
开源|AAAI‘21杰出论文-三维重建新探索:解决数据依赖问题,让自监督信号更可靠!

极市导读
现有的方法都是假设不同视图之间的对应点具有相同的颜色,这在实践中并不总是正确的。这可能导致不可靠的自监督信号,并损害最终的重建性能。为了解决这个问题,本文提出了一个以语义共切分和数据扩充为指导的更可靠的监控框架。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

导读
目标读者:对多视图立体几何(Multi-view stereo, MVS)感兴趣或有一定了解的人。 论文作者:深圳中科院先进技术研究院以及华南理工大学的研究团队。 论文:https://www.aaai.org/AAAI21Papers/AAAI-2549.XuH.pdf Arxiv: https://arxiv.org/abs/2104.05374 代码:https://github.com/ToughStoneX/Self-Supervised-MVS
背景
一直以来,基于多视图立体几何(Multi-view stereo, MVS)的三维重建都是一个广受关注的主题。近年来深度学习方法的发展,催生了一系列传统MVS方法与深度学习方法结合的工作,例如:MVSNet[1]、R-MVSNet[2]、CascadeMVSNet[3]等等。以MVSNet为代表这一系列方法,通过可微单应性投影(DIfferentiable Homography)将立体几何的匹配关系嵌入到代价匹配体(Cost Volume)中,以实现端到端的神经网络。网络的输入是任意数量的多视角图像以及相机的内外参数,输出是某一个参考视角下的深度图。相比于传统的MVS中的立体匹配方法,这些基于深度学习改进的方法能更好地重建稠密的三维点云信息,并对于弱纹理及噪声干扰的情况鲁棒性更强。在DTU[4]、Tanks&Temples[5]等公开数据集上都取得了不错的效果。但是,一个不可忽视的问题就是,这些深度学习方法依赖于大量的3D场景的Ground Truth数据。这会给其在现实场景的应用带来不少的麻烦,因为采集3D Ground Truth数据的成本相对高昂。由此,整个研究社区也开始着眼于无监督/自监督学习在MVS中的应用,以求摆脱对Ground Truth的依赖。
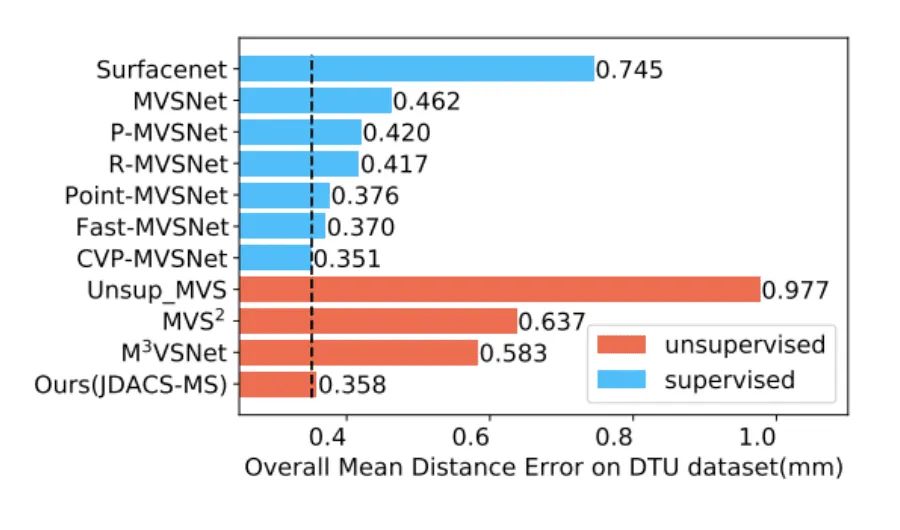
现有的自监督学习方法的基本思路是将需要Ground Truth的深度估计的回归任务转换为一个无监督的图像重建的代理任务。根据网络预测的参考视角下的深度图和其他视角图像通过单应性映射重建为参考视角的图像,只有预测的深度值正确时,重建图像才会尽可能与原图相似。尽管此前的无监督方法进一步地改进自监督方法并取得了不错的结果,例如:Unsup_MVS[6]、MVS[7]、MVSNet[8]等,但是如下图所示,此前的无监督/自监督方法与有监督方法依然存在很明显的差异。我们的目标是提升自监督MVS方法的性能,但是在介绍具体方法之前,我们不妨先回顾一下自监督MVS方法本身是否存在一些缺陷导致了有监督与无监督方法的效果差异?
核心问题
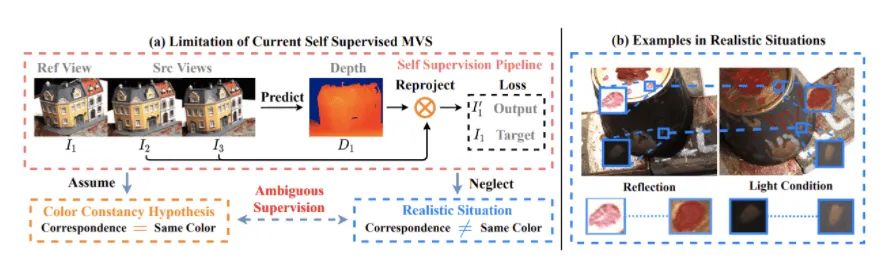
