计算机视觉中低延迟检测的相关理论和应用

极市导读
本文作者介绍了自己关于视频中物体低延迟检测的工作,内容包括工作背景、实现思路、遭遇的问题和相关思考等,值得参考。
计算机视觉中低延迟检测的相关理论和应用(上)
写在前边
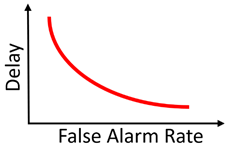


背景理论
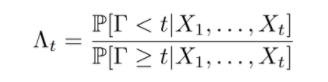
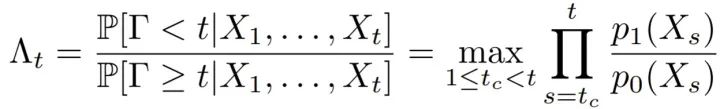
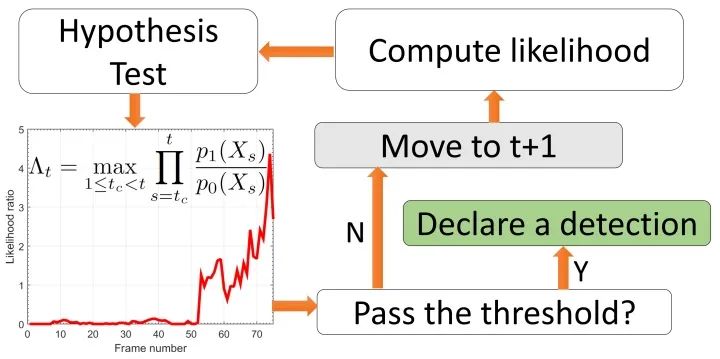
移动物体检测
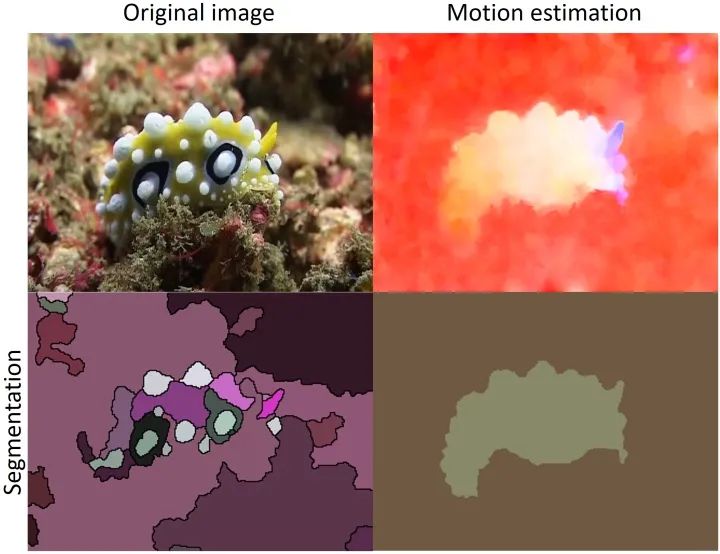

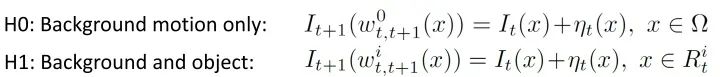
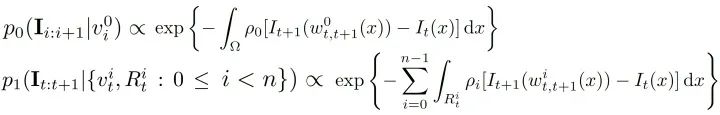
后续和一些感想
计算机视觉中低延迟检测的相关理论和应用(下)
写在前边
前情提要
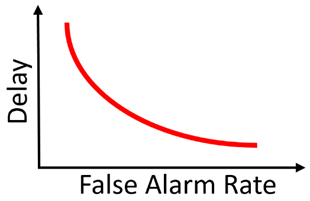
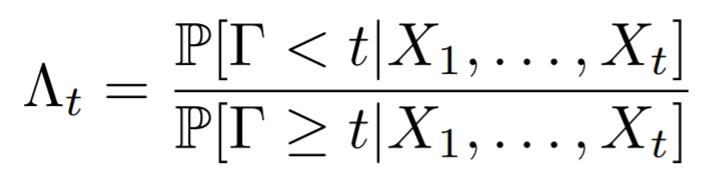
低延迟检测的思路

