DeiT:使用Attention蒸馏Transformer
题目:Training data-efficient image transformers & distillation through attention
【GiantPandaCV导语】Deit是一个全Transformer的架构,没有使用任何的卷积操作。其核心是将蒸馏方法引入VIT的训练,引入了一种教师-学生的训练策略,提出了token-based distillation。有趣的是,这种训练策略使用卷积网络作为教师网络进行蒸馏,能够比使用transformer架构的网络作为教师取得更好的效果。
1简介
之前的ViT需要现在JFT-300M大型数据集上预训练,然后在ImageNet-1K上训练才能得到出色的结果,但这借助了额外的数据。
ViT文中也表示:“do not generalize well when trained on insufficient amounts of data”数据量不足会导致ViT效果变差。
针对以上问题,Deit核心共享是使用了蒸馏策略,能够仅使用ImageNet-1K数据集就就可以达到83.1%的Top1。
文章贡献如下:
仅使用Transformer,不引入Conv的情况下也能达到SOTA效果。
提出了基于token蒸馏的策略,这种针对transformer的蒸馏方法可以超越原始的蒸馏方法。
Deit发现使用Convnet作为教师网络能够比使用Transformer架构取得更好的效果。
2知识蒸馏
Knowledge Distillation(KD)最初被Hinton提出,与Label smoothing动机类似,但是KD生成soft label的方式是通过教师网络得到的。
KD可以视为将教师网络学到的信息压缩到学生网络中。还有一些工作“Circumventing outlier of autoaugment with knowledge distillation”则将KD视为数据增强方法的一种。
KD能够以soft的方式将归纳偏置传递给学生模型,Deit中使用Conv-Based架构作为教师网络,将局部性的假设通过蒸馏方式引入Transformer中,取得了不错的效果。
本文提出了两种KD:
Soft Distillation: 使用KL散度衡量教师网络和学生网络的输出,即Hinton提出的方法。
其中分别代表学生网络的logits输出和教师网络的logits输出。
Hard-label Distillation: 本文提出的一个KD变体,将教师网络得到的hard输出作为label,即,该方法是无需调参的。
3Deit蒸馏过程
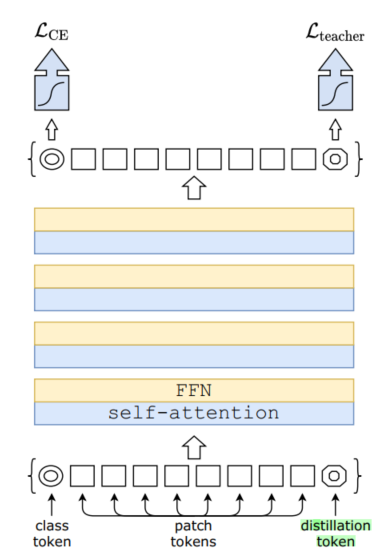
在ViT架构基础上引入了Distillation token,其地位与Class token相等,并且参与了整体信息的交互过程。
Distillation token让模型从教师模型输出中学习,文章发现:
最初class token和distillation token区别很大,余弦相似度为0.06
随着class 和 distillation embedding互相传播和学习,通过网络逐渐变得相似,到最后一层,余弦相似度为0.93
4实验
Deit模型follow了Vision Transformer的设置,训练策略有所不同,仅使用Linear classifier,而不是用MLP head。
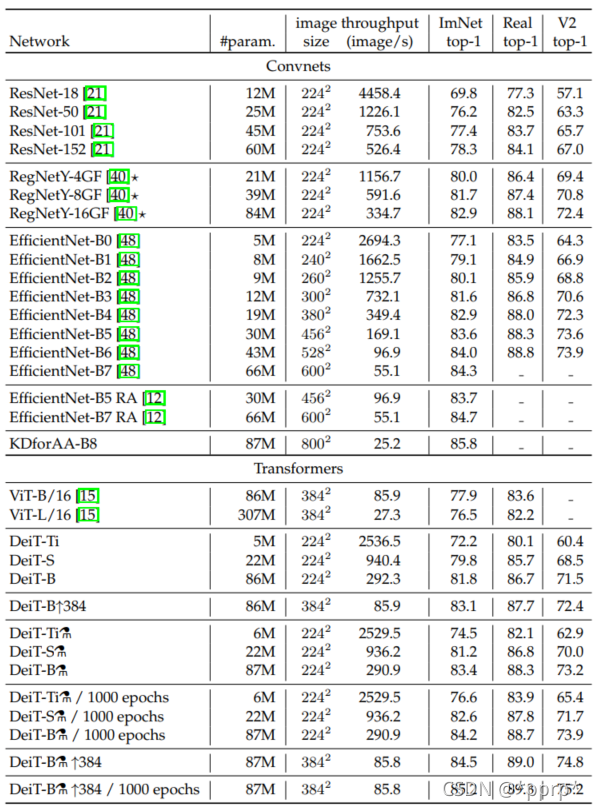
本文提出了Deit的系列模型:
Deit-B:代表与ViT-B有相同架构的模型
Deit-B|384 : 代表对Deit-B进行finetune,分辨率提升到384
Deit-S/Deit-Ti:更小的模型,修改了head数量。

实验1: 选取不同教师网络的效果
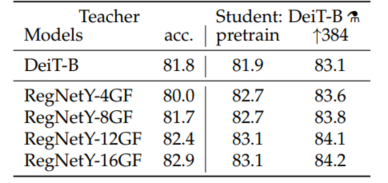
可以发现使用RegNet作为教师网络可以取得更好的性能表现,Transformer可以通过蒸馏来继承归纳偏差。
同时还可以发现,学生网络可以取得超越老师的性能,能够在准确率和吞吐量权衡方面做的更好。
PS:不太明白这里对比的时候为何不选取ViT-H(88.5%top1)作为教师模型?
