在这篇被 ICCV 2021 会议接收的论文中,来自加拿大怀雅逊大学和约克大学等机构的研究者回答了 CV 领域的一个重要问题「若在前向传递中存在全局汇聚层,那么 CNN 在表示中如何包含位置信息?」,表明具有全局平均汇聚层的 CNN 以通道方式编码位置信息。
神经网络背后的基本思想是不变(invariance),给定一个输入信号,X-invariant 作是指无论输入如何改变,都会产生相同输出。这种特性在 CV 领域是可取的,尤其是物体识别任务。一般来说,在 CV 领域中,目标是分配相应的图像级标签(例如狗),而不论物体在图像中的位置,这种现象被称为平移不变性。与平移不变密切相关的另一个特性是平移等变,即移动输入,然后通过运算传递输入,这等同于通过运算传递输入,然后移动信号。为了实现具有不变的神经网络,基本策略是在每一层的基础上使用等变(equivariant )操作,然后以不变的输出结束,其中一个最好的例子是用于图像分类的卷积神经网络(CNN)。CNN 采用具有平移等变卷积层的层次结构,使用全局汇聚层将 3D 张量转换为一维向量,然后将其输入全连接层来产生分类。因此,我们可以假设,由于进行了全局汇聚操作,对空间维度进行了折叠,在产生平移不变性的同时应删除空间信息。但是,以往的研究表明绝对位置信息不但存在于潜在表示中,也存在于网络的输出中。但是,之前的一些研究都没有回答这一关键问题:若在前向传递中存在全局汇聚层,那么 CNN 在表示中如何包含位置信息?在本文中,来自加拿大怀雅逊大学、约克大学等机构的研究者给出了这个问题的答案,并通过严格的定量实验证明,CNN 是通过沿着通道维度编码位置信息来做到这一点的,即使空间维度是折叠的也能实现。此外,该研究还表明位置信息是基于通道维度的排序进行编码的,而语义信息在很大程度上不受这种排序的影响。这些发现对于更好地理解 CNN 的特性并指导其未来设计很重要。
