
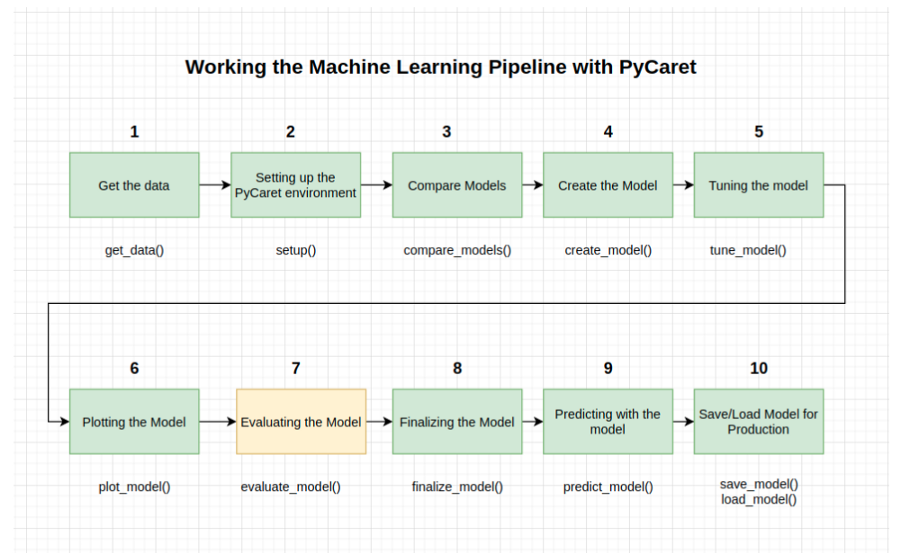
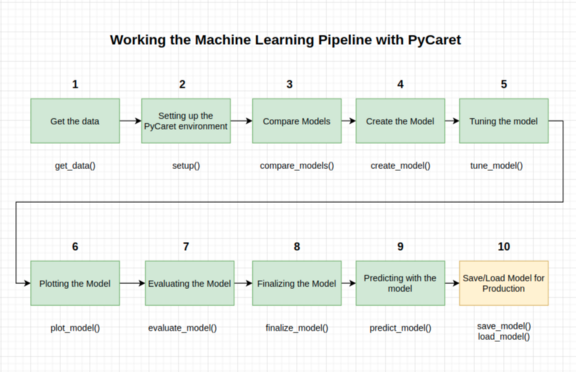
【机器学习】用PyCaret创建整个机器学习管道
作者 | Daniel Morales
编译 | VK
来源 | Towards Data Science
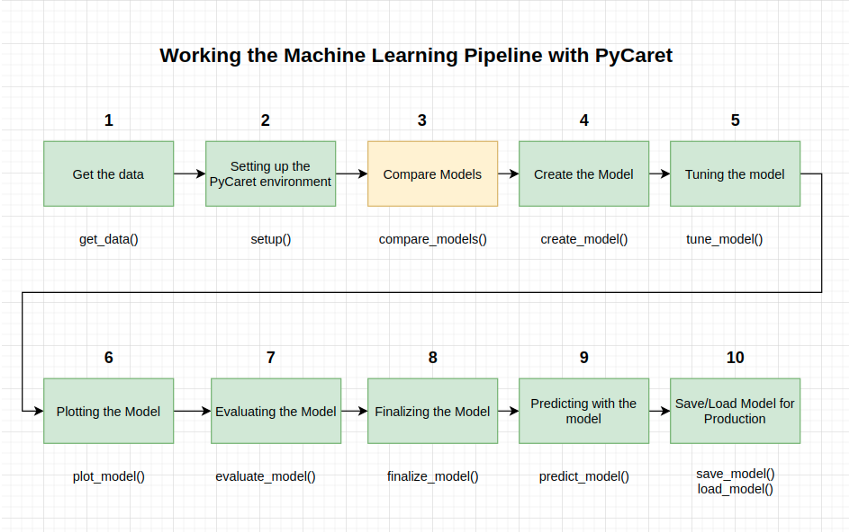
本教程涵盖了整个ML过程,从数据获取、预处理、模型训练、超参数拟合、预测和存储模型以备将来使用。
我们将在不到10个命令中完成所有这些步骤,这些命令是自然构造的,并且非常直观易记,例如
create_model(),
tune_model(),
compare_models()
plot_model()
evaluate_model()
predict_model()
让我们看看全局
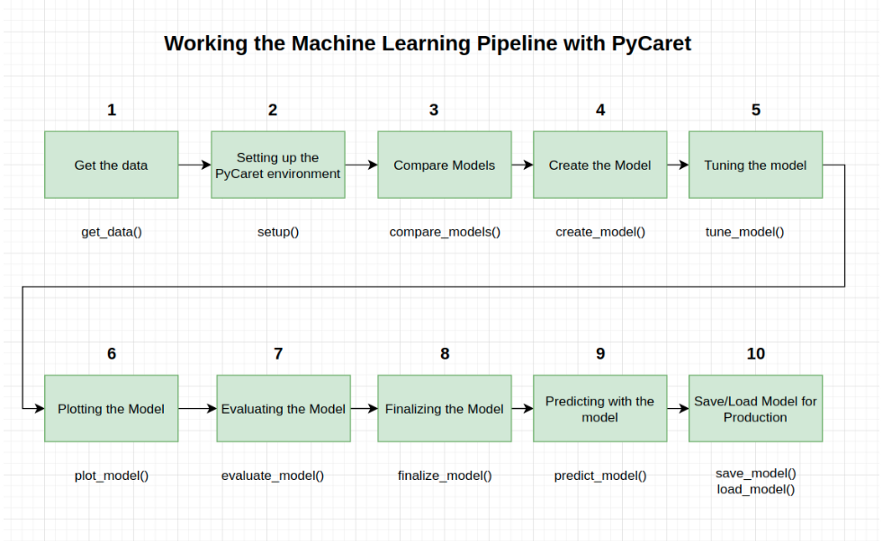
在大多数库中,不使用PyCaret重新创建整个实验需要100多行代码。PyCaret还允许你执行更高级的操作,例如高级预处理、集成、广义叠加和其他技术,这些技术允许你完全定制ML管道,这是任何数据科学家必须具备的。
PyCaret是一个开源的、底层的、使用Python的ML库,它允许你在几分钟内从准备数据到部署模型。允许科学家和数据分析员从头到尾高效地执行迭代数据科学实验,并允许他们更快地得出结论,因为在编程上花费的时间要少得多。这个库非常类似于Caret de R,但是用python实现的
在数据科学项目中,理解数据通常需要很长时间(EDA和特征工程)。那么,如果我们能把花在项目建模部分的时间减少一半呢?