实验2: 测试不同蒸馏方法
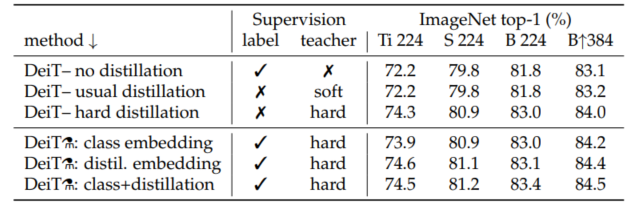
实验证明:hard-label distillation能够取得更好的结果。
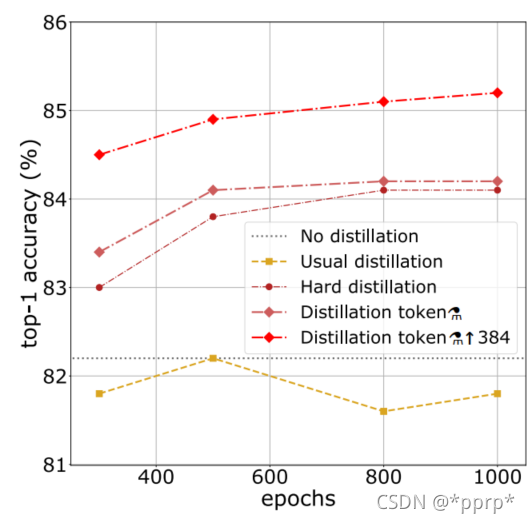
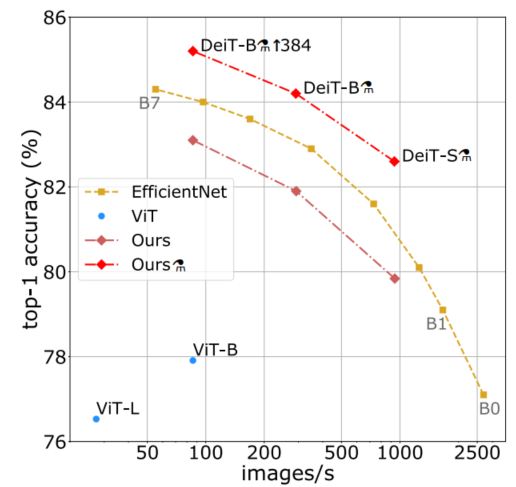
实验3: 与SOTA模型进行比较
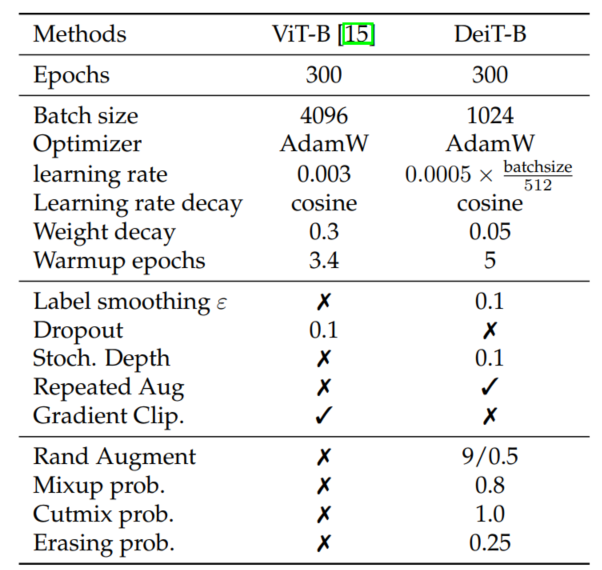
5训练细节
使用truncated normal distribution来进行初始化
soft蒸馏参数:
数据增强:Autoaugment,Rand-augment,random erasing,Cutmix,Mixup,Label Smoothing等
训练300个epoch需要花费37个小时,使用两个GPU
6回顾
问: 为什么不同架构之间也可以蒸馏?蒸馏能够将局部性引入transformer架构吗?
答:教师模型能够将归纳偏置以soft的方式传递给学生模型。
问: 性能增强归功于蒸馏 or 复杂度数据增强方法?
答:蒸馏策略是有效的,但是相比ViT,Deit确实引入了非常多的数据增强方法,直接与ViT比较还是不够公平的。Deit测试了多种数据增强方法,发现大部分数据增强方法能够提高性能,这还是可以理解为Transformer缺少归纳偏置,所以需要大量数据+数据增强。