
总结目标检测匹配策略与改进思路

极市导读
CVPR2020中的文章ATSS揭露到anchor-based和anchor-free的目标检测算法之间的效果差异原因是由于正负样本的选择造成的。而在目标检测算法中正负样本的选择是由gt与anchor之间的匹配策略决定的。因此,本文研究了目前现有的匹配策略,并根据现状给出改进思路。
faster rcnn或retinanet或ssd算法
yolo系列
fcos
Guided Anchoring
论文思想是通过图像特征来指导 anchor 的生成。通过预测 anchor 的位置和形状,来生成稀疏而且形状任意的 anchor,并且设计了 Feature Adaption 模块来修正特征图使之与 anchor 形状更加匹配,在使用 ResNet-50-FPN 作为 backbone 的情况下,Guided Anchoring 将 RPN 的 recall(AR@1000) 提高了 9.1 个点,将其用于不同的物体检测器上,可以提高 mAP 1.2 到 2.7 个点不等。
论文实现方式如下图:
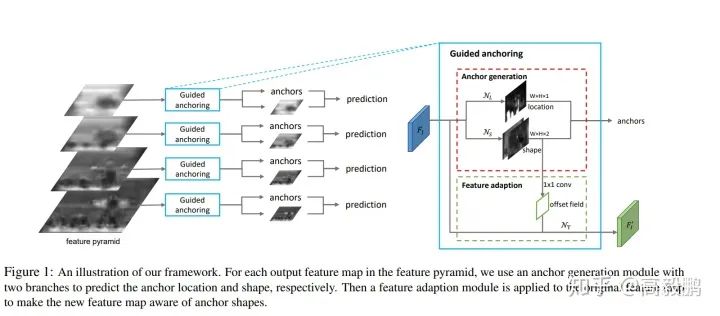
匹配策略:将整个 feature map 的区域分为物体中心区域,外围区域和忽略区域,大概思路就是将 ground truth 框的中心一小块对应在 feature map 上的区域标为物体中心区域,在训练的时候作为正样本,其余区域按照离中心的距离标为忽略或者负样本,具体设计在 paper 里讲得比较清楚。通过位置预测,我们可以筛选出一小部分区域作为 anchor 的候选中心点位置,使得 anchor 数量大大降低。在 inference 的时候,预测完位置之后,我们可以采用 masked conv 替代普通的 conv,只在有 anchor 的地方进行计算,可以进行加速。
ATSS

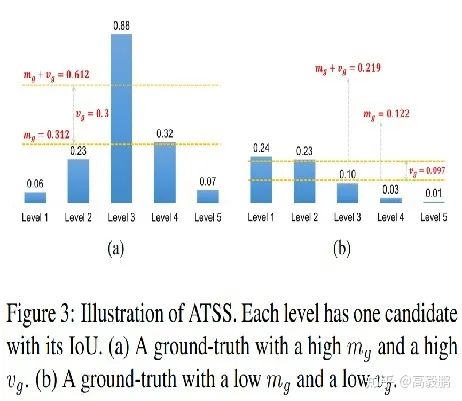
1、对于每个GT,找到候选的正anchor集合
在每个金字塔层级(共L层)上,选择topk个离GT中心距离最近的anchor boxes作为候选anchor, 那么每个GT就会有k*L个候选正anchor。
2、计算自适应阈值
计算候选anchor与GT之间的IoU Dg,计算均值 和标准差 ,其阈值为: 。
3、确定最终的正anchor
选择 ,且中心点在GT边框内部的anchor作为最终的正样本,如果一个anchor box被分配给了多个GT,选择IoU最高的那个GT。
ATSS的意义:
HAMBox
匹配策略:
a)IOU要大于阈值T(在线正anchor匹配阈值)
b)对(a)中得到的anchor进行排序,选择IOU最大的top-K 个anchor做补偿。K是一个超参数,表示每个outer face能matched的最多anchor数目。使用M表示在步骤1中已经匹配的anchor数目。如果N > K-M,则选取top(K-M)个unmatched anchor来补偿。
T和K是通过实验选择的超参数。具体算法细节见下 Algorithm 1,该算法在训练的每次前向传播后执行一次.
Algorithm1具体见下:
/*输入:B,X,T,K,D,L,R,AB 是一组回归后的框,格式为(x0, y0, x1, y1)X 是一组ground truth, 格式为(x0, y0, x1, y1)T 是上述算法中在线anchor挖掘中定义的阈值K 是每个outer face能匹配到的最多anchor数目D 是一个字典,key是ground_truth, value是HAMBox第一步中该gt能match到的anchor数,即matched_anchor的数目L 是一个字典,key是anchor index, value是该anchor在HAMBox中最终分配的labelR 是一个字典,key是anchor index, value是该anchor经过普通anchor matching后的编码后的坐标A 是一个字典,key是anchor index, value是该anchor的坐标,格式为(x0, y0, x1, y1)输出:经过HAMBox后的R和L*/// 伪代码见下for x_i in x doif D(x_i) >= K thencontinueend ifcompensatedNumber = K - D(x_i)onlineIoU = IoU(x_i, B),AnchorIdxsortedOnlineIoU = sorted(onlineIoU, key = IoU, reverse = True)for IoU, AnchorIdx in sortedOnlineIoU doif(L(AnchorIdx) = 1) thencontinueendifif(IoU < T) thencontinueendifcompensatedNumber -= 1L(AnchorIdx) = 1R(AnchorIdx) = encoded(A(AnchorIdx), x_i)if compensatedNumber = 0 thenbreakendifendforendforreturn R, L
推荐阅读