论文地址:https://arxiv.org/pdf/2108.07884.pdf为了证明这些发现对现实世界的影响,该研究做了以下研究:首先,该研究解决了 CNN 平移不变性问题,他们提出了一个简单而有效的损失函数,可以最小化图像编码之间的距离,以实现更高的平移不变性;
其次,该研究提出了一种有效的方法来识别潜在表示中哪些通道负责编码(i)整个图像中的位置信息和(ii)特定区域位置信息。该研究通过实验表明与随机采样的通道相比,网络在进行预测时显着依赖于通道;
最后,该研究证明了它是可能的目标区域特定的神经元,并损害图像的特定部分性能。
位置信息非常重要,有人可能会提出这样的问题:空间信息是否以某种方式被保留了下来。对于这个问题,该研究通过实验来回答。研究证明,尽管空间维度被压缩,但绝对位置信息可以在全局汇聚层之后以 1 × 1 × C 潜在表示进行 channel-wise 编码。该研究设计了两个网络架构 GAPNet、PermuteNet,如下图 1 所示。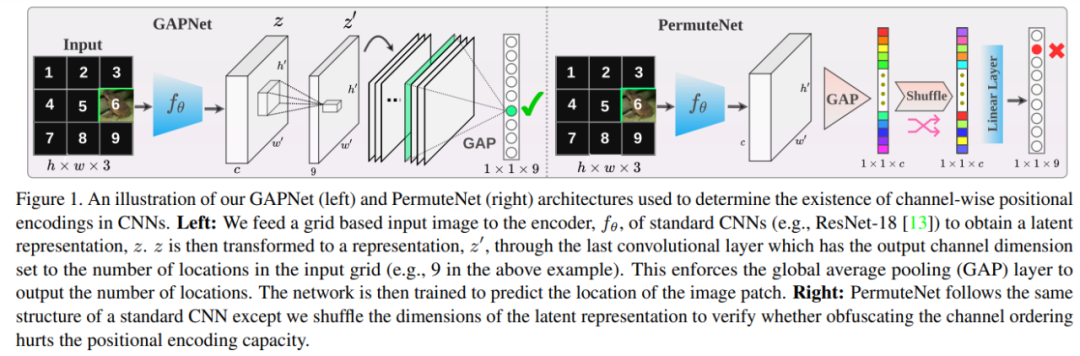
GAPNet 遵循与标准 CNN 相似的结构进行物体识别,不同的是去掉了最后的全连接层,网络的最后一层是 GAP 层。因此,GAP 层的输出将与分类 logits 的大小相同,可以用作网络的最后一层(见图 1 左)。PermuteNet 也遵循标准的目标分类网络架构,除了在 GAP 层和倒数第二个线性层之间发生的单个 shuffle 操作。此操作随机打乱 GAP 层表示的通道索引,然后将其传递给线性层进行分类(见图 1 右)。为了验证 channel-wise 位置编码的存在性,该研究使用 GAPNet 和 PermuteNet 设计了一个简单的位置依赖任务,这样输出 logits 可以直接映射到输入图像中的特定位置。该研究使用 ResNet-18 架构来报告 GAPNet 和 PermuteNet 在三种不同 padding 类型下的实验结果。