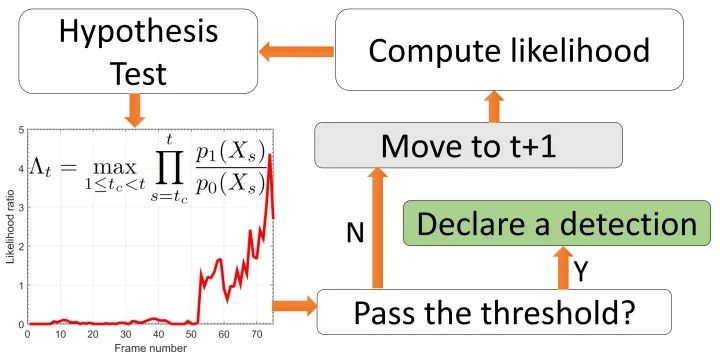
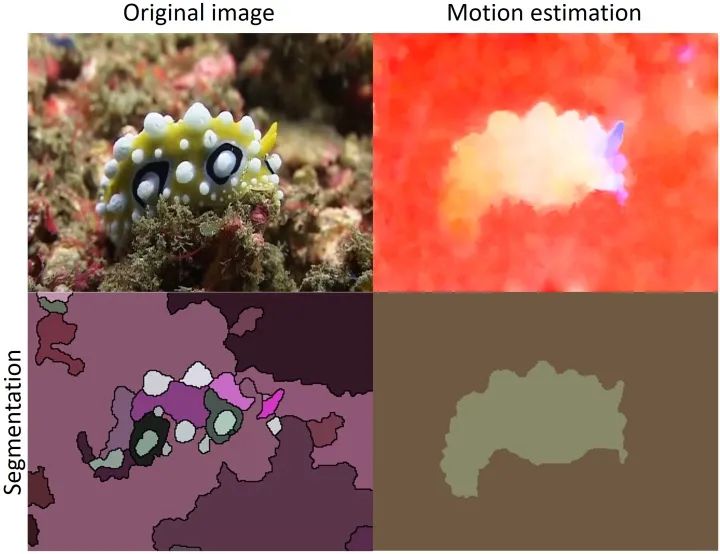
首先还是说一下这个工作里的坑。说实话,这样一个工作更大的意义是学理上验证了这套理论在视觉中的应用,距离工程上的应用,还有很大的距离。部分原因在于,由于工作完成的时间是2016年,当时还没有成熟可靠的快速光流算法和分割算法。而这个工作需要大量的帧到帧之间的运算,所以在实际运算时间上可以说是惨不忍睹。第二点,如果仔细看过上边的结果视频,不难发现,composed motion经常出现重影,对分割结果造成影响。这也直接促成了我们用layered model解决移动物体分割的后续工作。关于这种重影,我会将来填“详解移动物体分割、光流和遮挡之间的联系”坑的时候详细介绍。低延迟的检测是我2015年本科毕业后,零计算机基础入坑视觉做的第一个工作。当时我的博士导师给我扔过来三篇论文,让我挑其中一篇最感兴趣的当科研方向,[1]就是其中一篇。现在回头想想导师也算是看得起我,一上来扔过来的都是这样“硬核”的内容。搞这个工作的时候,其实相当头疼,毕竟作为一个零基础的学生,一上来就要平地起高楼做一个从没有人提出过的问题,从白纸开始写代码,自己收集数据集,找人做的标注,由于没有相关工作,还要从其他方法中创造baseline,总体来说很有挑战性。虽然相比直接从深度学习入坑CV的同学,这让我对采用不同思路决视觉问题有更多想法(这在之后的科研过程中帮了大忙),但是也让我错过了17年之前深度学习“随便做做就能发文章”的爆发期。不过,在之后的专栏中,我会介绍如何把低延迟检测的理论和基于深度学习的检测器进行结合,让这套理论在视觉问题上真正变得可用。参考资料[1] V. V. Veeravalli and T. Banerjee. Quickest change detection. Academic press library in signal processing: Array and statistical signal processing, 3:209–256, 2013.[2] Dong Lao and Ganesh Sundaramoorthi. Minimum delay moving object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4250–4259, 2017.
