
自监督学习BYOL中的魔鬼BN

极市导读
在复现BYOL的过程中,研究者发现batch normalization在其中起到了关键作用。这强调了正例与负例之间对比的重要性,并有助于理解自监督学习的原理。
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
论文链接:https://arxiv.org/abs/2006.07733
1、Summary
与SimCLR和MoCo等先前的研究不同,这篇来自DeepMind的论文Bootstrap Your Own Lentent(BYOL)展示了一种最先进的方法,可以在没有明显对比损失函数的情况下,对图像表示进行self-supervised(自监督学习),其通过消除损失函数中的负示例来简化训练。我们在复现BYOL的工作中有两个令人惊讶的发现:
1) 当batch normalization被删除时,BYOL的性能通常不比random好;
2)batch normalization的存在隐含地导致了一种形式的contrastive learning(对比学习)。
这些发现强调了学习表征时,正例和负例之间的对比的重要性,并帮助我们更好地理解自监督学习是如何工作以及为什么工作。
Code:https://github.com/untitled-ai/self_supervised
2、Why does self-supervised learning matter?
机器学习通常是在监督下完成的:我们使用由“输入”和“标签”组成的数据集来寻找从输入数据映射到正确答案的最佳函数。相比之下,在自监督学习中,数据集中没有给出“标签”。相反,我们学习一个将输入数据映射到自身的函数,例如:使用图像的右半部分来预测图像的左半部分。
从语言到图像和音频,这种方法已经被证明是成功的。事实上,最新的语言模型,从word2vec到BERT和GPT-3,都是自监督方法的例子。最近,这种方法在音频和图像方面也取得了一些令人难以置信的结果,一些人认为它可能是人智能的重要组成部分。这篇文章主要讨论图像表示的自监督学习。
3、State of the art in self-supervised learning
3.1、Contrastive learning
直到几个月前BYOL发布,性能最好的算法是MoCo和SimCLR。MoCo和SimCLR都是对比学习的例子。
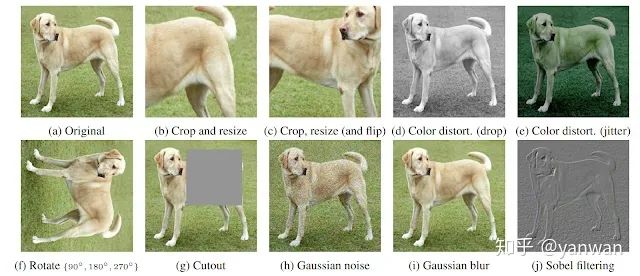
Contrastive learning是训练一个分类器来区分“相似”和“不同”输入数据的过程。特别是对于MoCo和SimCLR,分类器的正面示例是同一图像的修改版本,而反面示例是同一数据集中的其他图像。例如,假设有一张狗的照片。在这种情况下,正面示例可以是该图像的不同作物(见下图),而反面示例可以是来自完全不同图像的作物。
3.2、BYOL: self-supervised learning without contrastive learning? Not exactly.
MoCo和SimCLR在其损失函数中使用了正反两个例子之间的对比学习,而BYOL在损失函数中只使用了正例子。乍一看,在自学习的过程中,他们看起来完全不同。然而,BYOL有效的主要原因似乎是它在进行一种形式的对比学习——只是通过一种间接的机制。