由上图(a)可见,以图像重建任务作为代理任务的自监督MVS方法都依赖于一个比较粗糙的假设,即颜色一致性假设(Color Constancy Hypothesis)。该假设认为:多视图之间的匹配点具有相同的颜色。然而,由上图(b)中可见,在实际场景下,多视角图像的颜色值可能被各种外界因素干扰而导致匹配点具有不同的颜色,例如:光照变化、反光,噪声干扰等等。因此,基于颜色一致性假设的自监督信号在这些情况下很有可能引入错误的监督信号,反而干扰模型的效果。我们将这类问题称之为:颜色一致性歧义问题(Color Constancy Ambiguity)。那么,我们该如何解决这类问题呢?
方法
自监督MVS中的颜色一致性歧义问题,其根本原因在于图像重建这个代理任务仅仅考虑了颜色空间上的对应关系(Correspondence)。而这种基于RGB像素值差异的度量指标在表示多视图之间的对应关系时不够可靠,也限制了自监督方法的性能。那么,很自然地我们可以考虑考虑如何引入额外的先验知识,以提供一个更鲁棒的代理任务作为自监督信号。由此可以分为以下两点:
语义一致性:引入抽象的语义信息来提供鲁棒地对应性关系,将图像重建任务替换为语义分割图的重建任务构建自监督信号。 数据增强一致性:在自监督训练中引入数据增强,来提升网络针对不同颜色变化的鲁棒性。
但是在构建自监督信号时,依然存在一些不可忽视的问题:
对于语义一致性先验来说,获取语义分割图标注的成本是非常高昂的。此外训练集中的场景是动态变化的,我们无法像自动驾驶任务那样明确地定义好所有场景中所有元素的语义类别。这也是此前的自监督方法中不曾使用语义信息构建自监督损失的原因。为此,我们通过对多视角图像进行无监督的协同分割(Co-Segmentation),以挖掘出多视角图像之间的共有语义信息来构建自监督损失。 对于数据增强一致性先验来说,数据增强本身就会带来颜色分布的改变,换言之可能反过来引发颜色一致性歧义的问题,干扰自监督信号。为此,我们将单分支的自监督训练框架划分为双分支,使用原始分支的预测结果作为伪标签来监督数据增强分支的预测结果。
基于此,我们提出了一个新的自监督MVS训练框架:JDACS,如下图所示。
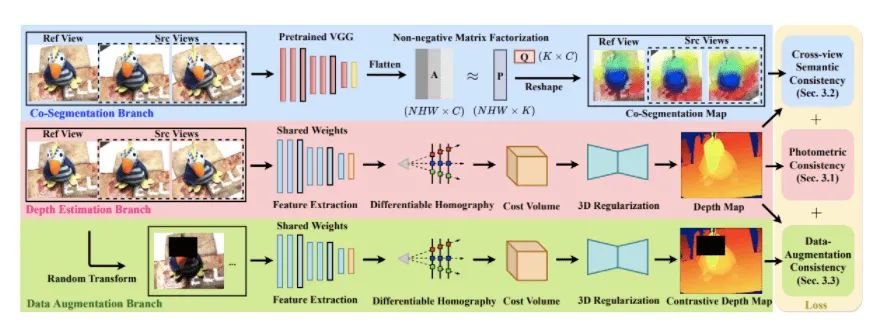
整个框架分为三个分支:
深度估计分支:输入参考视角(Reference View)以及源视角图像(Source View)到网络中,利用预测的深度图和源视角图像来重建参考视角图像。比较参考视角下重建图像和原图的差异,构建光度立体一致性损失(Photometric Consistency)。 协同分割分支:将输入多视图送入一个预训练的VGG网络,对其特征图进行非负矩阵分解(NMF)。由于NMF的正交约束,其过程可以看做多多视图之间的共有语义进行聚类,并输出协同分割图。随后通过预测的深度图和多视角的协同分割图构建分割图像重建任务,即语义一致性损失。 数据增强分支:对原始多视图进行随机的数据增强,并送入到网络中。以深度估计分支预测的深度图作为伪标签来监督数据增强分支的预测结果,构建数据增强一致性损失。
实验结果
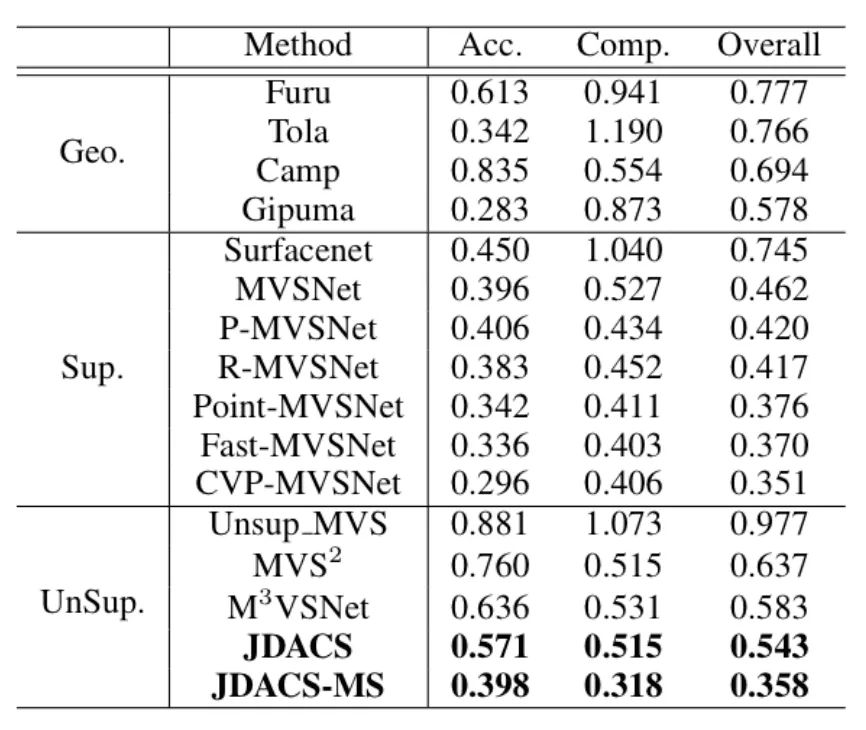
DTU数据集上的定量实验结果:
DTU数据集上的定性实验结果:

Tanks&Temples数据集上的定量实验结果:

Tanks&Temples数据集上的定性实验结果:

有监督与无监督训练效果对比:

结语
这篇工作是我们对于自监督MVS的一些探索,重新思考了自监督信号的有效性,因为此前的基于图像重建代理任务的自监督方法都是基于颜色一致性假设。然而,现实场景中天然存在的颜色干扰会干扰到自监督训练,并引发颜色一致性歧义问题,导致训练过程中引入了错误的监督信号。我们提出的自监督MVS框架则试图引入额外的Correspondence先验知识来使得自监督信号更加可靠。一方面,通过无监督地挖掘协同分割图中的语义一致性信息来引入抽象的匹配关系;另一方面,通过双分支结构引入数据增强一致性的先验来提升网络应对噪声的鲁棒性。从实验结果可以看出,我们相比于此前的自监督MVS方法有一定的性能提升。
当然,我们提出的方法依然存在一些待解决的问题:首先,在非纹理区域如黑色/白色背景等等,是不存在有效的自监督信号的,因为所有背景像素点的颜色乃至语义都是相同的;其次,我们通过协同分割的方法只挖掘出了相对粗糙的语义信息,这是由于基于ImageNet分类任务预训练的VGG模型并不适用于需要关注到细节语义的分割任务。
最后附上我们论文的引用:
@inproceedings{xu2021self,title={Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-Augmentation},author={Xu, Hongbin and Zhou, Zhipeng and Qiao, Yu and Kang, Wenxiong and Wu, Qiuxia},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},year={2021}}
参考文献
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“目标检测竞赛”获取目标检测竞赛经验资源~

# 极市原创作者激励计划 #