让我们看看怎么做
首先我们需要先决条件
Python 3.6或更高版本
PyCaret 2.0或更高版本
在这里你可以找到库的文件和其他:https://pycaret.org/
首先,请运行以下命令:!pip3 install pycaret
对于google colab用户:如果你在google colab中运行此笔记本,请在笔记本顶部运行以下代码以显示交互式图像
from pycaret.utils import enable_colab
enable_colab()
Pycaret模块
Pycaret根据我们要执行的任务进行划分,并且有不同的模块,这些模块代表每种类型的学习(有监督的或无监督的)。在本教程中,我们将使用二分类算法研究监督学习模块。
分类模块
PyCaret分类模块(pycaret.classification)是一个有监督的机器学习模块,用于根据各种技术和算法将元素分类为二类。分类问题的一些常见用途包括预测客户违约(是或否)、客户放弃(客户将离开或留下)、遇到的疾病(阳性或阴性)等等。
PyCaret分类模块可用于二或多类分类问题。它有18个以上的算法和14个分析模型性能的曲线图。无论是超参数调整、加密还是诸如堆叠之类的高级技术,PyCaret的分类模块都有。
在本教程中,我们将使用一个UCI数据集,称为默认信用卡客户数据集。此资料集包含2005年4月至2005年9月台湾信用卡客户的拖欠付款、人口统计资料、信用资料、付款记录及帐单结算单的资料。有24000个样本和25个特征。
数据集可以在这里找到。或者在这里你可以找到一个直接的下载链接:https://drive.google.com/file/u/2/d/1bVUAk2Y4bdqKx-2NAPk0b4mIOv078zl6/view?usp=sharing
所以,将数据集下载到你的环境中,然后我们将像这样加载它
[2]:
import pandas as pd
[3]:
df = pd.read_csv('datasets/default of credit card clients.csv')
[4]
df.head()
[4]的输出
1-获取数据
我们还有另一种加载方法。实际上,这将是我们在本教程中使用的默认方式。它直接来自PyCaret数据集,是我们管道的第一个方法
from pycaret.datasets import get_data
dataset = get_data('credit')
# 检查数据的形状
dataset.shape
为了演示predict_model函数对未查看的数据的作用,保留了原始数据集中1200条记录的样本,以便在预测中使用。
这不应与训练/测试分割相混淆,因为这个特殊的分割是为了模拟真实的场景。另一种思考方式是,在进行ML实验时,这1200条记录是不可用的。
[7]:
## sample从对象的一个轴返回一个随机样本。那将是22800个样本,而不是24000个
data = dataset.sample(frac=0.95, random_state=786)
[8]:
data
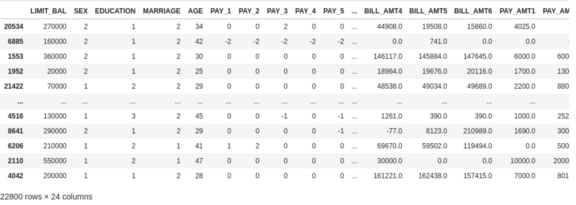
# 我们从原始数据集中删除这些随机数据
data_unseen = dataset.drop(data.index)
[10]:
# 未查看的数据集
## 我们重置了两个数据集的索引
data.reset_index(inplace=True, drop=True)
data_unseen.reset_index(inplace=True, drop=True)
print('Data for Modeling: ' + str(data.shape))
print('Unseen Data For Predictions: ' + str(data_unseen.shape))
Data for Modeling: (22800, 24)
Unseen Data For Predictions: (1200, 24)
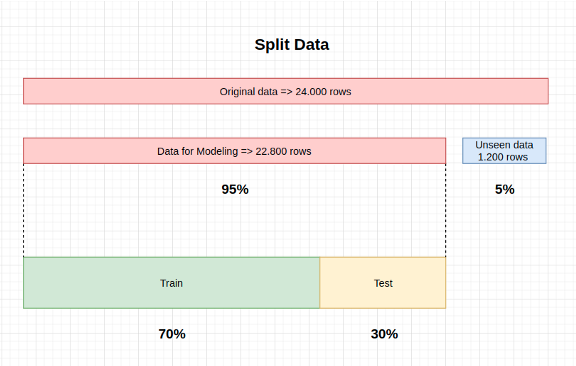
拆分数据
我们划分数据集的方式很重要,因为有些数据在建模过程中不会使用,我们将在最后通过模拟真实数据来验证我们的结果。我们将用于建模的数据进行细分,以便评估训练和测试这两个场景。因此,我们做了以下工作
