
(附代码)CVPR 2021大奖公布!何恺明获最佳论文提名
点击左上方蓝字关注我们

推特上,有学者打趣说,CV论文可以分为这几类:「只想混文凭」、「教电脑生成更多猫的照片」、「ImageNet上实验结果提升0.1%!」、「手握超酷数据集但并不打算公开」、「3年过去了,代码仍在赶来的路上」、「实验证明还是老baseline性能更牛」、「我们的数据集更大!」、「研究范围超广,无他,我们有钱」、「花钱多,结果好」......
仅为调侃,请勿对号入座。

图源:Jia-Bin Huang的推特
不过,言归正传,让我们来看看今年被CVPR选中的都有哪些幸运论文。
2021 CVPR 论文奖
最佳论文奖(Best Paper)
今年的最佳论文是马克斯·普朗克智能系统研究所和蒂宾根大学团队的Michael Niemeyer, Andreas Geiger,他们的论文是
《GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields》(GIRAFFE:将场景表现为组合生成的神经特征场)

论文 https://m-niemeyer.github.io/project-pages/giraffe/index.html
源码 https://github.com/autonomousvision/giraffe
论文简介:
深度生成模型可以在高分辨率下进行逼真的图像合成。但对于许多应用来说,这还不够:内容创作还需要可控。虽然最近有几项工作研究了如何分解数据中的潜在变化因素,但它们大多在二维中操作,忽略了我们的世界是三维的。此外,只有少数作品考虑到了场景的组成性质。我们的关键假设是,将组合式三维场景表示纳入生成模型,可以使图像合成更加可控。将场景表示为生成性神经特征场,使我们能够从背景中分离出一个或多个物体,以及单个物体的形状和外观,同时无需任何额外的监督就能从非结构化和unposed的图像集中学习。将这种场景表示与神经渲染管道结合起来,可以产生一个快速而真实的图像合成模型。正如我们的实验所证明的那样,我们的模型能够分解单个物体,并允许在场景中平移和旋转它们,还可以改变摄像机的姿势。
最佳论文荣誉提名(Best Paper Honorable Mentions)
何恺明和Xinlei Chen的论文《Exploring Simple Siamese Representation Learning》(探索简单的连体表征学习)获得了最佳论文提名。


https://arxiv.org/abs/2011.10566
论文主要研究了:
「连体网络」(Siamese networks)已经成为最近各种无监督视觉表征学习模型中的一种常见结构。这些模型最大限度地提高了一个图像的两个增量之间的相似性,但必须符合某些条件以避免collapse的解决方案。在本文中,我们报告了令人惊讶的经验结果,即简单的连体网络即使不使用以下任何一种情况也能学习有意义的表征。(i) 负样本对,(ii) 大batch,(iii) 动量编码器。我们的实验表明,对于损失和结构来说,collapse的解决方案确实存在,但stop-gradient操作在防止collapse方面发挥了重要作用。我们提供了一个关于stop-gradient含义的假设,并进一步展示了验证该假设的概念验证实验。我们的 「SimSiam 」方法在ImageNet和下游任务中取得了有竞争力的结果。我们希望这个简单的基线能促使人们重新思考连体结构在无监督表征学习中的作用。
代码已开源 https://github.com/facebookresearch/simsiam

另一篇最佳论文提名是明尼苏达大学团队Yasamin Jafarian, Hyun Soo Park的
《Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos》

学习穿戴人体几何的一个关键挑战在 ground truth 实数据(如三维扫描模型)的有限可用性,这导致三维人体重建在应用于真实图像时性的能下降本文们通过利用一个新的数据资源来应对这一挑战:大量社交媒跳舞蹈视——,涵盖了不同的外观、服装风格、表演和身份。每一个视频都描述了一个人的身体和衣服的动态运动,但缺乏3 ground truth实几何图形.
为了很好地利用这些视频,本文提出了一种新的方法来使用局部变换,即将预测的局部几何体从一幅图像在不同的时刻扭曲到另一幅图像。这使得自监督学习对预测实施时间一致性。此外,我们还通过最大化局部纹理、褶皱和阴影的几何一致性,共同学习深度以及对局部纹理、褶皱和阴影高度敏感的曲面法线。
另外本文的方法是端到端可训练的,能产生高保真深度估计来预测接近于输入的真实图像的精确几何。本文证明了我们提出的方法在真实图像和渲染图像上都优于 SOTA 人体深度估计和人体形状恢复方法。
最佳学生论文奖(Best Student Paper)