对于位置分类任务,该研究以 20epoch、学习率为 0.001、ADAM 优化器来训练 GAPNet 、PermuteNet。除此以外,该研究还通过将 GAPNet 和 PermuteNet 的输出 logits 数量更改为 10,并且使用基于网格的数据设置来训练物体识别网络。对于位置相关的物体分类任务,该研究使用 100 epoch、学习率为 0.01 来训练 GAPNet、PermuteNet。表 1 给出了 GAPNet 和 PermuteNet 的位置分类和物体识别结果。对于位置分类任务,GAPNet 对所有测试的网格大小实现了 100% 准确率。很明显,GAP 层可以接受位置信息,这些信息可以直接表示输入图像的绝对位置。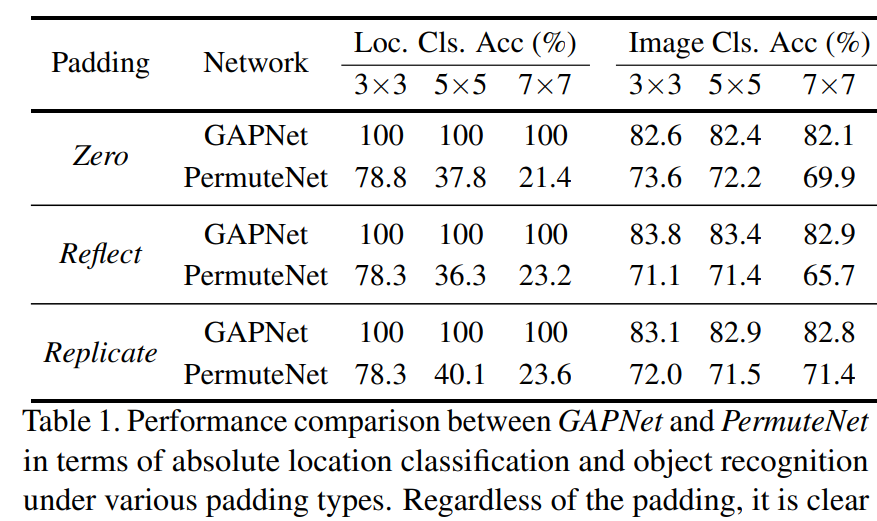
该研究进一步使用类似的数据设置来评估 GAPNet 和 PermuteNet 在图像识别任务中的表现,结果如表 1(右)所示。由结果可得与位置分类任务不同,PermuteNet 可以实现接近于 GAPNet 的分类性能。这揭示了 CNN 用于位置表示和语义表示的编码类型之间的一个有趣的二分法:位置信息主要取决于通道的顺序,而语义信息则不依赖。实验表明,GAP 层可以通过通道维度的排序来接收位置信息。为了确保 channel-wise 编码成为改进这些应用的源泉,研究者在每种情况下都等待表示通过一个 GAP 层后使用它。他们首先提出利用一个简单的损失函数来提升 CNN 中的平移不变性,然后探索目标检测网络的稳健性。研究者展示了使用隐式位置编码攻击这些模型的不同方法,以验证整体性能和区域特定的攻击效果。首先是学习平移不变表示。一个真正的移位不变性网络应能生成相同的输出 logit,而不考虑它的移位。鉴于位置信息是在输出 logit 之前的潜在表示中进行编码,因此研究者提出在同一图像不同移位之间这种表示的差异。整体训练流程如下图 2 所示: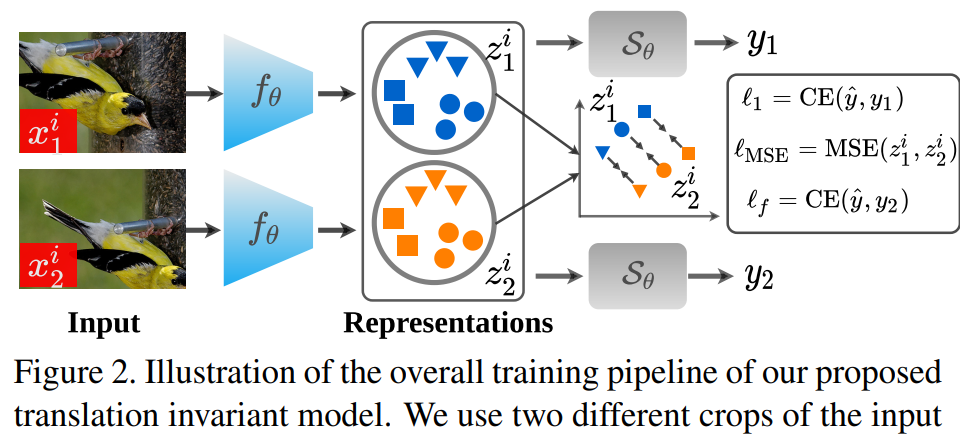