验证数据集
是用于提供最终模型的无偏评估的数据样本。
验证数据集提供了用于评估模型的黄金标准。
它只在模型完全训练后使用(使用训练集和测试集)。
验证集通常用于评估比赛的模型(例如,在许多Kaggle比赛时,测试集与训练测试集一起初始发布,验证集仅在比赛即将结束时发布,验证集模型的结果决定了胜利者)。
很多时候测试集被用作验证集,但这不是一个好的实践。
验证集通常都很好地修复了。
它包含了仔细采样的数据,这些数据涵盖了模型在现实世界中使用时将面临的各种类。
训练数据集
训练数据集:用于训练模型的数据样本。
我们用来训练模型的数据集
模型看这些数据并学习。
测试数据集
测试数据集:在调整模型超参数时,用于提供与训练数据集匹配的数据样本。
随着测试数据集中的信息被纳入模型中,评估变得更加有偏见。
测试集用于评估给定的模型,但这是用于频繁评估的。
作为ML工程师,我们使用这些数据来微调模型的超参数。
因此,模型偶尔会看到这些数据,但从不从中“学习”。
我们使用测试集的结果,更新更高级别的超参数
所以测试集会影响模型,但只是间接的。
测试集也称为开发集。这是有意义的,因为这个数据集在模型的“开发”阶段有帮助。
术语混淆
有一种混淆测试和验证集名称的趋势。
根据教程、来源、书籍、视频或老师/导师的不同,术语会有所变化,重要的是要保持概念不变。
在我们的例子中,我们已经在开始时分离了验证集
2-设置PyCaret环境
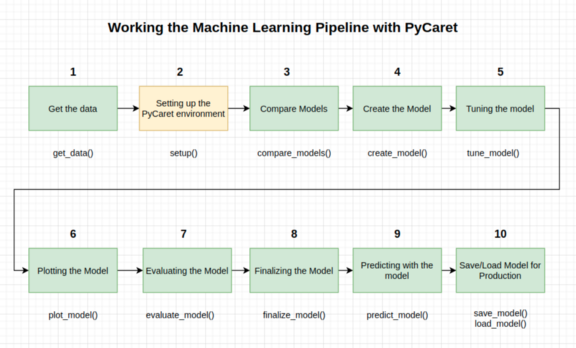
现在让我们设置Pycaret环境。函数的作用是:初始化pycaret中的环境,并创建转换管道,为建模和部署准备数据。
在pycaret中执行任何其他函数之前必须调用setup()。它需要两个必需的参数:pandas dataframe和目标列的名称。这部分配置大部分是自动完成的,但有些参数可以手动设置。例如:
默认的分割比是70:30(正如我们在上面的段落中看到的),但是可以用“train_size”来更改。
K折叠交叉验证默认设置为10
“session_id”是我们经典的“random_state”
[12]:
## 设置环境
from pycaret.classification import *
注意:运行以下命令后,必须按enter键完成此过程。我们会解释他们是怎么做到的。安装过程可能需要一些时间才能完成。
[13]:
model_setup = setup(data=data, target='default', session_id=123)
运行setup()时,PyCaret的推理算法将根据某些属性自动推断出所有特征的数据类型。但情况并非总是如此。
为了考虑到这一点,PyCaret在执行setup()之后会显示一个包含特征及其推断数据类型的表。如果正确识别了所有数据类型,则可以按enter继续,或按exit结束实验。我们按enter键,输出的结果应该和上面的一样。
确保数据类型是正确的在PyCaret中是至关重要的,因为它自动执行一些预处理任务,这些任务对于任何ML实验都是必不可少的。对于每种类型的数据,执行任务的方式不同,所以这意味着正确配置非常重要。
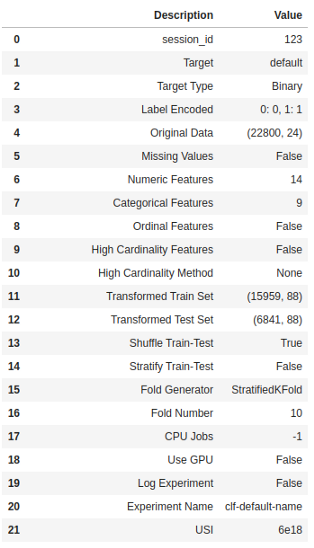
我们可以使用setup()中的numeric_features和category_features参数覆盖从PyCaret推断的数据类型。一旦设置成功执行,将打印包含几个重要信息的信息网格。大多数信息都与运行setup()时生成的预处理管道有关
这些特征中的大多数都超出了本教程的范围,但是,在此阶段需要记住的一些重要的包括
session_id:一个伪随机数,作为种子分布在所有函数中,以便以后的重现性。
目标类型:二或多类。自动检测并显示目标类型。
Label encoded:当目标变量的类型为string(即“Yes”或“No”)而不是1或0时,它会自动在1和0处对标签进行编码,并将映射(0:No,1:Yes)显示为引用
原始数据:显示数据集的原始形式。在这个实验中是(22800,24)
缺少值:当原始数据中缺少值时,将显示为True
数值特征:推断为数值特征的数量。
类别特征:推断为类别特征的数量