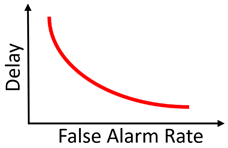
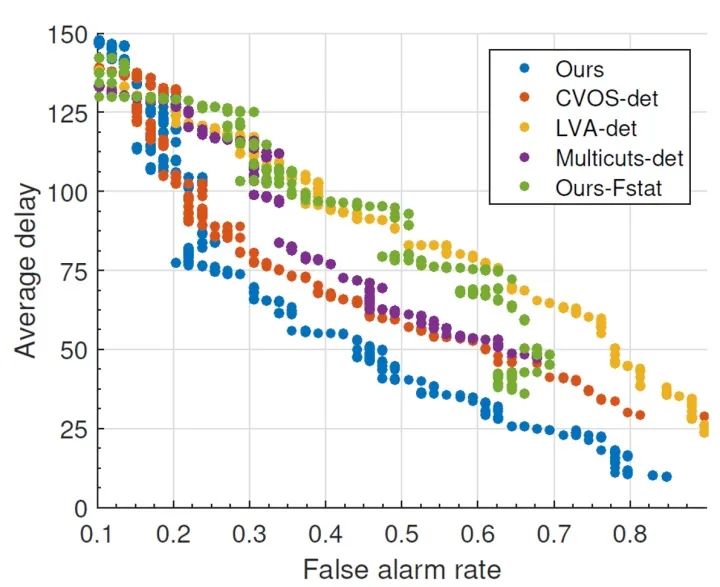
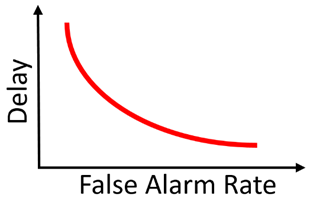
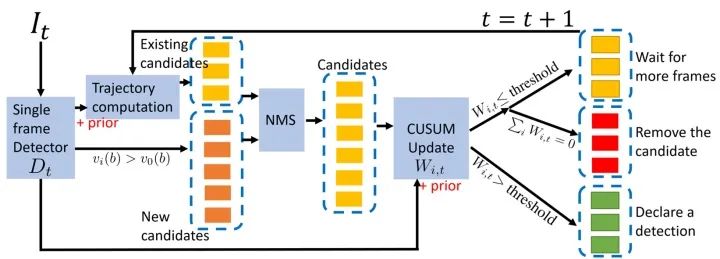
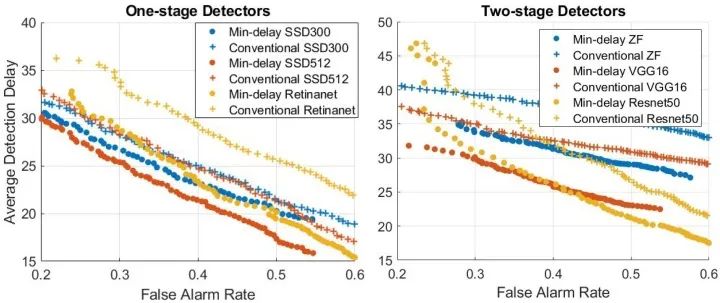
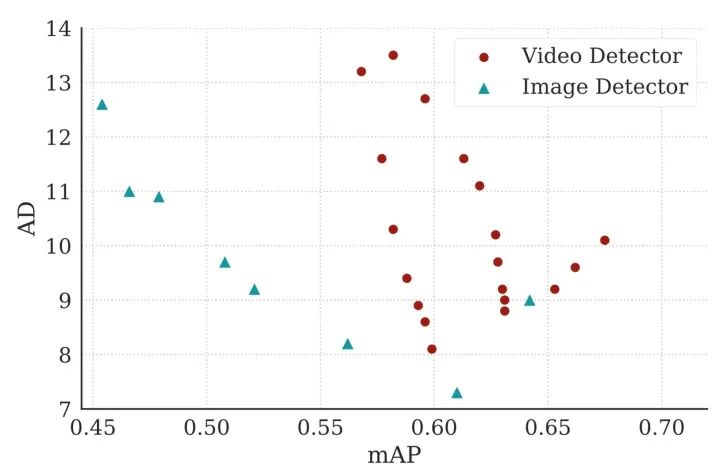
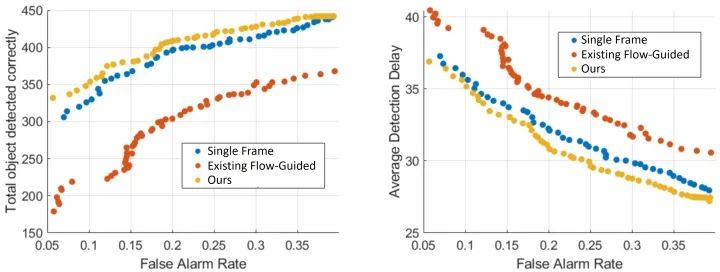
写这篇论文的时候,我查阅了不少关于“视频物体检测”的文献,加上通过和一些业界大佬交流,发现已有的“视频物体检测”算法,例如基于光流的Feature Aggregation、3D 卷积等技术,目前基本上没法真正落地(如果说的不对请指正)。究其原因,一是不少方法纯炼丹,对数据的依赖强,缺少一个solid的理论框架(这也是深度学习通病);二是这些方法根本没有考虑真正在工业应用上的部署,比如视频物体检测往往要固定temporal window size,极大限制了算法的落地空间。在我做这一篇工作的同期,斯坦福大学Bill Dally教授组的Huizi Mao同样出品了一篇关于检测延迟和检测精度关系的论文《A Delay Metric for Video Object Detection: What Average Precision Fails to Tell》[3]。在这篇论文中得出结论,同等精度下,目前使用多帧的视频物体检测方法在延迟方面输给单帧检测器。Mao et al., ICCV 2019.出于好奇,我在本文框架下,也对已有的视频物体检测算法做了些测试,同样发现同等误报率下,已有方法同样不如单帧(结果未随论文发表)。两篇论文虽然metric不同,但是结论几乎一样。这也就意味着,在真的产品部署中,需要大量运算的视频检测器不但没有提高检测效率,反而帮了倒忙。另一方面,工业界对于比单帧更稳定的检测器却有着货真价实的需求。比如据说某厂在开发工业探伤算法过程中,发现单帧Fast-RCNN的输出非常noisy。如今在一些产品(例如机器人、自动驾驶、垃圾分拣)中,由于软硬件限制,要想进一步提高单帧的检测精度非常之难。与此同时,相机多抓取一帧,多跑一遍检测算法却并不难。在这样一套可以自由融合多帧的框架下,改变思路,用一定的检测延迟换取更高的精度也许是个有趣的方向。说实话,对于端到端炼丹在各视频应用上(不只是检测)难以真正有效这件事,大家也只能心照不宣。真正落地往往其实还是逐帧分析再做后处理。