其次是移位不变性和准确率。为了验证所提出训练策略的有效性,研究者在 CIFAR-10、CIFAR-100 和 ImageNet 数据集上展示了整体性能和移位一致性结果。其中,分类和一致性结果如下表 2 所示。与基准方法(ResNet-18)相比,研究者提出的方法在 CIFAR-10 上实现了具有竞争力的 Top-1 准确率,并在移位一致性方面显著优于基准方法(94.8% VS 90.8%);在 CIFAR-100 上实现了媲美基准方法的整体分类准确率,并在移位一致性方面显著优于基准方法(85.6% VS 70.1%)。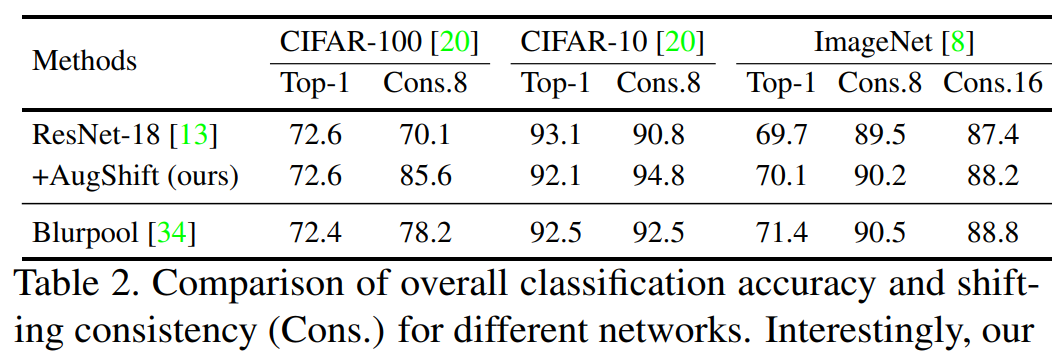
研究者的目标是证明:训练用于语义分割等位置相关任务的复杂网络非常依赖在它们的潜在表示中进行 channel-wise 编码的位置信息。为了执行这种类型的攻击,他们首先提出使用一种简单和直观的方法来估计 CNN 潜在表示中的位置编码神经元。研究者表示,与随机采样的神经元相比,移除 CNN 潜在表示中的位置编码神经元对性能会造成更大的损害。这表明,这些神经元中包含了重要的位置信息编码。他们还展示了在训练用于自动驾驶任务的网络上执行区域特定攻击的可行性。这些结果表明,channel-wise 位置编码存在于更复杂的网络中,并揭示了基于位置信息的对抗性攻击和防御具有一个有趣的发展方向。对于整体位置编码通道而言,研究者的首个目标是识别出网络潜在表示中的通道,这些通道对图像中目标的整体位置进行编码。对编码整体位置的神经元进行估计的简单和直观方法是计算水平翻转图像对的两个潜在表示的激活函数之间的绝对差。研究者首先验证 top N 个整体位置编码通道如何影响 Cityscapes 数据集上训练的 SOTA 语义分割网络 DeepLabv3-ResNet-50 的性能。下图 4 展示了当 top N 个整体位置特定通道设置为零时,DeepLabv3-ResNet-50 在 Cityscapes 数据集上的语义分割结果(以 mIoU 表示)。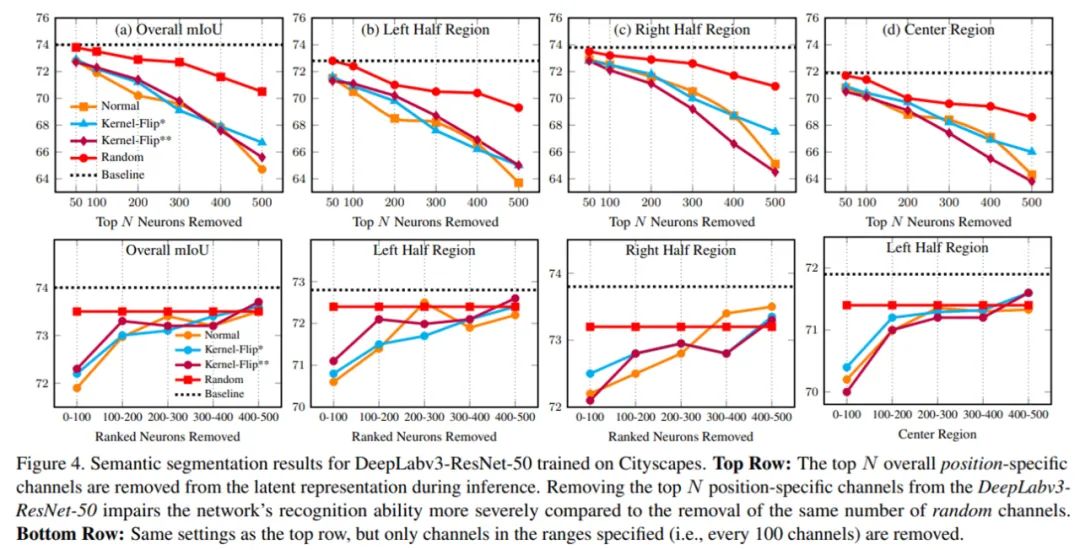
