
(附论文&代码)ICCV2021 | 首个CNN+Transformer的backbone 模型!
点击左上方蓝字关注我们


卷积运算善于提取局部特征,却不具备提取全局表征的能力。
为了感受图像全局信息,CNN必须依靠堆叠卷积层,采用池化操作来扩大感受野。
Visual Transformer的提出则打破了CNN在视觉表征方面的垄断。
得益于自注意力机制,Visual Transformer (ViT、Deit)具备了全局、动态感受野的能力,在图像识别任务上取得了更好的结果。
但是受限于的计算复杂度,Transformer需要减小输入分辨率、增大下采样步长,这造成切分patch阶段损失图像细节信息。
因此,中国科学院大学联合鹏城实验室和华为提出了Conformer基网模型,将Transformer与CNN进行了融合。
Conformer模型可以在不显著增加计算量的前提下显著提升了基网表征能力。目前,论文已被ICCV 2021接收。

论文地址:https://arxiv.org/abs/2105.03889
项目地址:https://github.com/pengzhiliang/Conformer
此外,Conformer中含有并行的CNN分支和Transformer分支,通过特征耦合模块融合局部与全局特征,目的在于不损失图像细节的同时捕捉图像全局信息。

特征图可视化
对一张背景相对复杂的图片的特征进行可视化,以此来说明Conformer捕捉局部和全局信息的能力:
浅层Transformer(DeiT)特征图(c列)相比于ResNet(a列)丢失很多细节信息,而Conformer的Transformer分支特征图(d列)更好保留了局部特征;
从深层的特征图来看,DeiT特征图(g列)相比于ResNet(e列)会保留全局的特征信息,但是噪声会更大一点;