我个人看来,对视频这类有着明确时序联系的任务,或者一些具有已知物理模型的任务(如光学成像),完全可以大框架下使用已有的理论完备的模型(如本文介绍的QD),把深度学习留给难以用数学/统计学准确建模的子模块(如单帧检测)。在这个思路下,我估计AI领域会渐渐诞生出两个新的流派:【1】放弃对端到端的执念,将传统模型与深度学习结合,将深度学习作为求解器;【2】将统计模型/物理模型直接融入网络设计,端到端训练出一个带有传统模型性质的新方法。这篇工作坚决贯彻了【1】的思路,而机缘巧合,我之后一篇工作,使用了【2】的思路,有兴趣的朋友可以持续关注本专栏。参考资料[1] V. V. Veeravalli and T. Banerjee. Quickest change detection. Academic press library in signal processing: Array and statistical signal processing, 3:209–256, 2013.[2] Dong Lao and Ganesh Sundaramoorthi. Minimum Delay Object Detection From Video. Proceedings of the IEEE International Conference on Computer Vision, pp. 5097-5106. 2019.[3] Mao, Huizi, Xiaodong Yang, and William J. Dally. A delay metric for video object detection: What average precision fails to tell. Proceedings of the IEEE International Conference on Computer Vision, pp. 573-582. 2019.



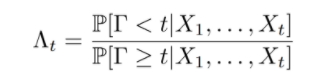
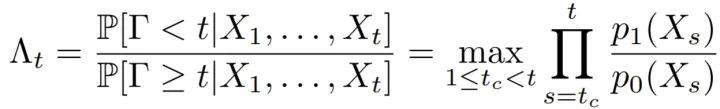

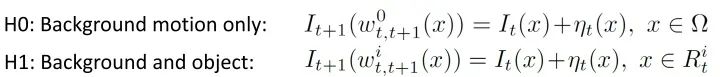
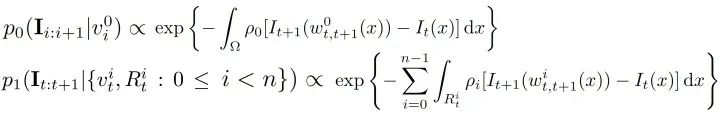
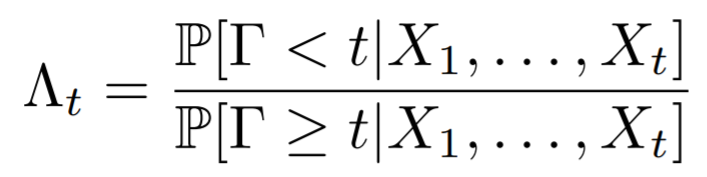

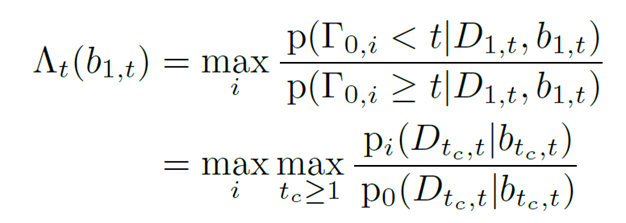
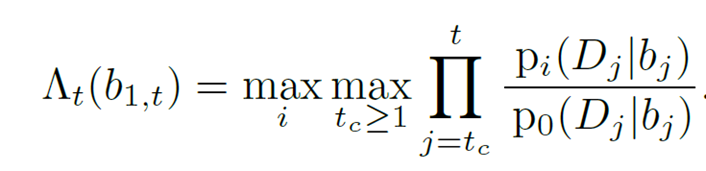
 下载APP
下载APP