转换后的训练组:注意,原来的(22800,24)形式被转换为(15959,91),由于分类编码,特征的数量从24增加到91
转换测试集:测试集中有6841个样本。此拆分基于默认值70/30,可使用配置中的“训练大小”参数进行更改。
注意一些必须进行建模的任务是如何自动处理的,例如缺失值的插补(在这种情况下,训练数据中没有缺失的值,但我们仍然需要为看不见的数据提供插补器)、分类编码等。
大部分setup()参数是可选的,用于自定义预处理管道。
3-比较模型
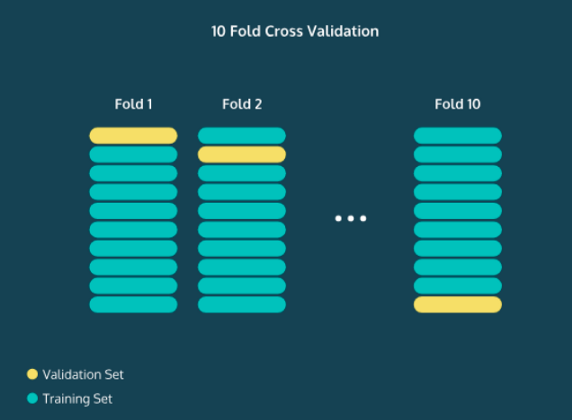
为了理解PyCaret是如何比较模型和管道中的下一步的,有必要理解N-fold交叉验证的概念。
N-Fold 交叉验证
计算有多少数据应该划分到测试集中是一个微妙的问题。
如果你的训练集太小,你的算法可能没有足够的数据来有效地学习。另一方面,如果你的测试集太小,那么你的准确度、精确度、召回率和F1分数可能会有很大的变化。
你可能很幸运,也可能很不幸!一般来说,将70%的数据放在训练集中,30%的数据放在测试集中是一个很好的起点。有时你的数据集太小了,70/30会产生很大的差异。
一种解决方法是执行N折交叉验证。这里的中心思想是,我们将整个过程进行N次,然后平均精度。例如,在10折交叉验证中,我们将测试集的前10%的数据,并计算准确度、精确度、召回率和F1分数。
然后,我们将使交叉验证建立第二个10%的数据,我们将再次计算这些统计数据。我们可以做这个过程10次,每次测试集都会有一段不同的数据。然后我们平均所有的准确度。
注意:验证集(这里是黄色)是我们案例中的测试集
了解模型的准确度是非常宝贵的,因为可以开始调整模型的参数以提高模型的性能。
例如,在K-最近邻算法中,你可以看到当你增加或减少K时,精确度会发生什么变化。一旦你对模型的性能感到满意,就应该输入验证集了(在我们的例子中是看不见的)。
它应该是你真正感兴趣的真实世界数据的替代品。它的工作原理与测试集非常相似,只是在构建或优化模型时从未接触过这些数据。通过找到精度指标,你可以很好地了解算法在现实世界中的性能。
比较所有模型
在PyCaret setup()完成后,建议将所有模型进行比较以评估性能(除非你确切知道需要什么类型的模型,通常情况下并非如此),该函数训练模型库中的所有模型,并使用分层交叉验证对其进行评分,以评估度量。
输出将打印一个分数网格,该网格显示精度、AUC、召回率、精度、F1、Kappa和MCC的平均值(默认为10)以及训练时间。开始吧!
[14]:
best_model = compare_models()
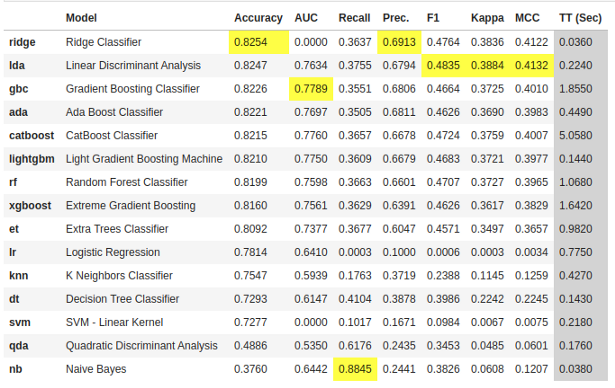
compare_models()函数的作用是:一次比较多个模型。这是使用PyCaret的最大优点之一。在一行中,你可以看到许多模型之间的比较表。两个简单的单词(甚至不是一行代码)已经使用N倍交叉验证训练和评估了超过15个模型。
以上打印的表格突出显示了最高性能指标,仅供比较之用。默认表使用“精度”(从最高到最低)排序,可以通过传递参数来更改。例如,compare_models(sort = 'Recall')将根据召回而不是准确度对网格进行排序。
如果要将Fold参数从默认值10更改为其他值,可以使用Fold参数。例如,compare_models(fold = 5)将在5倍交叉验证中比较所有模型。减少折叠次数可以缩短训练时间。
默认情况下,compare_models根据默认的排序顺序返回性能最好的模型,但是它可以使用N_select参数返回前N个模型的列表。此外,它还返回一些指标,如精确度、AUC和F1。另一个很酷的事情是库如何自动突出显示最佳结果。一旦选择了模型,就可以创建模型,然后对其进行优化。我们试试用其他方法:
[15]:
print(best_model)
RidgeClassifier(alpha=1.0, class_weight=None, copy_X=True, fit_intercept=True,
max_iter=None, normalize=False, random_state=123, solver='auto',
tol=0.001)
4-创建模型