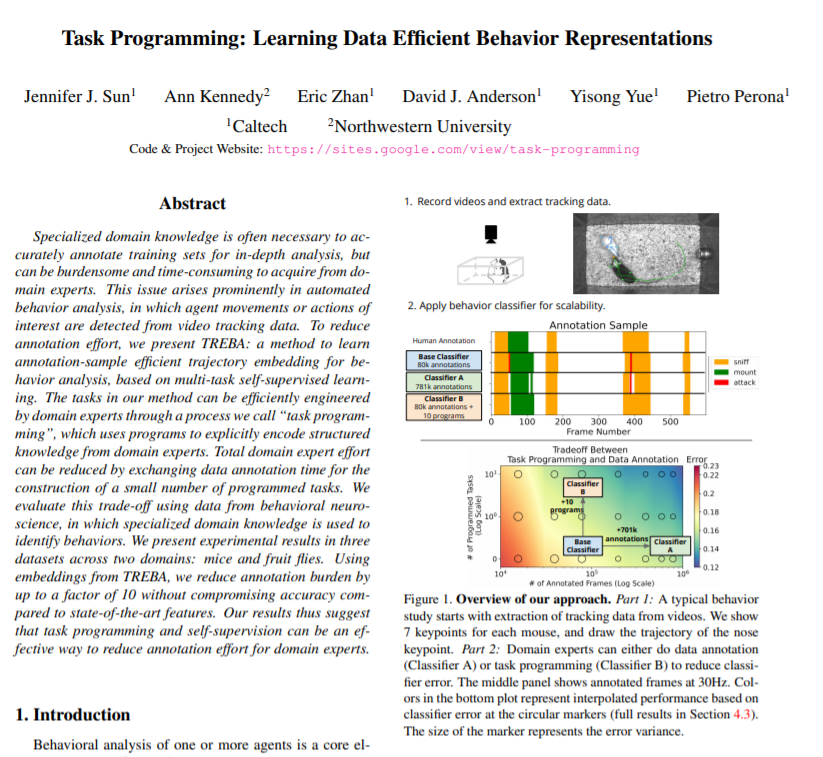
https://openaccess.thecvf.com/content/CVPR2021/html/Sun_Task_Programming_Learning_Data_Efficient_Behavior_Representations_CVPR_2021_paper.html
为了更准确的标注数据集,具备该领域的专业知识是必要的,但这可能意味专家们将承担大量繁重和耗时的工作。这个问题在自动行为分析(automated behavior analysis)中尤为突显。例如,从视频跟踪数据中检测智能体运动或动作。
为了减少注释的工作量,我们基于多任务自监督学习,提出了一种用于行为分析的有效轨迹嵌入方法—TREBA。利用该方法专家们可以通过“任务编程”过程来有效地设计任务,即使用程序编码将领域专家的知识结构化。通过交换数据注释时间来构造少量编程任务,可以减少领域专家的工作量。我们使用行为神经科学领域的数据集评估了该方法,通过小鼠和果蝇两个领域内三个数据集的测试,实验结果表明:通过使用TREBA的嵌入,注释负担减少了10倍。该研究结果表明,任务规划和自监督是减少领域专家注释工作量的有效方法。
最佳学生论文荣誉提名(Best Student Paper Honorable Mentions)
获得「最佳学生论文」提名的有三篇

