
深度学习相关面试题

向AI转型的程序员都关注了这个号???
人工智能大数据与深度学习 公众号:datayx
1.CNN的特点以及优势
改变全连接为局部连接,这是由于图片的特殊性造成的(图像的一部分的统计特性与其他部分是一样的),通过局部连接和参数共享大范围的减少参数值。可以通过使用多个filter来提取图片的不同特征(多卷积核)。
CNN使用范围是具有局部空间相关性的数据,比如图像,自然语言,语音
1.局部连接:可以提取局部特征。
2.权值共享:减少参数数量,因此降低训练难度(空间、时间消耗都少了)。
3.可以完全共享,也可以局部共享(比如对人脸,眼睛鼻子嘴由于位置和样式相对固定,可以用和脸部不一样的卷积核)
4.降维:通过池化或卷积stride实现。
5.多层次结构:将低层次的局部特征组合成为较高层次的特征。不同层级的特征可以对应不同任务。
2.deconv的作用
1.unsupervised learning:重构图像
2.CNN可视化:将conv中得到的feature map还原到像素空间,来观察特定的feature map对哪些pattern的图片敏感
3.Upsampling:上采样。
3.dropout作用以及实现机制 (参考:https://blog.csdn.net/nini_coded/article/details/79302800)
1.dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,
对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
2.dropout是一种CNN训练过程中防止过拟合提高效果的方法
3.dropout带来的缺点是可能减慢收敛速度:由于每次迭代只有一部分参数更新,可能导致梯度下降变慢
4.测试时,需要每个权值乘以P
4.深度学习中有什么加快收敛/降低训练难度的方法:
1.瓶颈结构
2.残差
3.学习率、步长、动量
4.优化方法
5.预训练
5.什么造成过拟合,如何防止过拟合
1.data agumentation
2.early stop
3.参数规则化
4.用更简单模型
5.dropout
6.加噪声
7.预训练网络freeze某几层
6.LSTM防止梯度弥散和爆炸
LSTM用加和的方式取代了乘积,使得很难出现梯度弥散。但是相应的更大的几率会出现梯度爆炸,但是可以通过给梯度加门限解决这一问题
7.为什么很多做人脸的Paper会最后加入一个Local Connected Conv?
在一些研究成果中,作者通过实验表明:人脸在不同的区域存在不同的特征(眼睛/鼻子/嘴的分布位置相对固定),当不存在全局的局部特征分布时,Local-Conv更适合特征的提取。
8.神经网络权值初始化方式以及不同方式的区别?
权值初始化的方法主要有:常量初始化(constant)、高斯分布初始化(gaussian)、positive_unitball初始化、均匀分布初始化(uniform)、xavier初始化、msra初始化、双线性初始化(bilinear)
9.Convolution、 pooling、 Normalization是卷积神经网络中十分重要的三个步骤,分别简述Convolution、 pooling和Normalization在卷积神经网络中的作用。
10.dilated conv(空洞卷积)优缺点以及应用场景
基于FCN的语义分割问题中,需保持输入图像与输出特征图的size相同。
若使用池化层,则降低了特征图size,需在高层阶段使用上采样,由于池化会损失信息,所以此方法会影响导致精度降低;
若使用较小的卷积核尺寸,虽可以实现输入输出特征图的size相同,但输出特征图的各个节点感受野小;
若使用较大的卷积核尺寸,由于需增加特征图通道数,此方法会导致计算量较大;
所以,引入空洞卷积(dilatedconvolution),在卷积后的特征图上进行0填充扩大特征图size,这样既因为有卷积核增大感受野,也因为0填充保持计算点不变。
11.判别模型和生成模型解释
监督学习方法又分生成方法(Generative approach)和判别方法(Discriminative approach),所学到的模型分别称为生成模型(Generative Model)和判别模型(Discriminative Model)。
从概率分布的角度考虑,对于一堆样本数据,每个均有特征Xi对应分类标记yi。
生成模型:学习得到联合概率分布P(x,y),即特征x和标记y共同出现的概率,然后求条件概率分布。能够学习到数据生成的机制。
判别模型:学习得到条件概率分布P(y|x),即在特征x出现的情况下标记y出现的概率。