create_model是PyCaret中最细粒度的函数,通常是PyCaret大多数功能的基础。正如它的名字所示,这个函数使用交叉验证(可以用参数fold设置)来训练和评估模型。输出打印一个计分表,按Fold 显示精度、AUC、召回率、F1、Kappa和MCC。
在本教程的其余部分中,我们将使用以下模型作为候选模型。这些选择仅用于说明目的,并不一定意味着他们是最好的执行者或这类数据的理想选择
决策树分类器('dt')
K近邻分类器('knn')
随机森林分类器('rf')
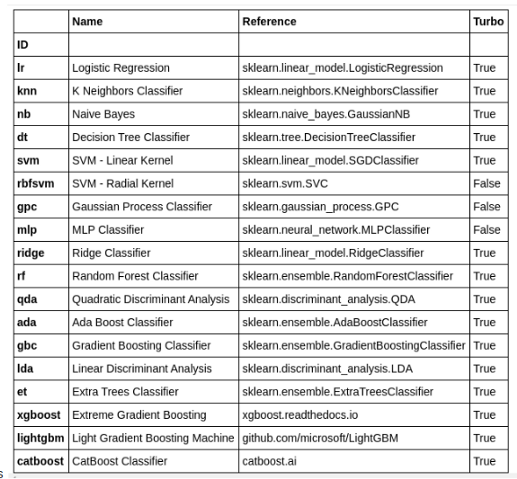
PyCaret模型库中有18个分类器可用。要查看所有分类器的列表,请查看文档或使用models()函数查看库。
[16]:
models()
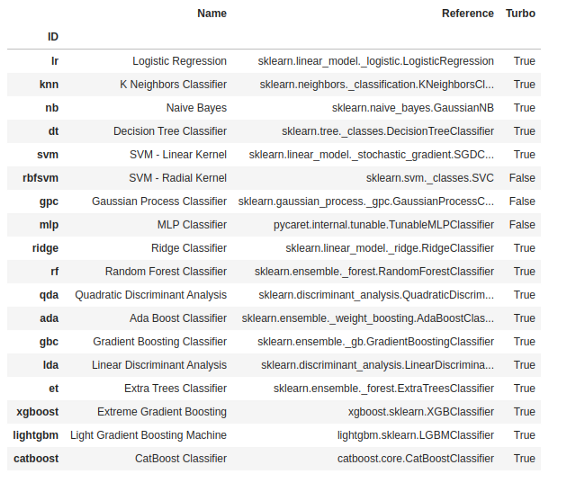
dt = create_model('dt')
# 训练的模型对象存储在变量'dt'中。
print(dt)
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=123, splitter='best')
[19]:
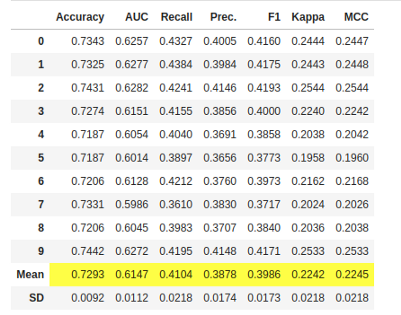
knn = create_model('knn')
print(knn)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=-1, n_neighbors=5, p=2,
weights='uniform')
[21]:
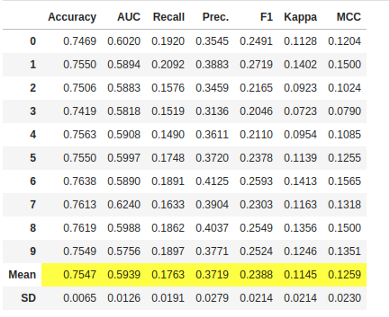
rf = create_model('rf')
print(rf)
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=-1, oob_score=False, random_state=123, verbose=0,
warm_start=False)
请注意,所有模型的平均分数与compare_models()上打印的分数匹配。这是因为compare_models()分数网格中打印的指标是所有折的平均分数。
你还可以在每个模型的每个print()中看到用于构建它们的超参数。这是非常重要的,因为它是改进它们的基础。你可以看到RandomForestClassifier的参数
max_depth=None
max_features='auto'
min_samples_leaf=1
min_samples_split=2
min_weight_fraction_leaf=0.0
n_estimators=100
n_jobs=-1
5-调整模型
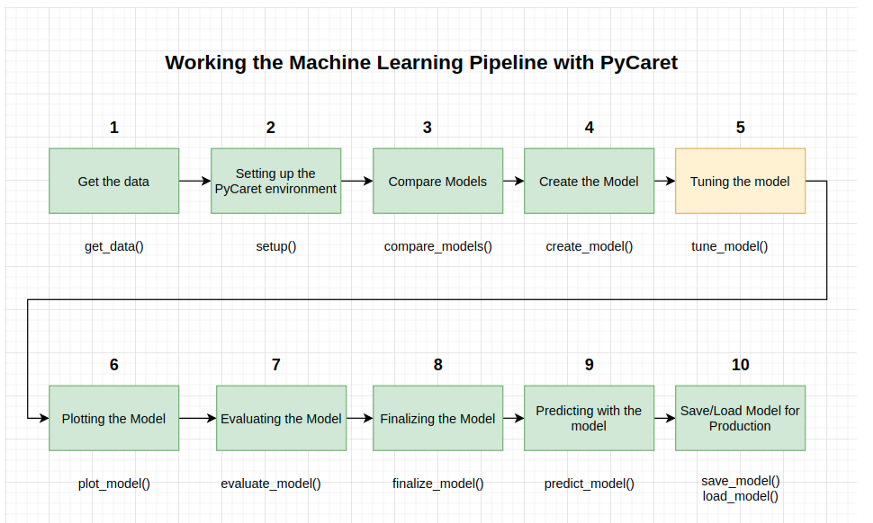
使用create_model()函数创建模型时,默认的超参数用于训练模型。要调整超参数,请使用tune_model()函数。此函数使用预定义搜索空间中的随机网格搜索自动调整模型的超参数。
输出打印一个分数网格,显示准确度、AUC、召回率、精密度、F1、Kappa和MCC,以获得最佳模型。要使用自定义搜索网格,可以在tune_model函数中传递custom_grid参数
[23]:
tuned_rf = tune_model(rf)
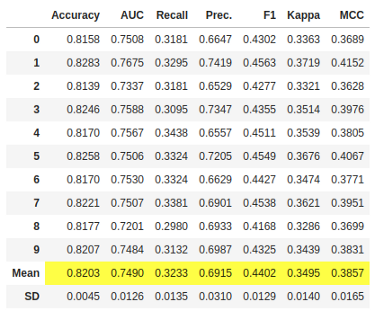
如果我们将这个改进的RandomForestClassifier模型与之前的RandomForestClassifier模型的准确度指标进行比较,我们会发现一个差异,因为它的精确度从0.8199提高到了0.8203。
[24]:
# 优化模型对象存储在变量“tuned_dt”中。
print(tuned_rf)
RandomForestClassifier(bootstrap=False, ccp_alpha=0.0, class_weight={},
criterion='entropy', max_depth=5, max_features=1.0,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0002, min_impurity_split=None,
