来源:EMNLP
编辑:小咸鱼
【新智元导读】10月29日,EMNLP 2021会议公布了多个奖项:包括最佳长论文奖、最佳短论文奖、优秀论文奖和最佳Demo奖。华人学者刘方宇、杨子小帆分别是最佳长论文的一作作者和最佳短论文的一作作者。
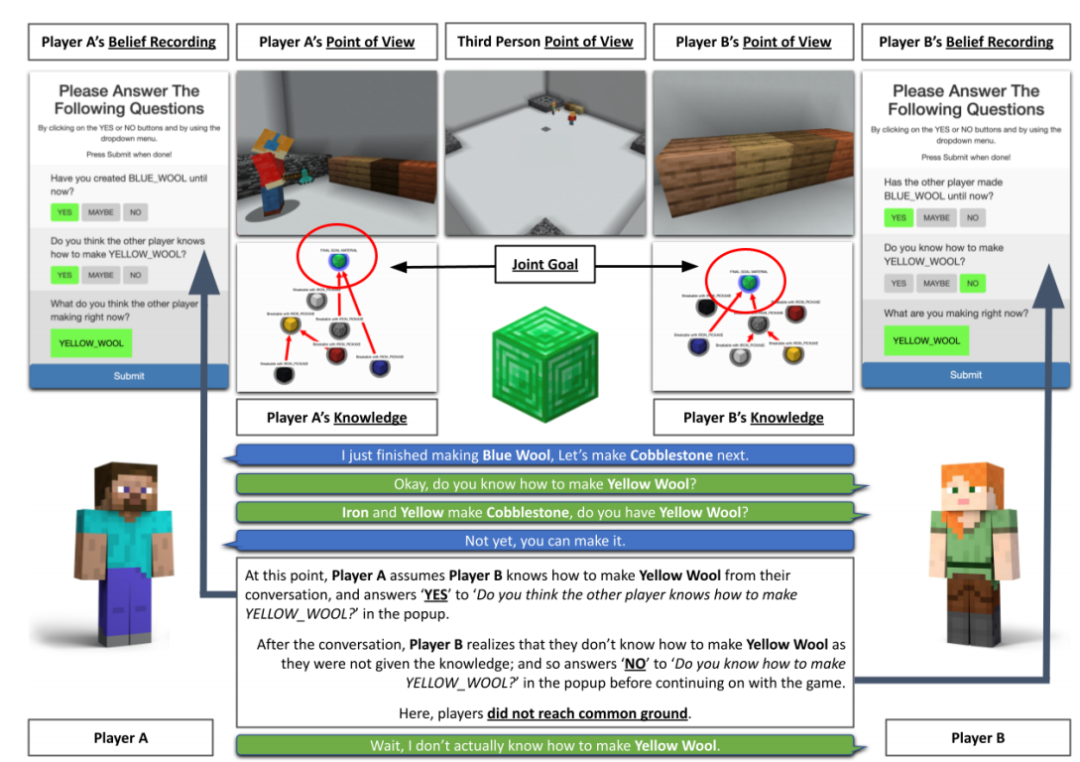
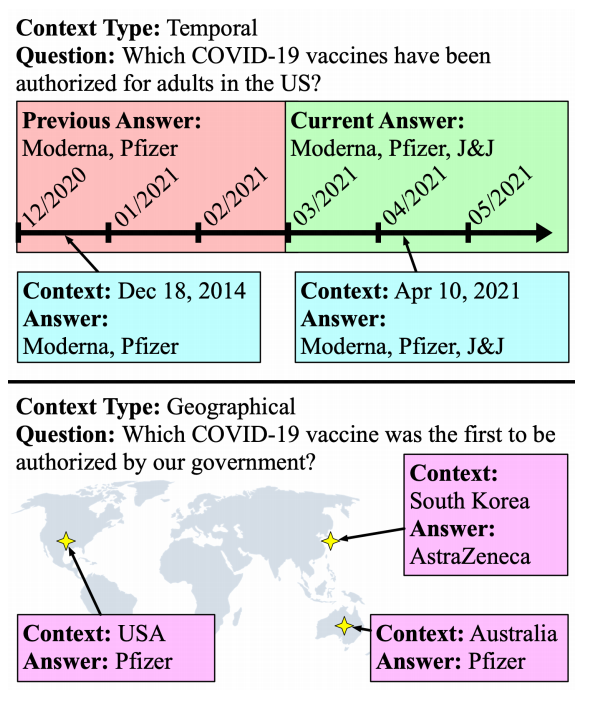
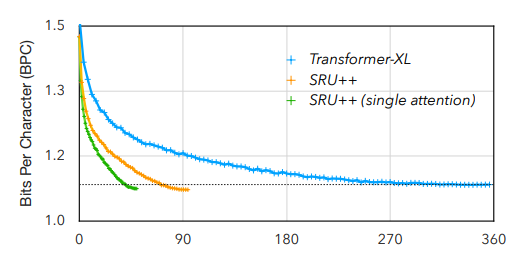
10月29日,EMNLP 2021会议公布了多个奖项:包括最佳长论文奖、最佳短论文奖、优秀论文奖和最佳Demo奖。值得欣喜的是,中国学者收获颇丰,最佳长论文的一作刘方宇和最佳短论文的一作杨子小帆都是华人学者。Visually Grounded Reasoning across Languages and Cultures论文地址:https://arxiv.org/ftp/arxiv/papers/2109/2109.13238.pdf刘方宇,本文的一作作者,2020年在滑铁卢大学取得计算语言学硕士学位,目前正在剑桥大学语言技术实验室攻读博士,现在是博士二年级,师从Nigel Collier教授。个人主页:http://fangyuliu.me/about刘方宇三个主要的研究方向是:多模态(将语言与知识和感知联系起来)、自监督(研究没有人类标签的语言模型)、可解释性(在预训练的模型权重中编码/缺失了什么?)目前,ImageNet的概念和图像被应用于很多视觉和语言数据集以及预训练编码器的设计,或者或多或少会从ImageNet中吸取灵感。但是,人们很难察觉,ImageNet基准对计算机视觉进步的贡献其实是被高估了,因为ImageNet主要都是选自于英文数据库和英文图像查询,这就会导致数据源材料带有不少北美或西欧的偏见。经验和理论分析表明,在现有的视觉语言数据集中记录的概念和图像,在许多不同于英语的语言中以及在欧洲和北美以外的文化中,可能既不突出也不是原型。为了减轻这些偏见,他们设计了一个新的注释协议,其中图像和标题的选择完全由母语人士驱动。具体来说,他们用5种不同类型的语言(印度尼西亚语、汉语普通话、斯瓦希里语、泰米尔语和土耳其语)得出描述,比较和对比图像对,建立了一个用于基础语言推理的多元文化和多语言数据集MaRVL(Multicultural Reasoning over Vision and Language)及其注释指南。研究人员使用最先进的SoTA(state-of-the-art)模型在MaRVL上测试,结果发现,与英语数据集相比,它们的表现仅仅略高于随机水平,这与MaRVL中概念、图像和语言的分布不均匀性有很大关系。这让他们有理由相信,在狭窄的语言和文化领域之外,MaRVL通常能更忠实地评估最先进的模型在现实应用中的适用性。CHoRaL: Collecting Humor Reaction Labels from Millions of Social Media Users论文解说:https://underline.io/lecture/37879-choral-collecting-humor-reaction-labels-from-millions-of-social-media-users本文一作杨子小帆是苹果公司的研究科学家。