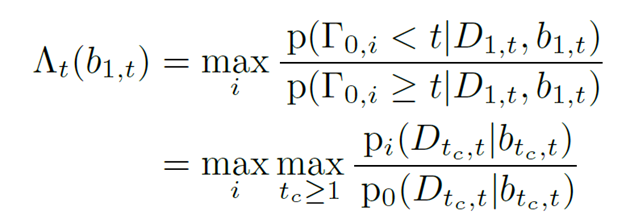
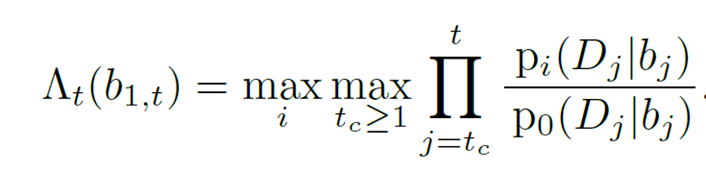
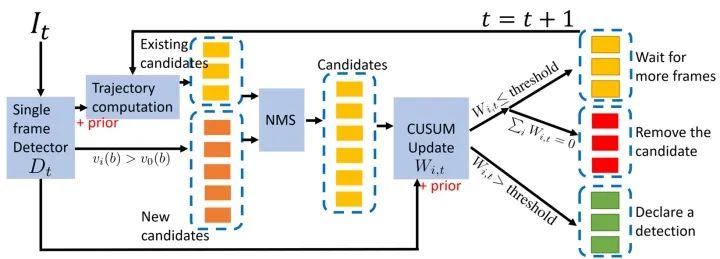
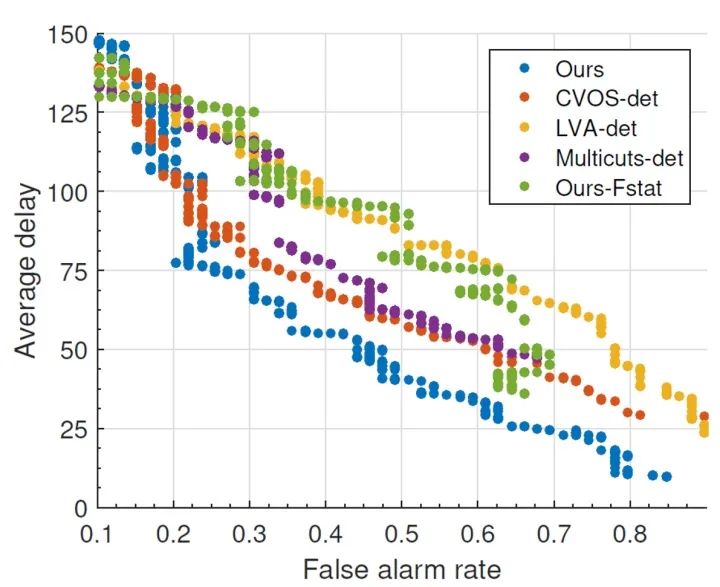
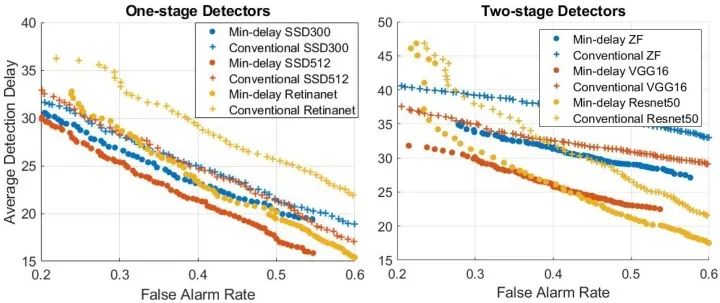
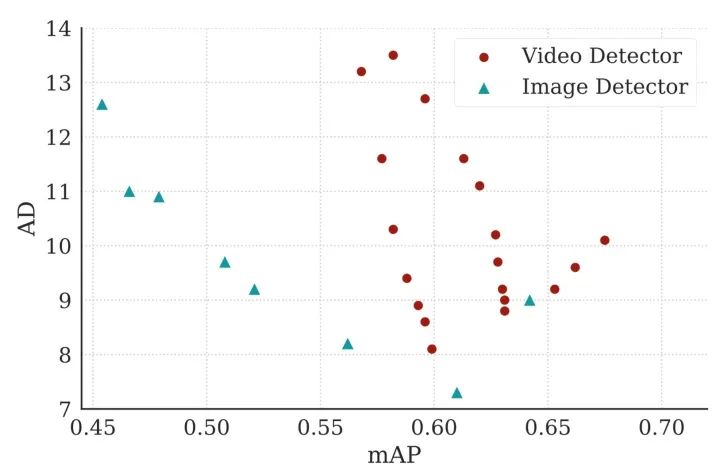
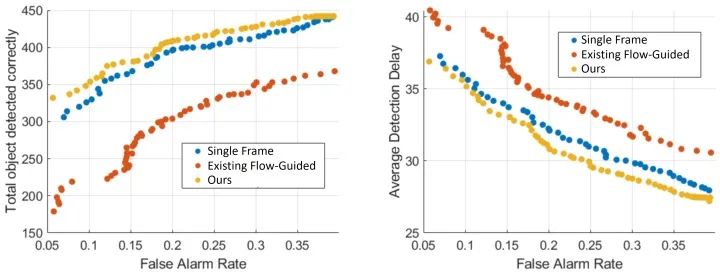
结果
后续和一些感想
推荐阅读

评论
 下载APP
下载APP极市导读
本文作者介绍了自己关于视频中物体低延迟检测的工作,内容包括工作背景、实现思路、遭遇的问题和相关思考等,值得参考。
推荐阅读