min_samples_leaf=5, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=150,
n_jobs=-1, oob_score=False, random_state=123, verbose=0,
warm_start=False)
现在我们来比较一下超参数。我们以前是:
max_depth=None
max_features='auto'
min_samples_leaf=1
min_samples_split=2
min_weight_fraction_leaf=0.0
n_estimators=100
n_jobs=-1
而现在是:
max_depth=5
max_features=1.0
min_samples_leaf=5
min_samples_split=10
min_weight_fraction_leaf=0.0
n_estimators=150
n_jobs=-1
你可以自己用knn和dt做同样的比较,探索超参数之间的差异。
默认情况下,tune_model优化精度,但可以使用optimize参数更改此值。例如:tune_model(dt,optimize='AUC')将查找决策树分类器的超参数,该分类器将导致最高的AUC而不是准确性。在本例中,我们仅为简单起见使用了Accuracy的默认度量。
一般来说,当数据集不平衡(像我们正在使用的信用数据集)时,精度不是一个很好的度量标准。选择正确的度量来评估的方法超出了本教程的范围。
在为生产选择最佳模型时,度量并不是你应该考虑的唯一标准。其他要考虑的因素包括训练时间、k-folds的标准差等。现在,让我们继续考虑随机森林分类器tuned_rf,作为本教程其余部分的最佳模型
6-绘制模型
在完成模型(步骤8)之前,plot#model()函数可以通过AUC、混淆矩阵、决策边界等不同方面来分析性能。该函数获取一个经过训练的模型对象,并根据训练/测试集返回一个图形。
有15种不同的绘图,请参阅plot_model()文档以获取可用绘图的列表。
[25]:
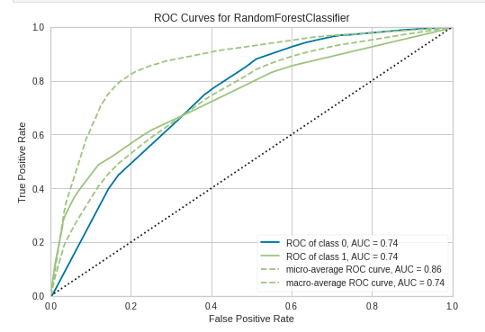
# AUC 图
plot_model(tuned_rf, plot = 'auc')
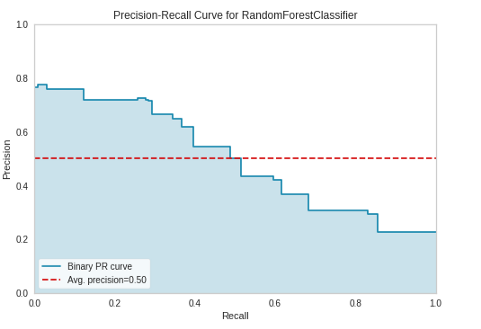
## PR 曲线
plot_model(tuned_rf, plot = 'pr')
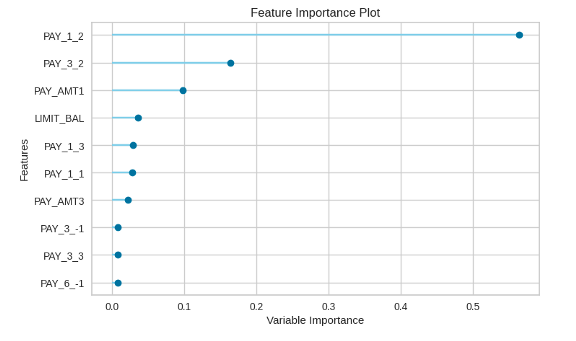
## 特征重要性
plot_model(tuned_rf, plot='feature')
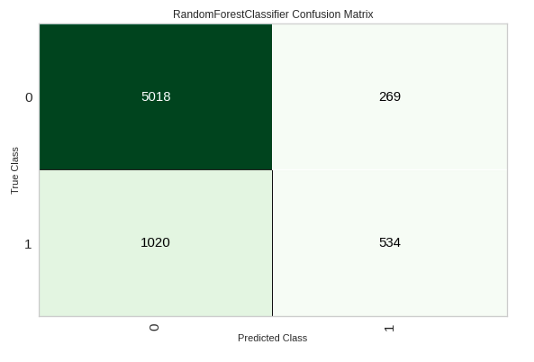
## 混淆矩阵
plot_model(tuned_rf, plot = 'confusion_matrix')
7-评估模型
分析模型性能的另一种方法是使用evaluate_model()函数,该函数显示给定模型的所有可用图形的用户界面。在内部它使用plot_model()函数。
[29]:
evaluate_model(tuned_rf)
8-最终确定模型
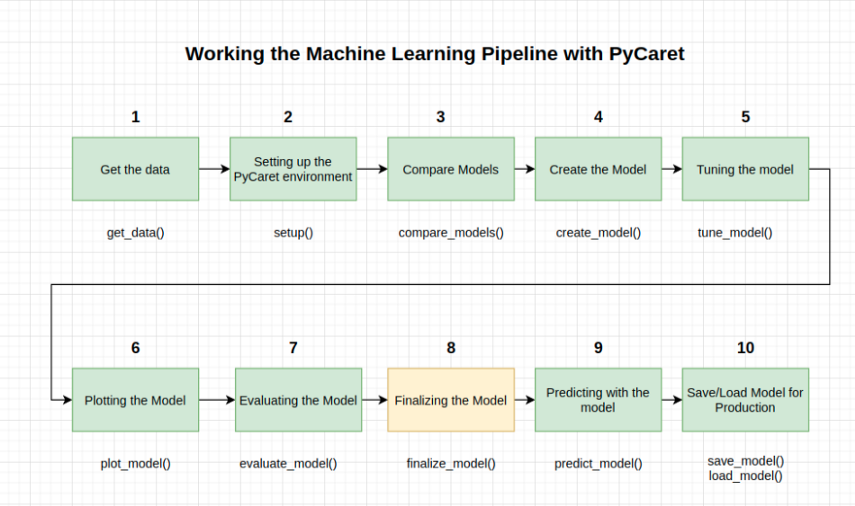
模型的建立是实验的最后一步。PyCaret中的正常机器学习工作流从setup()开始,然后使用compare_models()对所有模型进行比较,并预先选择一些候选模型(基于感兴趣的度量),以执行各种建模技术,如超参数拟合、装配、堆叠等。
此工作流最终将引导你找到用于对新的和未查看的数据进行预测的最佳模型。
finalize_model()函数使模型拟合完整的数据集,包括测试样本(在本例中为30%)。此函数的目的是在将模型部署到生产环境之前,对模型进行完整的数据集训练。我们可以在predict_model()之后或之前执行此方法。我们要在这之后执行。
最后一句警告。使用finalize_model()完成模型后,整个数据集(包括测试集)将用于训练。因此,如果在使用finalize_model()之后使用模型对测试集进行预测,则打印的信息网格将产生误导,因为它试图对用于建模的相同数据进行预测。
