
国科大CVPR 2020论文:自监督学习新方法,让数据更复杂的视频表...

新智元推荐
编辑:元子
【新智元导读】自监督表征学习由于无需人工标注,特征较好的泛化性等优势受到了越来越多的关注,并不断有研究在图像、语言等领域取得了较大进展。本论文则立足于数据形式更为复杂的视频表征学习,介绍了一种简单且有效的自监督学习方法,并在视频动作分类和检索这两个常见的目标任务中提升了性能,该论文入选了CVPR2020.
论文题目为《一种基于视频播放速率感知的自监督时空表征学习方法》,类似图像在空域具有多分辨率特性,视频在时域同样具有多分辨率特性,基于此,该论文通过设计一种关于速率感知的自监督任务来进行较为全面的视频时空表征学习。
论文地址: https://arxiv.org/abs/2006.11476
视频的多分辨率特性
如图1所示,人们在观看一段运动视频,通常会采用两种播放方式:快进和慢放,通过快进了解运动概貌;通过慢放聚焦某个运动细节。这其实就对应视频的多分辨率特性:不同采样间隔下的有限视频帧在内容描述上具有时间跨度和精细程度的差异。大间隔采样(类似快进):时间跨度大,一般可以覆盖较为完整的运动过程,但精细程度低(低分辨率),更多反映的是整体运动的主要变化。小间隔采样(类似慢放):时间跨度小,一般只能局限于运动过程中的某一时段,但精细程度高(高分辨率),能够反映该时段更多的运动细节。
 图1:两种常见的视频播放模式:快进和慢放
图1:两种常见的视频播放模式:快进和慢放因此,对于一般输入帧数固定的·CNN视频网络模型而言,通过视频多分辨特性以得到更加丰富完善的特征表达是一种非常有效的方法,目前已有一些工作进行了探索和验证。而本论文则是把这种特性结合到自监督学习中,设计了一种新的视频自监督任务。
PPR(Playback Rate Perception)自监督任务框架
如图2所示,PRP首先在Dailed Sampling中使用不同的采样间隔
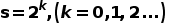 采样得到不同倍率
采样得到不同倍率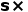 的快进视频段
的快进视频段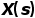 作为网络输入,之后通过基于间隔分类的判别感知和基于慢放重构的生成感知这两种模式进行视频的表征学习。对于输入的快进视频,判别感知通过进行采样间隔的分类促使网络注重前景运动的主要变化(低分辨率特性);生成感知通过进行一定倍率的插值重构促使网络还原更多的运动细节(高分辨率特性);最终二者通过共享网络主干和联合优化来达到表征学习的协同互补。
作为网络输入,之后通过基于间隔分类的判别感知和基于慢放重构的生成感知这两种模式进行视频的表征学习。对于输入的快进视频,判别感知通过进行采样间隔的分类促使网络注重前景运动的主要变化(低分辨率特性);生成感知通过进行一定倍率的插值重构促使网络还原更多的运动细节(高分辨率特性);最终二者通过共享网络主干和联合优化来达到表征学习的协同互补。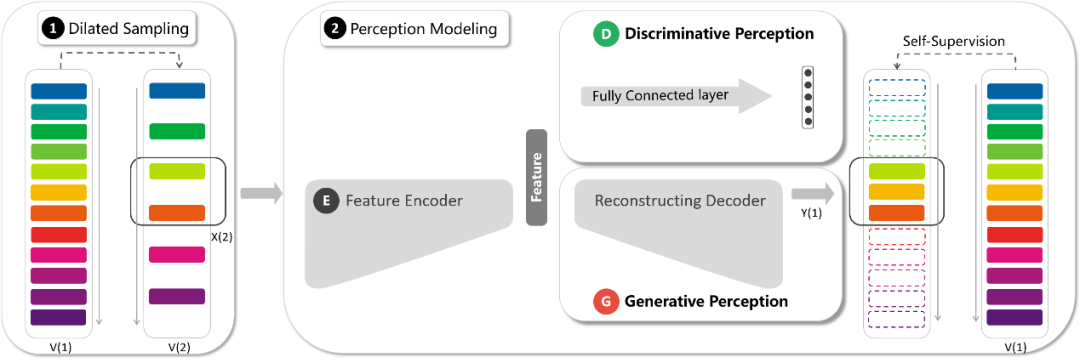 图2:PRP整体框架
图2:PRP整体框架另外在生成感知中,不同于直接使用MSE损失,PPR通过对各个像素点的loss赋予不同的权值
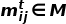 来促进网络更注重对特定区域(前景运动区域)的重构。该权值形成的运动激活图
来促进网络更注重对特定区域(前景运动区域)的重构。该权值形成的运动激活图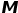 通过图3所示的几个步骤简单得到。其中包括:帧差(提取运动信息),下采样(抑制噪声),激活(稳定响应值),上采样(恢复到重构视频大小)。
通过图3所示的几个步骤简单得到。其中包括:帧差(提取运动信息),下采样(抑制噪声),激活(稳定响应值),上采样(恢复到重构视频大小)。 图3:运动激活图计算过程
图3:运动激活图计算过程实验结果与分析
我们将PRP作为代理任务进行预训练,保留网络主干部分作为下游目标任务的初始化模型,通过评估在目标任务中的性能来验证我们自监督方法的有效性。这里选择了action recognition和video retrieval作为目标任务,并在两种数据集UCF101和HMDB51上分别使用三种网络主干C3D,R3D,R(2+1)D进行验证。通过表1和表2可以看到相比之前的视频自监督方法,PRP在大部分测试中都取得了性能提升。
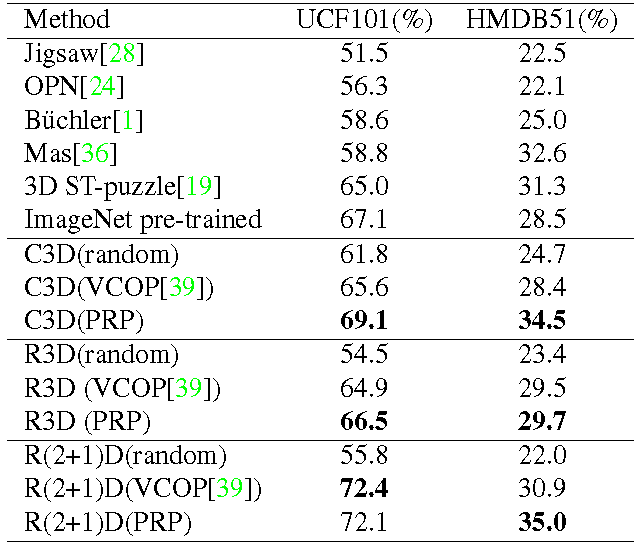 表1:action recognition在UCF101和HMDB51的性能
表1:action recognition在UCF101和HMDB51的性能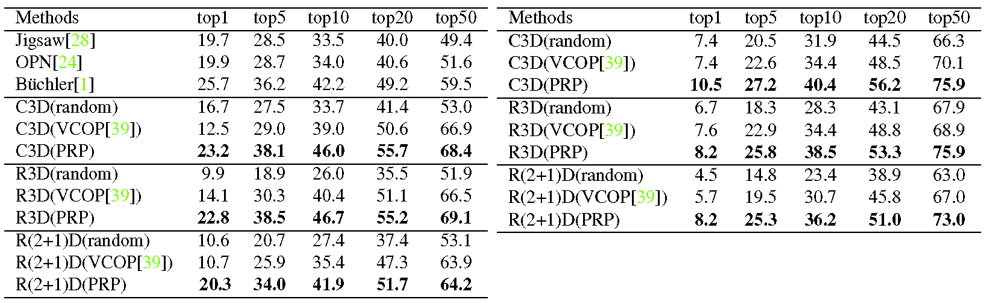 表2:video retrieval分别在UCF101和HMDB51上的性能
表2:video retrieval分别在UCF101和HMDB51上的性能表征可视化
为了进一步理解网络在PRP自监督任务学习到的表征,我们对不同设置下的PPR进行预训练,将从网络主干部分输出的特征激活图可视化,如图4所示:
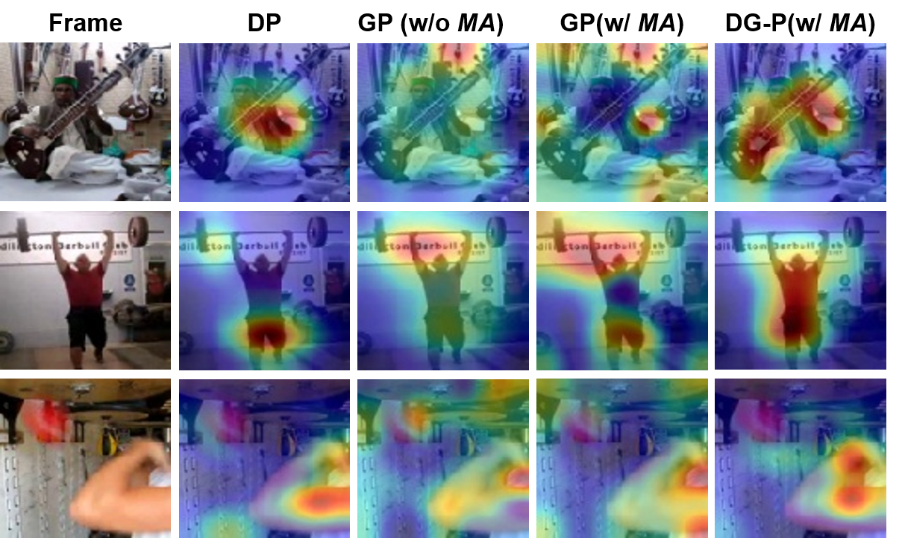 图4:特征激活图可视化
图4:特征激活图可视化DP,GP(w/o MA),GP(w/ MA),DG-P(w/ MA)分别表示只有判别感知,只有生成感知(无motion attention),只有生成感知(有motion attention)以及完整的PRP。可以看到判别感知可以促使网络激活运动剧烈区域,一般包含主要的运动信息;生成感知可以促使网络激活前景附近的上下文区域,可以补充更多细节;结合motion attention的生成感知对前景的运动区域的激活得到增强;而最终结合所有设置的PRP则能够激活一个更加完整的前景运动区域。
总结
我们根据视频的多分辨率特性设计了一种关于播放速率感知的视频自监督任务,其中通过判别感知和生成感知两部分促进了网络对前景运动更全面的理解和对视频表征更完善的学习。最终我们对于不同的目标任务,在不同的数据集上使用不同的网络主干均验证我们方法的有效性。
作者介绍
姚远:国科大3年级在读博士生,主要研究方向深度特征学习、时空特征子监督学习。
刘畅:国科大5年级在读博士生,主要研究方向深度特征学习、时空特征子监督学习。
罗德昭:国科大2年级在读硕士生,主要研究方向深度特征学习、时空特征子监督学习。
周宇:中科院信工所研究员,博士生导师,主要研究方向计算机视觉、目标识别与深度特征学习。
叶齐祥:国科大教授,博士生导师,主要研究方向视觉目标感知、弱监督视觉建模、深度特征学习。
评论