这些结果清楚地表明在进行准确的语义分割预测时,网络对潜在表示中对通道级位置编码的依赖。下图 5 展示了 Cityscapes 验证图像上移除 N 个特定神经元的的定性结果。很明显,分割质量随着 N 的增加而逐渐下降。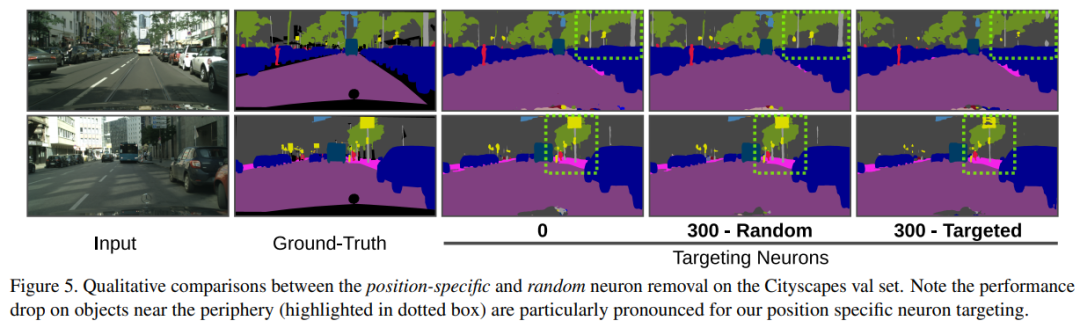
在语义分割任务上,研究者提出的证据表明,全卷积神经网络可能会损害特定输入区域的性能。下图 6 展示了验证结果(以 mIoU 表示),其中在评估期间仅考虑图像的左半部分,并且前 N 个通道设置为零。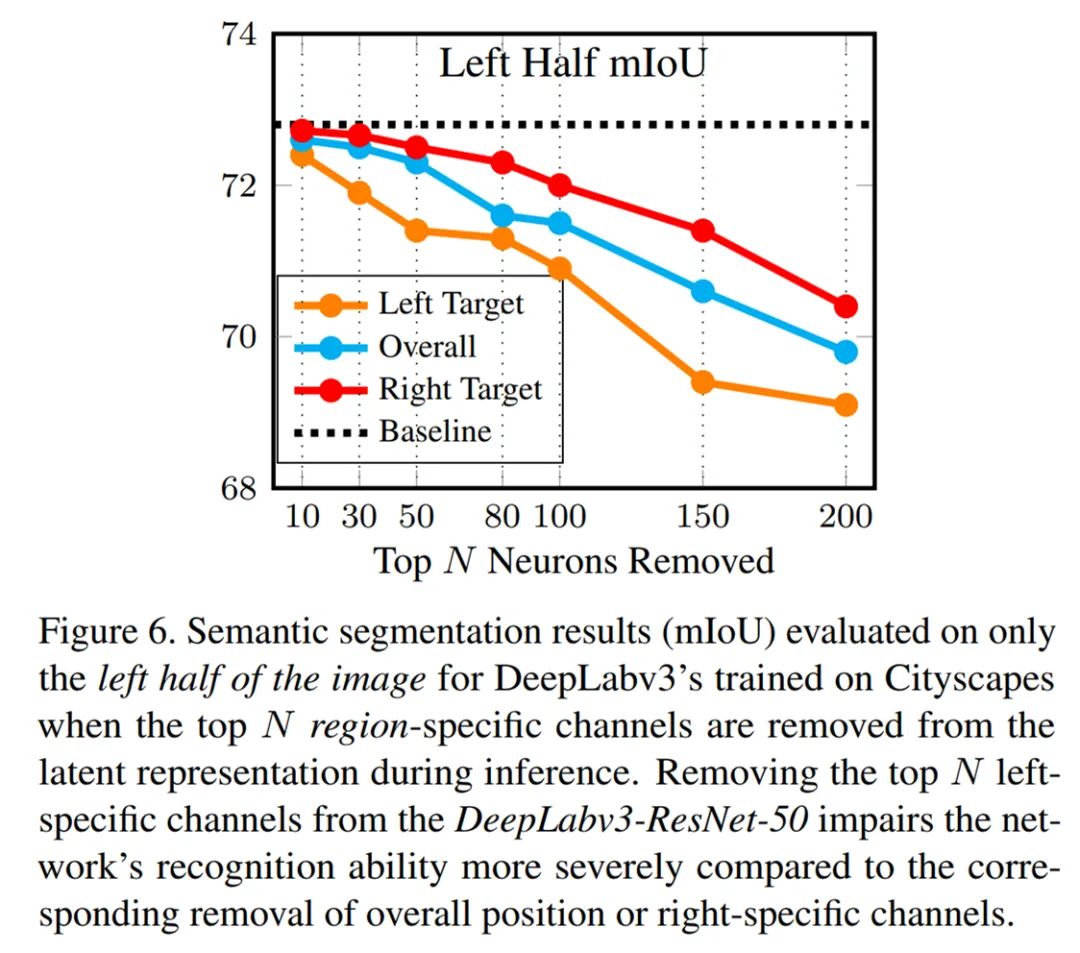
猜您喜欢:
等你着陆!【GAN生成对抗网络】知识星球!
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
CVPR 2021 | 图像转换 今如何?几篇GAN论文
【CVPR 2021】通过GAN提升人脸识别的遗留难题
CVPR 2021生成对抗网络GAN部分论文汇总
经典GAN不得不读:StyleGAN
最新最全20篇!基于 StyleGAN 改进或应用相关论文
超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 | 《Python进阶》中文版
附下载 | 经典《Think Python》中文版
附下载 | 《Pytorch模型训练实用教程》
附下载 | 最新2020李沐《动手学深度学习》
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 |《计算机视觉中的数学方法》分享
