
港大阿里等提出「任意门」算法:零样本物体级图像定制化
作者丨陈汐
编辑丨极市平台
导读
仅需一张目标图,一张场景图,用户可以通过在场景图画框的方式将目标图的物体“传送”到该位置,并且针对场景图的环境对参考模板自动进行姿态、角度、光照、动作等方面的调整,并且生成相应的阴影、倒影、反光等。

香港大学、阿里巴巴达摩院、和蚂蚁集团提出“任意门”算法,可以将任意目标传送到指定场景的指定位置,无需微调,便捷生成高质量、高保真的合成图像。被传送的目标会自动对新的场景进行姿态、角度、动作等方面的调整,确保生成图像的多样性以及和谐度。该算法可以完成多种图像生成或编辑任务如:图像定制化,多目标组合,虚拟试衣;同时,经过简单拓展,任意门算法可以完成更多神奇的应用比如物体移动、换位等。
项目主页: https://damo-vilab.github.io/AnyDoor-Page/
Arxiv地址:https://arxiv.org/pdf/2307.09481.pdf
GitHub: https://github.com/damo-vilab/AnyDoor
背景
随着Stable Diffusion, Imagen等大型文生图模型的提出,图像生成领域有了爆发式的提升;在图像质量和丰富性之余,生成的可控性越来越成为学界和业界共同关注的焦点。ControlNet, Composer等方法可以通过边缘图,深度图等条件对生成图像进行控制;以DreamBooth为代表的定制化生成可以对给定的目标生成图像。虽然这些方法对生成的可控了有了很大提升,但是仍然无法实现“将通用的指定目标融入指定场景“的需求,而该需求有很多应用场景,比如:商品效果图生成,虚拟试衣,海报制作等。
之前的方法有对类似的需求进行探索,比如Paint-by-Example 可以根据参考图中的物体对背景图的指定区域进行重绘,但是他只能保证“语义类别”级别的一致性,尤其对于训练中未见的新类别无法保持ID一致性。定制化生成方法如DreamBooth, Text Inversion, Cones可以较好的保持ID一致性,但是无法指定生成的场景和位置。此外,定制化方法往往需要多张参考图对模型进行接近一个小时的微调,且在进行多目标组合生成时会发生特征混淆。
针对以上困难,我们提出任意门(AnyDoor)算法。仅需一张目标图,一张场景图,用户可以通过在场景图画框的方式将目标图的物体“传送”到该位置,并且针对场景图的环境对参考模板自动进行姿态、角度、光照、动作等方面的调整,并且生成相应的阴影、倒影、反光等。任意门生成的目标在ID的一致性上甚至优于定制化生成方法,并且仅需单张参考图,无需微调。我们的算法在生成质量和便捷性上有很强的优势,为业界大规模应用提供可能,并且可以作为多种图像生成和编辑任务的基线推动学界的发展。
方法
任意门算法的核心思想是将目标表征成“ID相关”和“细节相关”的特征,让后将他们在和背景环境特征的交互中重组。为了学习同一目标在不同场景中不同的外观、动作、光照等,我们使用了大规模视频和图像数据联合训练。
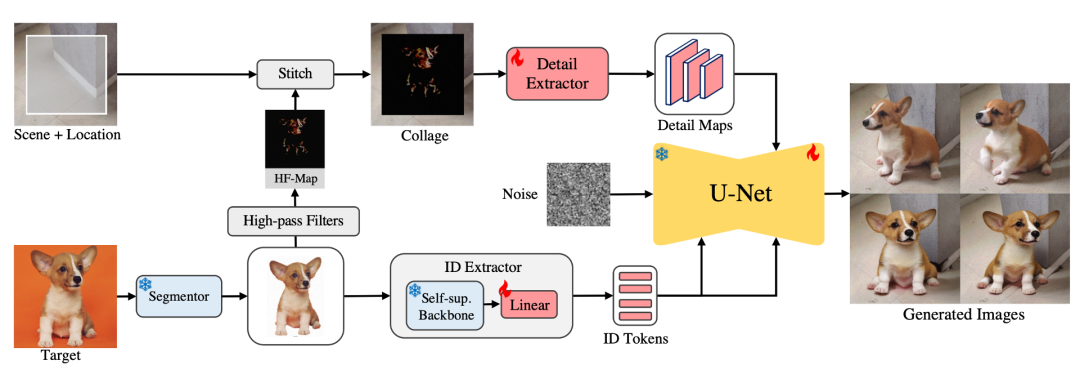
算法流程如上图所示,给定一张目标图,首先使用分割模型对该图进行背景去除,用我们设计的ID extractor进行ID特征提取;同时我们使用高频滤波器提取参考图的高频细节分类,将该高频图拼贴到背景图的指定位置,送入Detail extractor进行细节提取。之后将我们将提取的ID特征和细节特征注入预训练的文生图大模型以控制最终的生成结果。
ID特征提取: 不同于之前的方法使用CLIP Image Encoder,我们发现大型自监督模型对目标ID信息有更好的表征。我们使用当前最先进的DINO-V2作为Backbone, 我们固定自监督预训练的参数,仅需训练一层linear layer即可将表征映射到Diffusion model的语义空间。
细节特征提取: 我们发现基于拼贴的方法可以对生成细节提供很强的先验。为了防止生成的图像和参考图过于相似,我们仅提取参考图中的高频分量用于表达细节特征;我们将高频分量图和背景图拼贴在一起,用Detail extractor提取一组不同尺度的特征图送入U-Net进行监督。如下图所示,我们可视化了DINO-V2的attention map以及参考图像的高频分量,我们发现两者可以互补的对参考目标进行细粒度表征。