1.《Less is More: ClipBERT for Video-and-Language Learning via Sparse Sampling》(少即是多:通过稀疏取样进行视频和语言学习的ClipBERT)
作者团队来自北卡罗来纳大学教堂山分校和Microsoft Dynamics 365 AI Research的Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L. Berg, Mohit Bansal, Jingjing Liu

https://openaccess.thecvf.com/content/CVPR2021/html/Lei_Less_Is_More_ClipBERT_for_Video-and-Language_Learning_via_Sparse_Sampling_CVPR_2021_paper.html

2. 《Binary TTC: A Temporal Geofence for Autonomous Navigation》(二进制TTC:用于自主导航的时间地理围栏)
作者团队来自英伟达和加州大学圣巴巴拉分校的Abhishek Badki, Orazio Gallo, Jan Kautz, Pradeep Sen

https://openaccess.thecvf.com/content/CVPR2021/html/Badki_Binary_TTC_A_Temporal_Geofence_for_Autonomous_Navigation_CVPR_2021_paper.html
3. 《Real-Time High-Resolution Background Matting》(实时高分辨率的背景消隐)
作者团队来自华盛顿大学的Shanchuan Lin, Andrey Ryabtsev, Soumyadip Sengupta, Brian Curless, Steve Seitz, Ira Kemelmacher-Shlizerman

https://openaccess.thecvf.com/content/CVPR2021/papers/Lin_Real-Time_High-Resolution_Background_Matting_CVPR_2021_paper.pdf
最佳论文评选委员会
以上最佳(学生)论文及提名由以下委员会评选:Deva Ramanan (主席),Lourdes Agapito, Zeynep Akata, Karteek Alahari, Xilin Chen, Emily Denton, Piotr Dollar, Ivan Laptev, Kyoung Mu Lee
其中,中科院计算所视觉信息处理与学习组的陈熙霖博士是委员会成员。

陈熙霖博士,研究员,ACM Fellow, IEEE Fellow, IAPR Fellow, 中国计算机学会会士,国家杰出青年基金获得者。主要研究领域为计算机视觉、模式识别、多媒体技术以及多模式人机接口。先后主持多项自然科学基金重大、重点项目、973计划课题等项目的研究。
曾任IEEE Trans. on Image Processing和IEEE Trans. on Multimedia的Associate Editor,目前是Journal of Visual Communication and Image Representation的Associate Editor、计算机学报副主编、人工智能与模式识别副主编,担任过FG2013 / FG 2018 General Chair以及CVPR 2017 / 2019 / 2020, ICCV 2019等的Area Chair。
陈熙霖博士先后获得国家自然科学二等奖1项,国家科技进步二等奖4项,省部级科技进步奖九项。合作出版专著1本,在国内外重要刊物和会议上发表论文200多篇。
PAMITC 奖(PAMITC AWARDS)
Longuet-Higgins 奖是 IEEE 计算机协会模式分析与机器智能(PAMI)技术委员会在每年的 CVPR 颁发的计算机视觉基础贡献奖,表彰十年前对计算机视觉研究产生了重大影响的 CVPR 论文。该奖项以理论化学家和认知科学家 H. Christopher Longuet-Higgins 命名。
第一篇论文获奖论文是“Real-Time Human Pose Recognition in Parts from Single Depth Images”,发表于CVPR 2011,目前引用数4108,来自微软。