数据要求:生成模型需要的数据量比较大,能够较好地估计概率密度;而判别模型对数据样本量的要求没有那么多。
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
12.如何判断是否收敛
13.正则化方法以及特点
正则化方法包括:L1 regularization 、 L2 regularization 、 数据集扩增 、 dropout 等
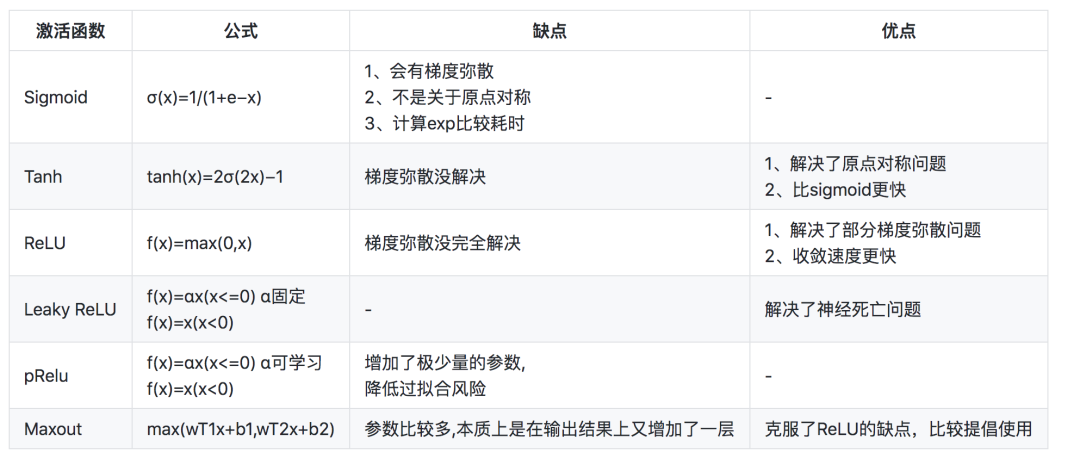
14.常用的激活函数 (参考:https://blog.csdn.net/Yshihui/article/details/80540070)
15.1x1卷积的作用
1. 实现跨通道的信息交互和整合。1x1卷积核只有一个参数,当它作用在多通道的feature map上时,相当于不同通道上的一个线性组合,
实际上就是加起来再乘以一个系数,但是这样输出的feature map就是多个通道的整合信息了,能够使网络提取的特征更加丰富。
2. feature map通道数上的降维。降维这个作用在GoogLeNet和ResNet能够很好的体现。举个例子:假设输入的特征维度为100x100x128,
卷积核大小为5x5(stride=1,padding=2),通道数为256,则经过卷积后输出的特征维度为100x100x256,卷积参数量为
128x5x5x256=819200。此时在5x5卷积前使用一个64通道的1x1卷积,最终的输出特征维度依然是100x100x256,但是此时的卷积参数
量为128x1x1x64 + 64x5x5x256=417792,大约减少一半的参数量。
3. 增加非线性映射次数。1x1卷积后通常加一个非线性激活函数,使网络提取更加具有判别信息的特征,同时网络也能做的越来越深。
16.无监督学习方法有哪些
强化学习、K-means 聚类、自编码、受限波尔兹曼机
17.增大感受野的方法?
空洞卷积、池化操作、较大卷积核尺寸的卷积操作
18.目标检测领域的常见算法?
1.两阶段检测器:R-CNN、Fast R-CNN、Faster R-CNN
2.单阶段检测器:YOLO、YOLO9000、SSD、DSSD、RetinaNet
19.回归问题的评价指标
1.平均绝对值误差(MAE)
2.均方差(MSE)
20.卷积层和全连接层的区别
1.卷积层是局部连接,所以提取的是局部信息;全连接层是全局连接,所以提取的是全局信息;
2.当卷积层的局部连接是全局连接时,全连接层是卷积层的特例;
21.反卷积的棋盘效应及解决方案
图像生成网络的上采样部分通常用反卷积网络,不合理的卷积核大小和步长会使反卷积操作产生棋盘效应
解决方案:
22.分类的预训练模型如何应用到语义分割上
1.参考论文: Fully Convolutional Networks for Semantic Segmentation
23.SSD和YOLO的区别
24.交叉熵和softmax,还有它的BP
实践部分
1.python中range和xrange有什么不同
两者的区别是xrange返回的是一个可迭代的对象;range返回的则是一个列表,同时效率更高,更快。
2.python中带类和main函数的程序执行顺序
1)对于 if __name__ == '__main__': 的解释相关博客已经给出了说明,意思就是当此文件当做模块被调用时,不会从这里执行,
因为此时name属性就成了模块的名字,而不是main。当此文件当做单独执行的程序运行时,就会从main开始执行。
2)对于带有类的程序,会先执行类及类内函数,或者其他类外函数。这里可以总结为,对于没有缩进的程序段,按照顺序执行。然后,才
到main函数。然后才按照main内函数的执行顺序执行。如果main内对类进行了实例化,那么执行到此处时,只会对类内成员进行初始
化,然后再返回到main 函数中。执行其他实例化之后对象的成员函数调用。
3.神经网络的参数量计算
4.计算空洞卷积的感受野
5.mAP的计算
6.Python tuple和list的区别
7.Python的多线程和多进程,Python伪多线程,什么时候应该用它
8.tensorflow while_loop和python for循环的区别,什么情况下for更优?
while loop的循环次数不确定的情况下效率低,因为要不断重新建图
参考文献
[1] https://blog.csdn.net/u014722627/article/details/77938703
[2] https://www.cnblogs.com/houjun/p/8535471.html
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码