为了更深入地理解BYOL中的这种间接对比学习,我们应该首先回顾一下这些算法是如何工作的。
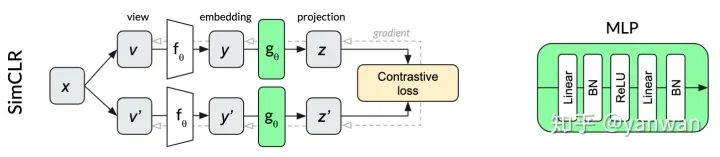
3.3、SimCLR
SimCLR是一种特别优雅的自监督算法,它设法简化了以前的方法,使其基本核心得到简化,并提高了它们的性能。同一图像x的两个变换v和v'通过同一个网络来产生两个投影z和z'。对比损失的目的是最大化来自同一输入x的两个投影的相似性,同时最小化与同一小批量内其他图像投影的相似性。继续我们的dog示例,同一个dog图像的不同作物的投影有望比同一批中其他随机图像中的作物更相似。
SimCLR中用于投影的多层感知器(MLP)在每个线性层之后使用batch normalization。
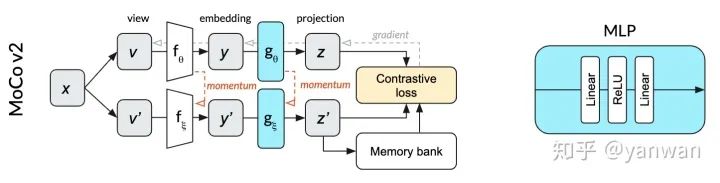
3.4、MoCo
相对于SimCLR,MoCo v2成功地减少了批处理大小(从4096减少到256)和提高性能。与SimCLR不同,图中的顶行和底行表示相同的网络(由θ参数化),MoCo将单个网络拆分为θ参数化的在线网络(顶行)和ξ参数化的动量网络(下排)。在线网络采用随机梯度下降法进行更新,动量网络则基于在线网络权值的指数移动平均值进行更新。动量网络允许MoCo有效地利用过去预测的记忆库作为对比损失的反面例子。这个内存库使批处理的规模小得多。在我们的狗图像插图中,正面的例子是相同图像的狗的作物。反面例子是在过去的小批量中使用的完全不同的图像,它们的投影存储在内存库中。
MoCo v2中用于投影的MLP不使用batch normalization。
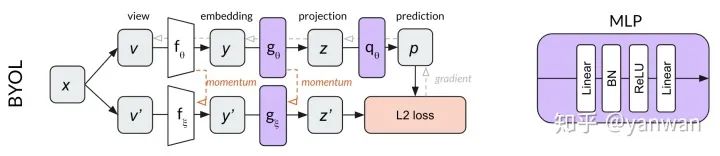
3.5、BYOL
BYOL建立在MoCo动量网络概念的基础上,添加了一个MLP来从z预测p’,而不是使用对比损失,BYOL使用归一化预测p’和目标z’之间的L2 loss。继续使用我们的dog image示例,BYOL尝试将dog图像的两个裁剪转换为相同的表示向量(使p和z’相等)。因为这个损失函数不需要负示例,所以在BYOL中没有内存库的用处。
BYOL中的两个MLP仅在第一个线性层之后使用批处理标准化。
通过上面的描述,通过以上描述,无需在多个不同图像之间进行显式对比的情况,似乎BYOL仍然可以学习。然而,令人惊讶的是,我们发现BYOL不仅在做对比学习,而且对比学习对其成功至关重要。
4、Our surprising results
我们最初使用为MoCo编写的代码在PyTorch中实现了BYOL。当我们开始训练我们的网络时,我们发现我们的网络表现并不比随机网络好。将我们的代码与另一个可用的实现进行比较时,我们发现MLP中缺少批次标准化。我们非常惊讶批处理规范化对于训练BYOL是至关重要的,而mocov2根本不需要它。
在我们的初始测试中,我们在STL-10无监督数据集上训练了ResNet-18和BYOL,使用的是具有动量的SGD,batch size=2563。有关数据扩充的详细信息,请参见附录B。以下是在MLPs中对同一个BYOL算法进行批量标准化和不进行批量标准化的前十个阶段的训练。
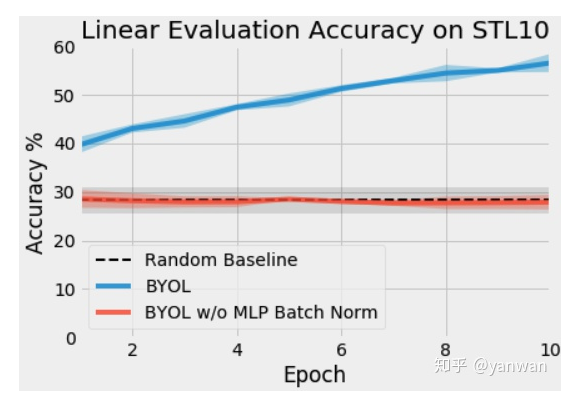
4.1、Why did this happen?
