
ICCV2021 论文速递 「2021.9.18」
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
ICCV 2021 论文汇总(已细分方向)
https://github.com/DWCTOD/ICCV2021-Papers-with-Code-Demo
今天分享 https://arxiv.org/ 更新的4篇ICCV 2021 的论文,主要内容包括
1、一种用于三维目标检测的端到端 Transformer 模型
2、Eformer:基于边缘增强的医学图像去噪 Transformer
3、用于车辆重识别的异构关系补码
4、DisUnknown:提取未知因素进行解耦合学习
目标检测
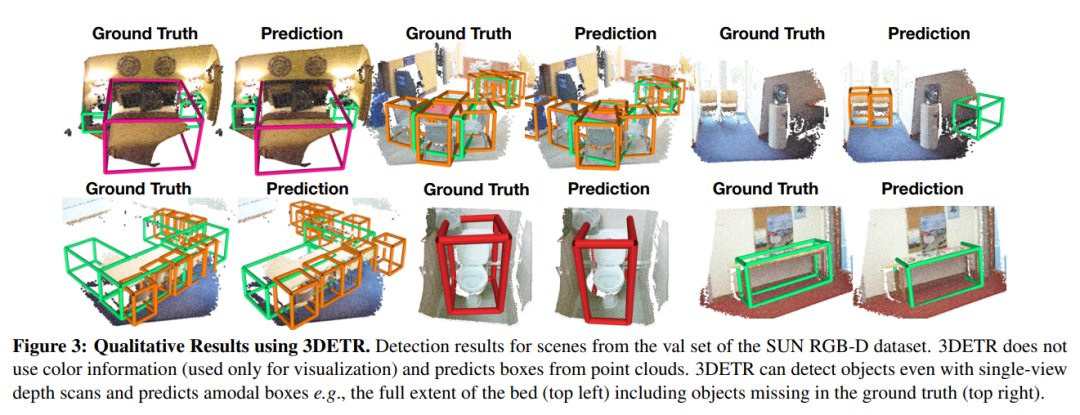
An End-to-End Transformer Model for 3D Object Detection
一种用于三维目标检测的端到端 Transformer 模型
论文:https://arxiv.org/abs/2109.08141
代码:None
我们提出了3DETR,一种基于端到端transformer的三维点云目标检测模型。与使用大量3D特定感应偏压的现有检测方法相比,3DETR只需对普通 Transformer 块进行最小修改。具体而言,我们发现,具有非参数查询和傅里叶位置嵌入的标准转换器与使用具有手动调整超参数的三维特定运算符库的专用体系结构具有竞争力。尽管如此,3DETR在概念上简单且易于实现,通过结合3D领域知识实现了进一步的改进。通过大量的实验,我们发现3DETR在具有挑战性的ScanNetV2数据集上的性能比完善且高度优化的VoteNet基线高9.5%。此外,我们还表明3DETR适用于检测不到的3D任务,可以作为未来研究的基础。
Vision Transformer
Eformer: Edge Enhancement based Transformer for Medical Image Denoising
Eformer:基于边缘增强的医学图像去噪 Transformer
论文:https://arxiv.org/abs/2109.08044
代码:None
在这项工作中,我们提出了一种基于Eformer-Edge enhancement-based transformer的新架构,该架构使用transformer块构建用于医学图像去噪的编解码网络。transformer 模块中使用了基于非重叠窗口的自我注意,减少了计算需求。这项工作进一步结合了可学习的Sobel-Feldman算子来增强图像中的边缘,并提出了一种在我们的体系结构的中间层中连接它们的有效方法。通过对比确定性学习和残差学习对医学图像去噪进行了实验分析。为了证明我们方法的有效性,我们的模型在AAPM Mayo Clinic低剂量CT大挑战数据集上进行了评估,并实现了最先进的性能,即峰值信噪比43.487,RMSE 0.0067,SSIM 0.9861。我们相信,我们的工作将鼓励更多的研究基于变压器的架构,用于使用残差学习的医学图像去噪。
Vehicle Re-identification
Heterogeneous Relational Complement for Vehicle Re-identification
用于车辆重识别的异构关系补码
论文:https://arxiv.org/abs/2109.07894
代码:None
车辆重识别中的关键问题是在从交叉摄像机查看该对象时找到相同的车辆标识,这对学习视点不变表示提出了更高的要求。在本文中,我们建议从两个方面来解决这个问题:构造健壮的特征表示和提出相机敏感评估。我们首先提出了一种新的异构关系补码网络(HRCN),该网络将特定于区域的特征和跨级别的特征作为原始高级输出的补码。考虑到分布差异和语义错位,我们提出了基于图的关系模块,将这些异构特征嵌入到一个统一的高维空间中。另一方面,考虑到现有措施(即CMC和AP)中跨摄像头评估的不足,我们提出了一种跨摄像头综合措施(CGM),通过引入位置敏感性和跨摄像头综合惩罚来改进评估。我们用我们提出的CGM进一步构建了现有模型的新基准,实验结果表明,我们提出的HRCN模型在VeRi-776、VehicleID和VeRi-Wild中达到了最新水平。
其他
DisUnknown: Distilling Unknown Factors for Disentanglement Learning
DisUnknown:提取未知因素进行解耦合学习
论文:https://arxiv.org/abs/2109.08141
代码:https://github.com/stormraiser/disunknown
将数据分解为可解释和独立的因素对于可控生成任务至关重要。有了标记数据的可用性,监督有助于按预期对特定因素进行分离。然而,为实现完全监督的解耦合,对每一个因素进行标记通常是昂贵的,甚至是不可能的。在本文中,我们采用一种通用设置,其中所有难以标记或识别的因素都封装为单个未知因素。在此背景下,我们提出了一个灵活的弱监督多因子解耦合框架disonknown,该框架提取未知因子,以实现标记因子和未知因子的多条件生成。具体而言,采用两阶段训练方法,首先使用有效且稳健的训练方法对未知因素进行解纠缠,然后使用未知蒸馏对所有标记因素进行适当解耦合,从而训练最终发生器。为了证明我们的方法的泛化能力和可扩展性,我们对多个基准数据集进行了定性和定量评估,并将其应用于复杂数据集上的各种实际应用。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