她最近在Julia Hirschberg教授的指导下完成了哥伦比亚大学的博士学位。她的研究兴趣集中在计算副语言学和跨语言自然语言处理。此前,她在北京大学获得计算机科学学士学位和经济学学士学位。近年来,由于用户生成的具有比喻性语言的内容越来越多,理解幽默这一领域受到了越来越多的重视。然而,在幽默的感知上,个体和文化差距让具有可靠的幽默标签的大规模「幽默」数据集变得非常难收集。研究人员提出了CHoRaL,这是一个使用自然用户对帖子的反应,而不需要手动注释,就可以在Facebook帖子上生成感知幽默标签的框架。他们在与新冠肺炎相关的785000篇帖子上收集到了迄今为止最大的带有幽默标签的数据集。此外,要分析与COVID相关的幽默在社交媒体中的表达时,通过从Facebook帖子中提取词汇语义和情感特征,他们构建了与人类相仿的幽默检测模型。CHoRaL使任何话题的大规模幽默检测模型的开发成为可能,并开辟了社交媒体上的幽默研究这一道路。论文1:MindCraft:Theory of Mind Modeling for Situated Dialogue in Collaborative Tasks论文地址:https://arxiv.org/pdf/2109.06275.pdf在现实世界与物理代理的协作场景中,人类和代理将不可避免地在能力、知识和对共享世界的理解上存在差异。这项工作引入了一个新的数据集和实验框架,支持对协作任务中情境对话的思维建模理论的深入研究。通过在协作交互过程中自我报告信念状态的新颖实现,他们的数据集一步一步地跟踪合作伙伴对手头任务的信念以及彼此的信念,并捕获他们的精神状态如何演变。这是情境对话环境中的第一个数据集,它为心智建模提供了细粒度的信息。他们对这个数据集的初步分析产生了几个有趣的发现,这些发现将为各种问题的计算模型的开发提供信息。例如,在跟踪心理模型和管理协作代理中的对话行为方面。他们的基线结果表明,在一个共享的环境中,交互对话和视觉体验对于预测手头任务的相互信念状态以及与合作伙伴确保共同点的重要性。论文2:SituatedQA:Incorporating Extra-Linguistic Contexts into QA论文地址:https://arxiv.org/pdf/2109.06157.pdf该工作首次研究了语言外语境(例如时间地点)是如何影响开放检索问答的。他们的研究表明,当前的系统无法适应时间或地理环境的变化。因此,他们创建了一个数据集SituatedQA,用于训练和评估质量保证系统,这就要求系统必须在具体的时间和地点等语境下,生成正确答案,以此获得对事实在不同环境中变化的建模能力。他们的数据集将支持未来开发模型的大量工作,这些模型可以基于新的时间和地理环境优雅地更新其预测。未来的研究可能涉及整合时间和地理相关的源文档,如新闻文章,或考虑其他语言外的背景,如谁在提问,同时考虑个人的偏好。