得益于Transformer分支提供的全局特征,Conformer的CNN分支特征图(f列)会保留更加完整的特征(相比于e列);
Transformer分支特征图(h列)相比于DeiT(g列)则是保留了更多细节信息,且抑制了噪声。
网络结构
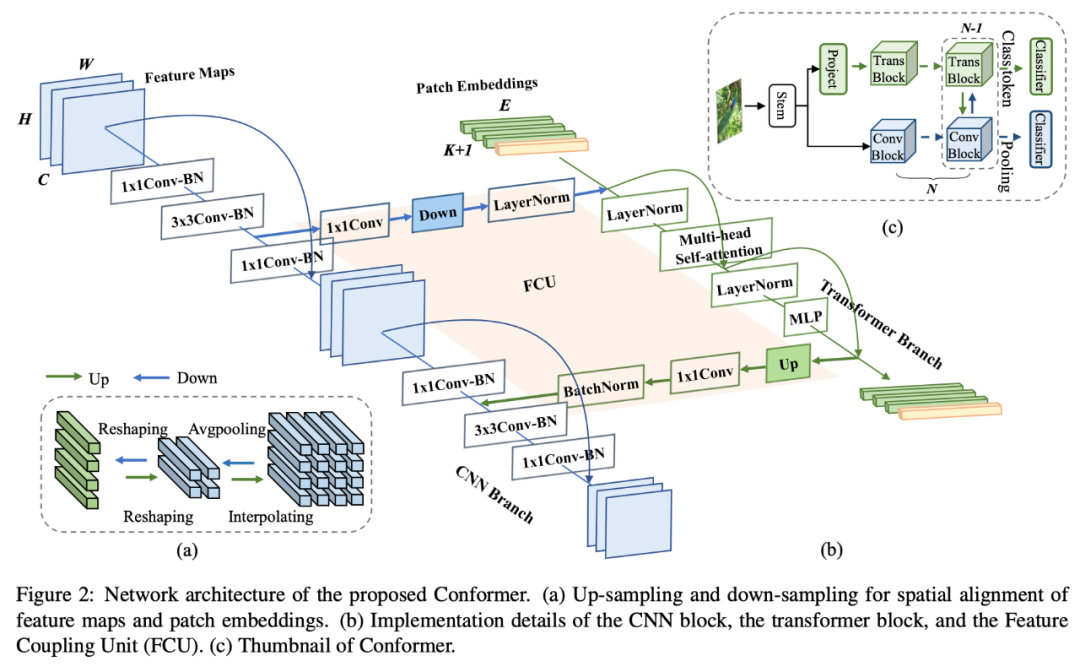
bottleneck中3x3卷积的channel比较少,使得FCU的fc层参数不会很大;
3x3卷积具有很强的位置先验信息,保证去掉位置编码后的性能。
实验结果
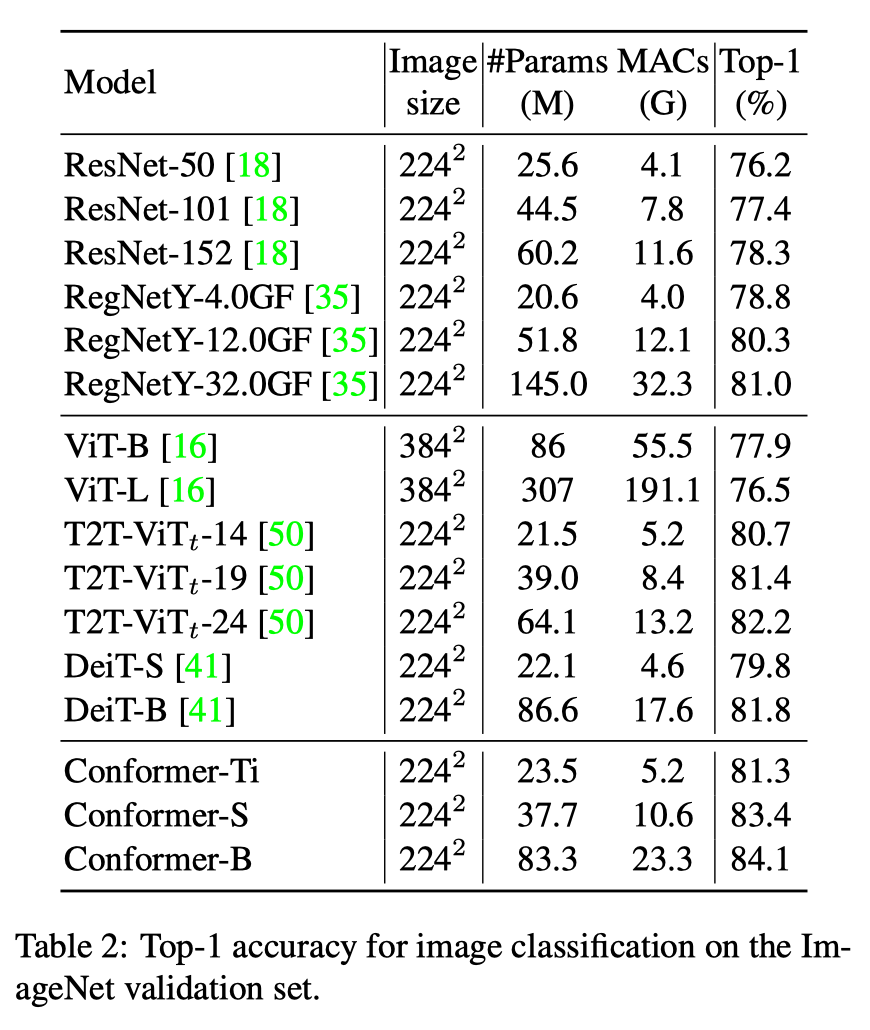
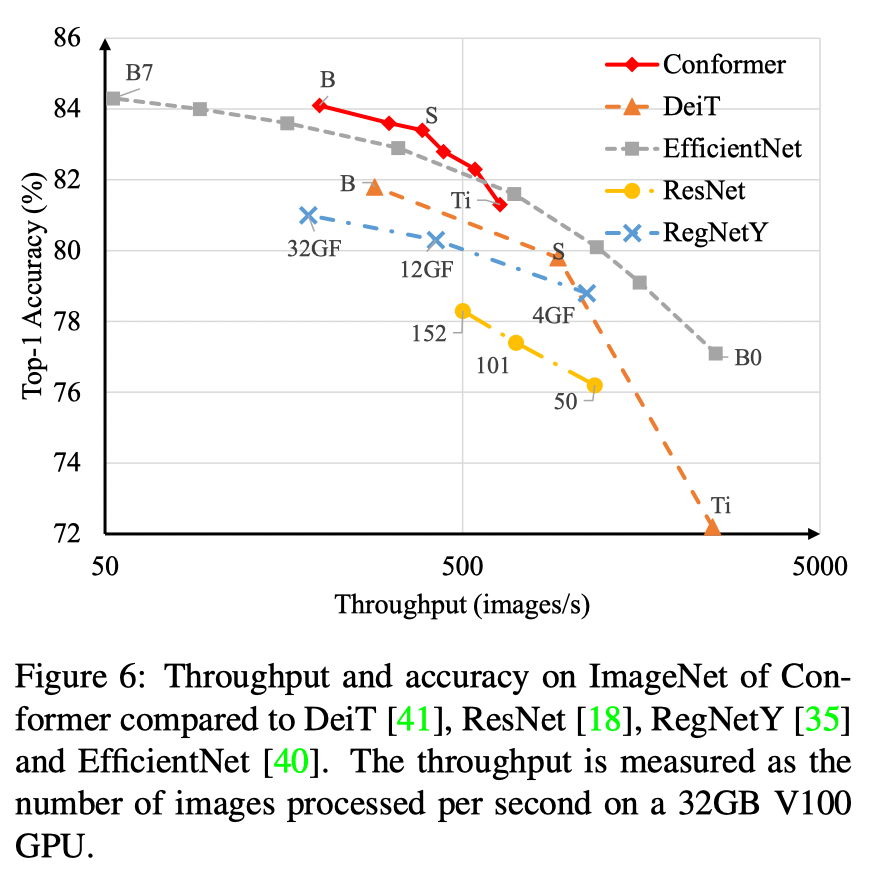
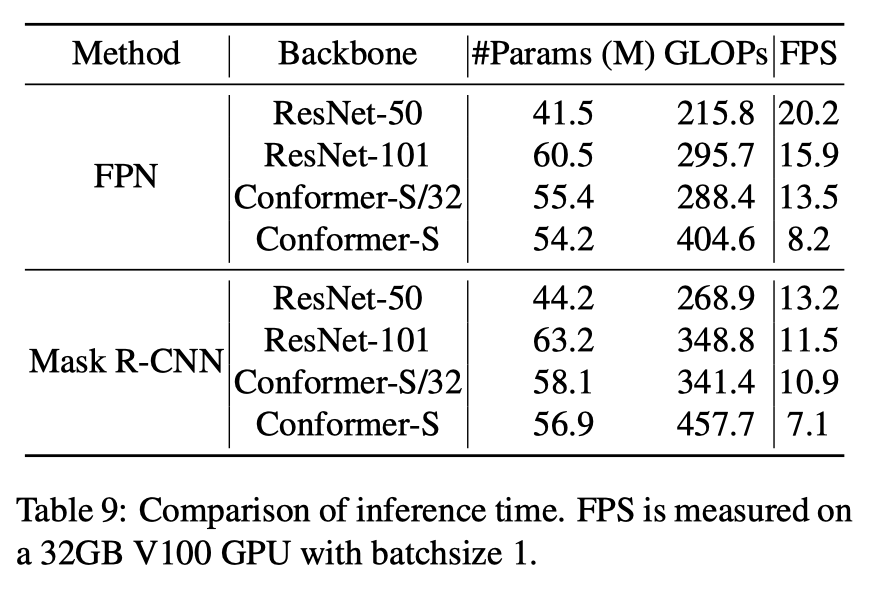
分析总结
作者介绍
参考资料:
https://arxiv.org/abs/2105.03889
END
点赞三连,支持一下吧↓