这篇论文提出了一种新方法,可以在不使用时间信息的情况下,从单张深度图像中快速准确地预测身体关节的 3D 位置。
研究人员采用目标识别方法,设计一个中间的身体部位表示步骤,将困难的姿势估计问题映射到更简单的每像素分类问题。庞大且高度多样化的训练数据集允许分类器估计对姿势、体型、服装等保持不变的身体部位。最后,研究人员通过重新投影分类结果并找到局部模式来生成几个身体关节的置信度评分 3D 建议。该系统在消费级硬件上以每秒 200 帧的速度运行。
这项工作在当时的相关研究中实现了最先进的准确率,并展示了对精确整个骨架最近邻匹配的改进泛化。
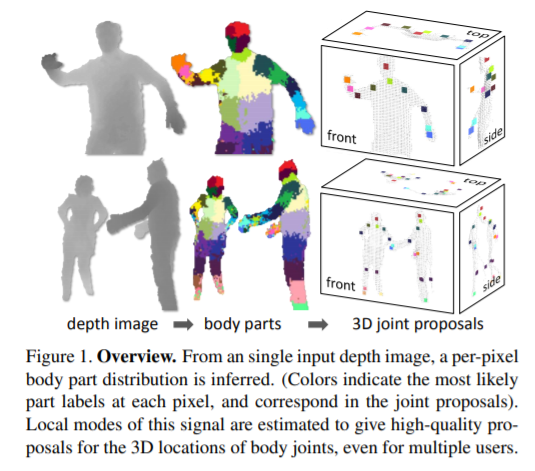
论文链接:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/BodyPartRecognition.pdf
第二篇获奖论文是“Baby Talk: Understanding and Generating Simple Image Descriptions“,发表于CVPR 2011,目前引用数1159,来自石溪大学。

这篇论文假设视觉描述语言为计算机视觉研究人员提供了关于世界的信息,以及关于人们如何描述世界的信息。
基于大量语言数据,研究人员提出了一个从图像自动生成自然语言描述的系统,该系统利用从解析大量文本数据和计算机视觉识别算法中收集的统计数据。该系统在为图像生成相关句子方面非常有效,是早期图像到文本生成的重要工作。

论文链接:http://acberg.com/papers/baby_talk.pdf
去年,为了缅怀了一代 CV 宗师、84 岁华人计算机视觉泰斗 Thomas S. Huang(黄煦涛),CVPR大会成立了 Thomas S. Huang 纪念奖,该奖项的获奖者将由 PAMITC 奖励委员会选出,类似于罗森菲尔德奖获奖者将并得到相同的奖金。
黄煦涛先生在华人计算机界被誉为「计算机视觉之父」,他在图像处理、模式识别等计算机视觉领域作出了开创性贡献,为中国培养了许多杰出人才,是华人计算机视觉领域的一座灯塔。此外,他也是首位担任CVPR程序主席(1992)的华人。

今年也就是第一届Thomas S. Huang 纪念奖的获奖者,是MIT电子电气工程与计算机科学教授Antonio Torralba。
Antonio Torralba的研究领域包括场景理解和上下文驱动的目标识别、多感官知觉整合、数据集构建以及神经网络表征的可视化和解释。他目前的论文引用数为78736,h指数为111。
个人主页:https://groups.csail.mit.edu/vision/torralbalab/

青年研究者奖(Young Researcher Awards)
青年研究者奖的目的在于表彰年轻的科学家,鼓励继续做出开创性的工作。另外,此奖项的评选标准是研究者必须获得博士学位的年限少于7年。
今年获奖的两位学者分别是来自FAIR和MIT的科学家。


Georgia Gkioxari是 FAIR 研究科学家。她在加州大学伯克利分校获得博士学位,导师是 Jitendra Malik 。她是PyTorch3D的开发者之一,主要研究领域是计算机视觉,并且是Mask R-CNN的作者之一(与何恺明合作),目前引用数为16000。

个人主页:https://gkioxari.github.io/
Phillip Isola是麻省理工学院 EECS 的助理教授,主要研究计算机视觉、机器学习和人工智能。
他曾在 OpenAI 做了一年的访问研究科学家,在此之前,他是加州大学伯克利分校 EECS 系的 Alyosha Efros 的博士后学者。他在 MIT 的大脑与认知科学专业完成了博士学位,导师是Ted Adelson 。他目前论文引用数为28056,其中引用最高的论文为“Image-to-image translation with conditional adversarial networks”(与朱俊彦合作),这篇论文研究了条件形式的图像到图像转换,可以说是CycleGAN的前阶段工作。

个人主页:http://web.mit.edu/phillipi/
该年度奖项旨在表彰对计算机视觉做出杰出研究贡献的年轻研究人员。
本届委员会:R. Zabih (主席), S. Lazebnik, G. Medioni, N. Paragios, S. Seitz
END
整理不易,点赞三连↓