
transformer 中的 attention
来源:知乎—皮特潘
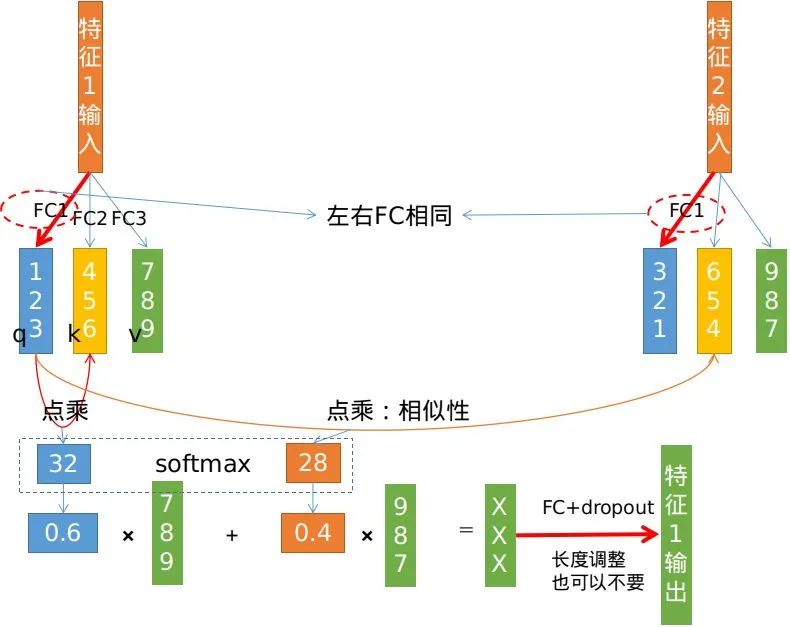
class Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.attend = nn.Softmax(dim = -1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):qkv = self.to_qkv(x).chunk(3, dim = -1)q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scaleattn = self.attend(dots)out = torch.matmul(attn, v)out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)
attention和CNN、RNN、FC、GCN等都是一个级别的东西,用来提取特征;既然是特征提取,一定有权重(W+B)存在。 attention的优点:可以像CNN一样并行运算 + 像RNN一样通过一层就拥有全局资讯。有一个东西也可以做到,那就是FC,但是FC有个弱点:对输入尺寸有限制,说白了不好适应可变输入数据,这对于序列无疑是非常不友好的。 可以像CNN一样并行运算 ,其实CNN运算也是通过im2col或winograd等转化为矩阵运算的。 RNN不能并行,所以通常它处理的数据有“时序”这个特点。既然是“时序”,那么就不是同一个时刻完成的,所以不能并行化。
batch维度:大家利用同样的权重和操作提取特征,可以理解为for循环式,相互之间没有信息交互; multi head维度:同batch类似,不过是利用的不同权重和相同操作提取特征,最后concate一起使用; FC层:是作用在每一个特征上,类似CNN中的1X1,可以叫“pointwise”,和序列长度没有关系;因为序列中所有的特征经过的是同一个FC。
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》
评论