为了证明这一点,我们将在predict_model()中使用final_rf来比较信息网格与前面的网格。
[30]:
final_rf = finalize_model(tuned_rf)
[31]:
# 部署的最终随机森林模型参数
print(final_rf)
RandomForestClassifier(bootstrap=False, ccp_alpha=0.0, class_weight={},
criterion='entropy', max_depth=5, max_features=1.0,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0002, min_impurity_split=None,
min_samples_leaf=5, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=150,
n_jobs=-1, oob_score=False, random_state=123, verbose=0,
warm_start=False)
9-用模型预测
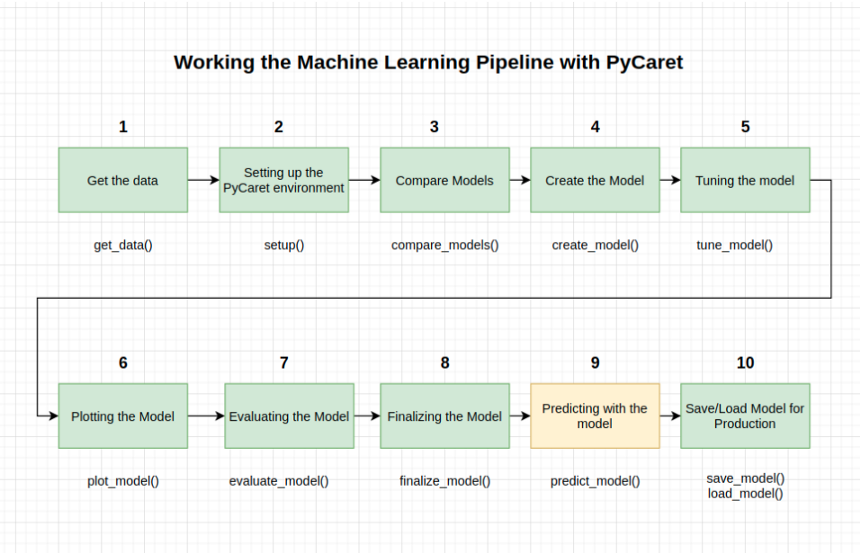
在最终确定模型之前,建议通过预测测试和查看评估指标来执行最终检查。如果你查看信息表,你将看到30%(6841个样本)的数据被分离为测试集样本。
我们在上面看到的所有评估指标都是基于训练集(70%)的交叉验证结果。现在,使用存储在tuned_rf变量中的最终训练模型,我们根据测试样本进行预测,并评估指标,看它们是否与CV结果有实质性差异
[32]:
predict_model(final_rf)
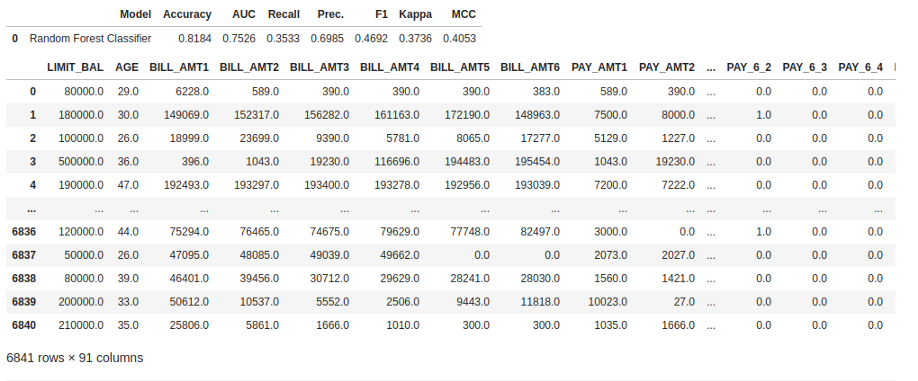
测试集的准确度为0.8199,而tuned_rf的结果为0.8203。这并不是一个显著的区别。如果测试集和训练集的结果之间存在较大差异,这通常表示过拟合,但也可能是由于其他几个因素造成的,需要进一步调查。
在本例中,我们将继续完成模型,并对不可见的数据进行预测(我们在开始时分离的5%的数据,它们从未暴露在PyCaret中)。
提示:使用create_model()时,最好查看训练集结果的标准差。
predict_model()函数还用于预测未查看的数据集。唯一不同的是,这次我们将传递参数数据。data_unseen是在教程开始时创建的变量,包含5%(1200个示例)的原始数据集,这些数据集从未公开给PyCaret。
[33]:
unseen_predictions = predict_model(final_rf, data=data_unseen)
unseen_predictions.head()
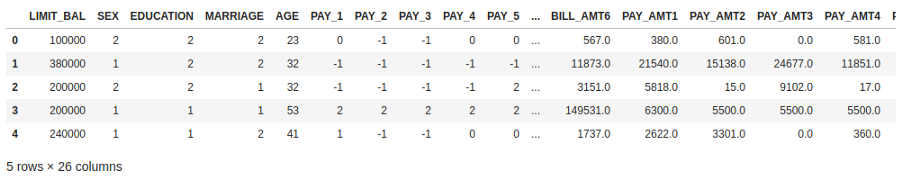
请转到上一个结果的最后一列,你将看到一个名为Score的新特征
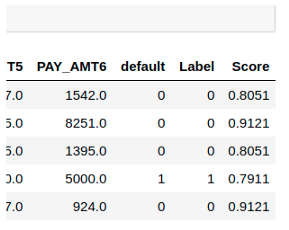
Label是预测,score是预测的概率。请注意,预测结果与原始数据集连接,而所有转换都在后台自动执行。
我们已经完成了实验,最终确定了tuned_rf模型,该模型现在存储在final_rf变量中。
我们还使用了final_rf中存储的模型来预测未知数据。这就结束了我们的实验,但还有一个问题:当你有更多的新数据要预测时会发生什么?你必须把整个实验再看一遍吗?
答案是否定的,PyCaret内置的save_model()函数允许你保存模型以及所有转换管道以供以后使用,并存储在本地环境中的Pickle中
(提示:保存模型时最好使用文件名中的日期,这有利于版本控制)
让我们看看下一步
10-保存/加载模型
保存模型
[35]:
save_model(final_rf, 'datasets/Final RF Model 19Nov2020')
Transformation Pipeline and Model Succesfully Saved
[35]:
(Pipeline(memory=None,
steps=[('dtypes',
DataTypes_Auto_infer(categorical_features=[],