特征注入: 我们使用Stable Diffusion作为我们的基座模型,将ID特征通过cross-attention注入Stable Diffusion的每一层;同时我们将细节特征和UNet decoder的特征进行concat融合。在训练过程中,我们将UNet Encoder的参数固定,对Decoder参数进行微调。
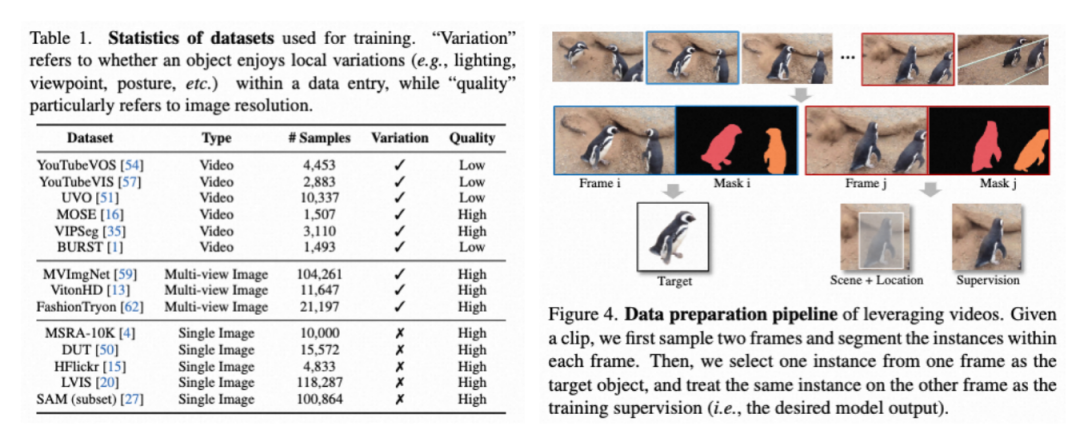
视频、图像动态采样: 为了学习“同一个目标在不同场景的外观变化”,如下表,我们收集了大量图像视频数据进行联合训练。对于视频数据,我们用下图的方式使用分割以及跟踪标注构造样本对;对于静态图像,我们对图像进行扩充构造样本对。该方式构造的数据面临一个问题:视频样本有很高的多样性,但是画质模糊;图像样本画质清晰,但是不能很好的建模目标的姿态、动作变化。由此我们提出动态采样的方法。即在去噪训练的初始阶段更多的采样视频样本,由此学习更大幅度的外观变化;在去噪的后期更多的采样静态图像,以学习更好的细节重建能力。
由此,我们的算法可以在无需微调的情况下,完成目标传送的功能。
实验
我们首先和reference-based方法进行了对比,这些方法的问题设置与AnyDoor类似,输入一张参考图,一张背景图,将参考图的目标传送到背景图的制定位置。(下图中的Stable Diffusion我们使用详尽的语言描述提供引导。)可以看出,之前的方法在ID保持能力上和AnyDoor存在显著差距。

此外,我们还对比了tuning-based定制化方法,此类方法需要多张参考图像对模型进行接近一小时的微调;即便如此,在多目标组合的任务上,我们的算法在无需微调的情况下对比此类需要微调的方法显现出较为明显的优势。

应用
我们的算法可以应用到多种图像编辑和生成任务,取得较为满意的效果。
虚拟试衣: 传统的试衣算法需要复杂的human parsing算法作为配合。我们的方法可以使用更加宽松的输入条件,仅需衣服的平铺图和模特上半身的位置框即可达到媲美SOTA算法的效果。值得注意的是,我们的算法仅使用了不到1/10的试衣数据进行训练。我们有理由相信,在收集大量服饰数据后可以作为虚拟试衣的强力基线。


多目标组合: 对于tuning-based定制化方法,多目标组合是一个挑战性十足的课题,基于text inversion的方法在生成多概念组合时经常出现特征混淆的问题,而我们的算法有位置框的指引,可以非常自然的完成多目标组合生成。

更灵活的用户交互: 由于我们的算法生成质量和ID保持能力强。配合inpainting算法和interactive segmentation算法后可以完成一些神奇的图像编辑功能比如对目标进行拖拽、换位、或者姿态改变,以及对目标图的指定区域进行重绘。

展望
我们希望任意门(AnyDoor)算法可以成为学界region-to-region image mapping类任务的通用baseline, 同时为业界的大规模落地提供参考。