论文3:When Attention Meets Fast Recurrence:Training Language Models with Reduced Compute 论文地址:https://arxiv.org/pdf/2102.12459.pdf该文提出了一种结合快速循环和自注意力的高效架构SRU++,并在各种语言建模数据集上对SRU++进行评估,包括ENWIK8、WIKI-103和BILLION WORD数据集。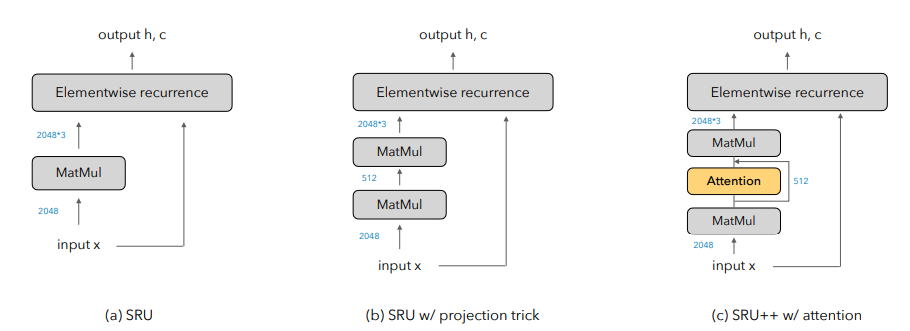 SRU和SRU++网络示例
SRU和SRU++网络示例
SRU++在这些数据集上始终优于各种Transformer模型,提供了更好或不相上下的结果,同时使用的计算量减少了3-10倍,因为他们的模型不使用位置编码、多头注意力和其他对Transformer模型有用的技术。SRU++通过使用1/8的训练时长获得了更好的BPC此外,他们证明了对于SRU++来说,几个注意力层足以获得接近最先进的性能。这些结果不仅突出了循环的有效性,而且表明其能够在训练和推理中大大减少计算量。论文4:Shortcutted Commonsense: Data Spuriousness in Deep Learning of Commonsense ReasoningGitHub地址:https://github.com/nlx-group/Shortcutted-Commonsense-Reasoning自人工智能诞生以来,常识,这一典型的人类基本能力,一直是人工智能的核心挑战。Transformer在自然语言处理任务(包括常识推理)中取得了非常令人兴奋的结果,甚至在某些基准测试中匹配或超过了人类的表现。不过最近,Transformer的进步受到了一些质疑,那是因为训练数据中的伪影已经明显表现出来,在某些情况下,Transformer正在利用这些虚假的相关性和肤浅的捷径达到更优的性能。在本文中,他们进一步分析了与常识相关的语言处理任务领域,对涉及常识推理的不同突出基准进行了研究,从而寻求深入了解模型是在学习问题根本的可迁移信息,还是只是利用数据项中的捷径。而所获得的结果表明,大多数实验数据集都是有问题的,因为模型依赖了非鲁棒特征,并且没有学习和概括数据集想要传达或举例说明的东西。Datasets: A Community Library for Natural Language Processing论文地址:https://arxiv.org/pdf/2109.02846.pdfHugging Face Datasets是一个开源的、社区驱动的库,它将自然语言处理数据集的处理、分发和文档标准化。核心库设计为易于使用、快速,并且对不同大小的数据集使用相同的界面。来自超过250个贡献者的650个数据集,使Hugging Face Datasets易于使用标准数据集,促进了跨数据集自然语言处理的新用例,并具有索引和流式传输大型数据集等任务的高级功能。
参考资料:
https://2021.emnlp.org/blog/2021-10-29-best-paper-awards/