为了研究这种戏剧性的性能变化的原因,我们进行了一些额外的实验。
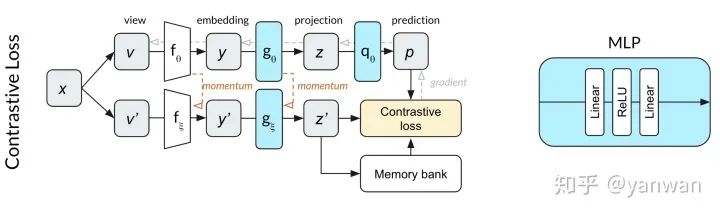
由于预测MLP q与MoCo相比改变了网络深度,我们想知道是否需要批量规范化来规范化该网络。也就是说,虽然MoCo不需要批处理标准化,但是在与额外的预测MLP配对时,MoCo可能确实需要批处理规范化。为了测试这一点,我们开始使用对比损失函数训练上面显示的网络。我们发现,在10个epochs内,网络的性能明显优于随机网络。这一结果使我们怀疑不使用对比损失函数会导致训练依赖于批标准化。
然后我们想知道另一种类型的正常化是否会产生同样的效果。我们将Layer Normalization应用于MLPs,而不是batch normalization,并用BYOL训练网络。在MLPs没有normalization的实验中,性能并不比随机性好。这个结果告诉我们,在同一小批量中激活其他输入对于帮助BYOL查找有用的表示形式至关重要。
接下来,我们想知道在预测MLP g和预测MLP q中是否需要batch normalization,或者两者都需要。我们的实验表明,batch normalization在MLP中是最有用的,但是在任何一个MLP中,网络就可以学习到有用的表示,也就是说:一个mlp中的一个batch normalization足以让网络学习。
4.2、Performance for each variation
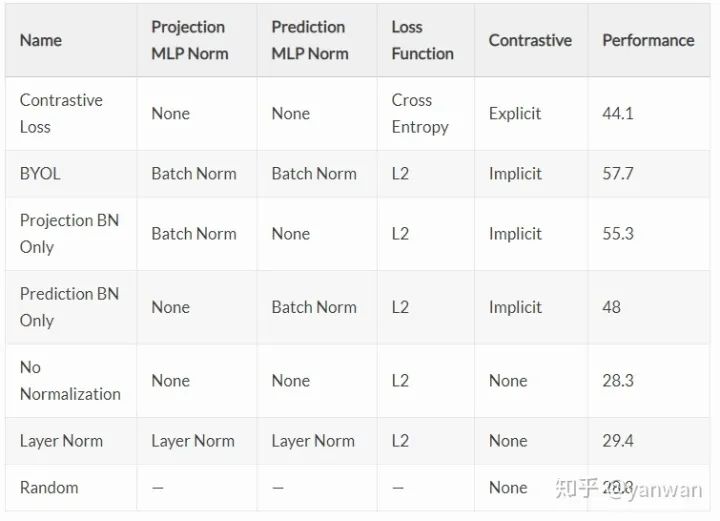
总结目前的研究结果:在没有对比损失函数的情况下,BYOL的训练取决于一个与小批量中其他输入激活相关的batch normalization。
4.3、Why batch normalization is critical in BYOL: mode collapse
对比损失函数中否定例子的一个目的是防止模式崩溃。模式崩溃的一个例子是始终输出[1,0,0,0,…]作为其投影向量z的网络。如果所有投影向量z都相同,则该网络只需学习的单位函数就可以达到完美的预测精度!
在这种情况下,batch normalization的重要性变得更加明显。如果在投影层中使用batch normalization,则投影输出向量z不能塌陷为任何奇异值,如[1,0,0,0,…],因为这正是batch normalization所阻止的。不管输入是怎样,输出都将根据学习到的平均值和标准差重新分配。模式崩溃的预防正是因为在batch normalization之后,小批次中的所有样本都不能采用相同的值。
Batch normalization在预测MLP中也会产生类似的效果。如果小批量输入非常相似,函数将无法学习身份函数:batch normalization将通过向量空间重新分配激活,因此最终层预测都是非常不同的。此函数仅在预测投影向量z'时成功,前提是这些向量z'在表示空间中足够好地分离(即:没有折叠),因为预测p被约束为在小批量中很好地分离。
4.4、Why batch normalization is implicit contrastive learning: all examples are compared to the mode
我们的研究结果似乎与一个简单的结论相一致:防止模式崩溃的一个方法是区分例子之间的共同模式。Batch normalization在小批量实例之间标识这种公共模式,并通过使用小批次中的其他表示作为隐式否定示例来删除它。因此,我们可以将Batch normalization看作是在embedded representations上实现对比学习的一种新方法。
从另一个角度来说,通过批量标准化,BYOL通过询问“这个图像与普通图像有何不同?”。SimCLR和MoCo使用的明确对比方法是通过询问“这两个特定图像之间的区别是什么?”。这两种方法似乎是等价的,因为将一幅图像与许多其他图像进行比较具有与其他图像的平均值相同的效果。例如,原型对比学习就利用了这种等价性。
4.5、Confirming our suspicions
假设上述情况属实(删除batch normalization会导致BYOL模式崩溃)。在这种情况下,我们应该看到所有的表示和投影(z、z'和向量p)都是相等的——这正是我们所看到的。
在训练了上述每个变量后,我们测量了第一输入投影向量z和第二输入投影向量z'的余弦相似性。在训练的第十个epoch后,我们测量了每个小样本的正样本(蓝色)投影之间的平均余弦相似性,以及同一小批次(红色)的阴性样本投影之间的相似性。