display_types=True, features_todrop=[],
id_columns=[],
ml_usecase='classification',
numerical_features=[], target='default',
time_features=[])),
('imputer',
Simple_Imputer(categorical_strategy='not_available',
fill_value_categorical=None,
fill_value_numerical=None,
numeric_stra...
RandomForestClassifier(bootstrap=False, ccp_alpha=0.0,
class_weight={}, criterion='entropy',
max_depth=5, max_features=1.0,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0002,
min_impurity_split=None,
min_samples_leaf=5,
min_samples_split=10,
min_weight_fraction_leaf=0.0,
n_estimators=150, n_jobs=-1,
oob_score=False, random_state=123,
verbose=0, warm_start=False)]],
verbose=False),
'datasets/Final RF Model 19Nov2020.pkl')
加载模型
要在同一环境或其他环境中加载在将来某个日期保存的模型,我们将使用PyCaret的load_model()函数,然后轻松地将保存的模型应用到新的未查看的数据中以进行预测
[37]:
saved_final_rf = load_model('datasets/Final RF Model 19Nov2020')
Transformation Pipeline and Model Successfully Loaded
一旦模型加载到环境中,就可以使用相同的predict_model()函数来预测任何新数据。接下来,我们应用加载模型来预测我们以前使用过的相同数据。
[38]:
new_prediction = predict_model(saved_final_rf, data=data_unseen)
[39]:
new_prediction.head()
[39]:

from pycaret.utils import check_metric
check_metric(new_prediction.default, new_prediction.Label, 'Accuracy')
[41]:
0.8167
利弊
与任何新库一样,仍有改进的余地。我们将列出在使用该库时发现的一些利弊。
优点:
它使项目的建模部分更加容易。
只需一行代码就可以创建许多不同的分析。
在拟合模型时,可以不用传递参数列表。PyCaret会自动为你执行此操作。
你有许多不同的选项来评估模型,同样,只需要一行代码
因为它是在著名的ML库之上构建的,所以可以很容易地将其与传统方法进行比较
缺点:
这个库是早期版本,所以它还不够成熟,容易受到bug的影响
作为所有的automl库,它是一个黑匣子,所以你不能真正看到里面发生了什么。因此,我不推荐初学者使用。
这可能会使学习过程有点肤浅。
结论
本教程涵盖了整个ML过程,从数据摄取、预处理、模型训练、超参数拟合、预测和存储模型以备以后使用。
我们只用了不到10个命令就完成了所有这些步骤,这些命令都是自然构造的,并且非常直观易记,例如create_model()、tune_model()、compare_models()。如果不使用PyCaret重新创建整个实验,大多数库需要100多行代码。
该库还允许你执行更高级的操作,例如高级预处理、集成、广义叠加和其他技术,这些技术允许你完全定制ML管道,这是任何数据科学家必须具备的
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: