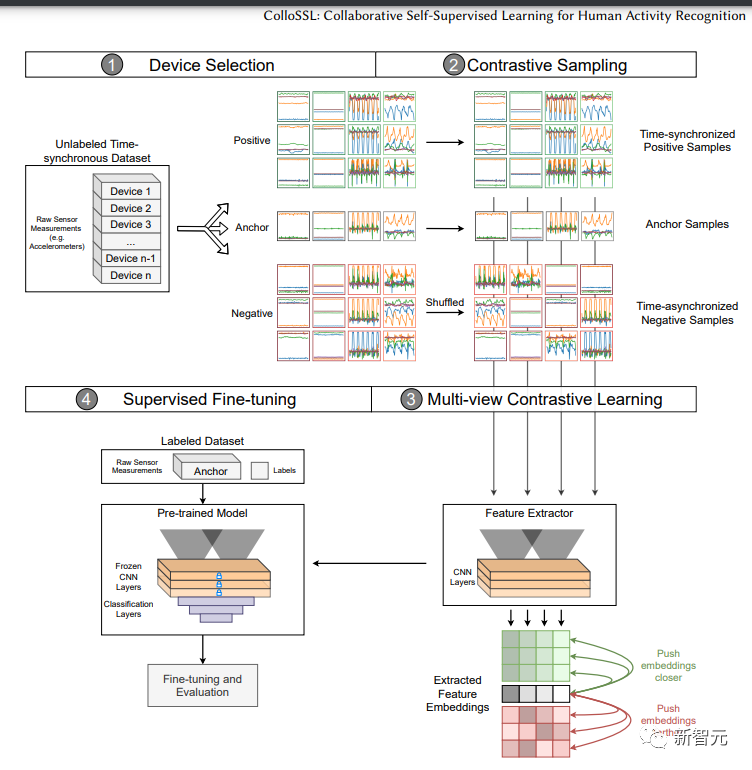

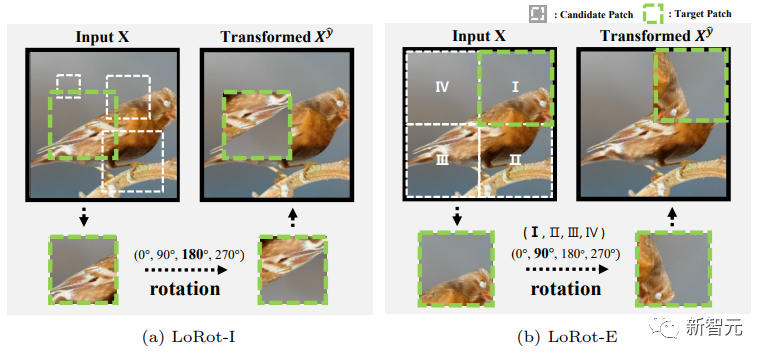
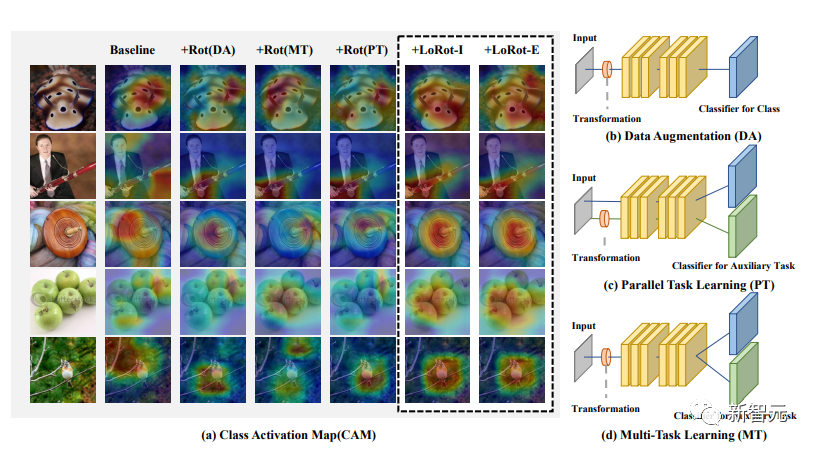

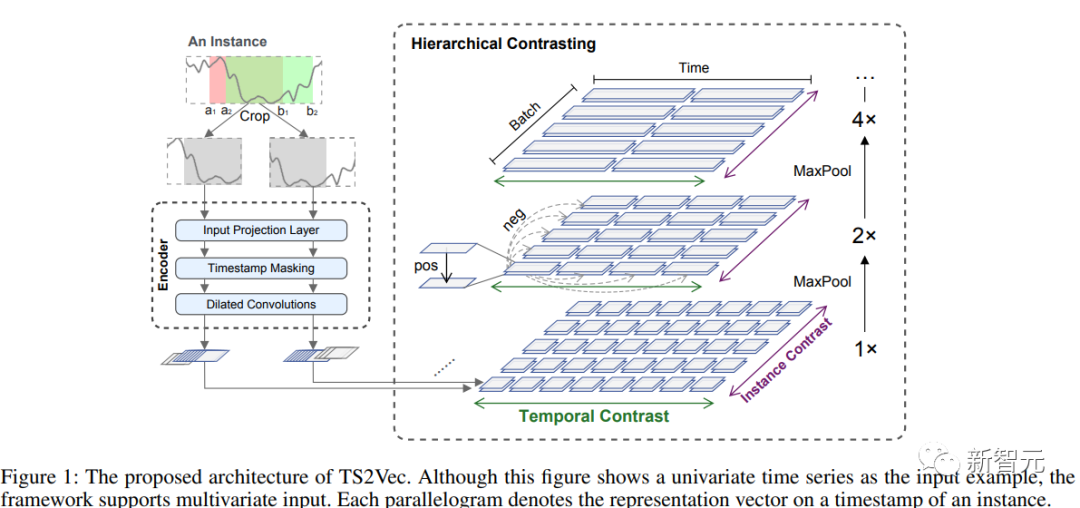
来源:新智元
本文仅做学术分享,如有侵权,请联系删文。
评论