在g或q中没有批处理标准化,投影与正示例和负示例(0.9999)高度一致,这表明表示向公共向量塌陷。因为layer normalization不引入对比学习,所以它也会导致正、负表示对齐。对于标准的BYOL训练(即使用batch normalization),我们得到了不同的向量,正如预期的那样。正例(0.88)比负例(0.27)之间的投影更相似。
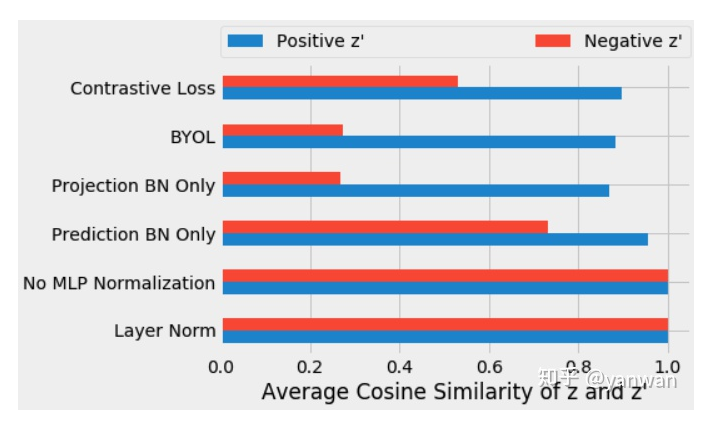
这些结果支持了我们对batch normalization的理解,即隐含地引入了使用小批量统计的对比学习。
5、Additional experiments
5.1、Earlier batch normalization layers have the same effect (eventually)
到目前为止,我们只看到了前10个时期的训练。当我们训练更长时间时,我们发现ResNet编码器中的batch normalization与MLPs中的batch normalization具有相似的效果。在编码器中(而不是在MLPs中)进行batch normalization后,网络首先学习具有折叠表示的函数,然后逐渐开始从正示例中分离负示例。
5.2、Removing all batch normalization completely prevents learning — unless at least one technique is used to prevent mode collapse.
当我们从ResNet编码器中删除batch normalization并使用SGD训练网络时,它无法学习任何东西(正是由于我们上面描述的原因)。
然而,当我们联系到作者时,他们善意地指出:在原来的BYOL论文,并没有使用完全相同的设置。通过从SGD切换到分层学习速率自适应(LARS)或增加权值衰减,我们的网络能够再次学习(尽管性能显著下降)。
我们研究了每一种技术,发现它们只是防止模式崩溃的替代方法。此外,它们自身的鲁棒性明显降低——它们依赖于仔细的超参数调整,而没有这种调整,它们很容易出现模式崩溃,相应地,它们的性能也很糟糕。因此,我们得出结论,batch normalization似乎是防止BYOL模式崩溃的最健壮的技术。
6、Conclusions
我们发现非常有趣的是,即使在损失函数中没有负样本,batch normalization也隐含地引入了BYOL中的对比学习。这一发现在事后看来是有意义的——当模式崩溃时没有学习,而batch normalization使模式崩溃变得不可能!无论是将不同的图像相互对比,还是将每个图像与所有图像的平均值进行对比,学习的一个主要部分是了解事物之间的差异。
除了阐明了batch normalization在对比学习中的工作原理外,本文还可以作为一堂关于batch normalization如何产生意想不到的副作用的一课。通过batch normalization,网络输出不再是学习相应输入的纯函数。由于这个和其他原因,在训练中避免batch normalization可能是值得的。我们建议其他实践者也许应该默认使用layer normalization或者weight standardization with group normalization。
相反,这也是未来工作的一个有趣的途径。与其因为这种隐式对比效应而避免batch normalization,不如直接利用它,允许隐式对比学习在最后一层以外的层进行。一个有趣的开放性问题是,batch normalization在训练神经网络方面的成功有多大程度上是由这种内部表示的分离直接引起的。
最后,我们发现有趣的是,即使在没有显式对比损失或隐式对比机制的情况下,BYOL(使用正确的超参数)也可以通过batch normalization学习一些东西。虽然我们不建议任何实践者在实践中使用这些网络,但我们认为它们是对该领域的一个新颖而有趣的贡献,并且他们的行为潜在地提供了一个价值点,为什么这些技术(重量衰减、重量标准化和LAR)如此有效。
参考资料
[1]https://untitled-ai.github.io/understanding-self-supervised-contrastive-learning.html#fn:ssup
[2]Prototypical Contrastive Learning
推荐阅读
