
前沿热点: 自监督学习图鉴
Yann Lecun 曾在演讲中以蛋糕来类明自监督学习。他在演讲中说,
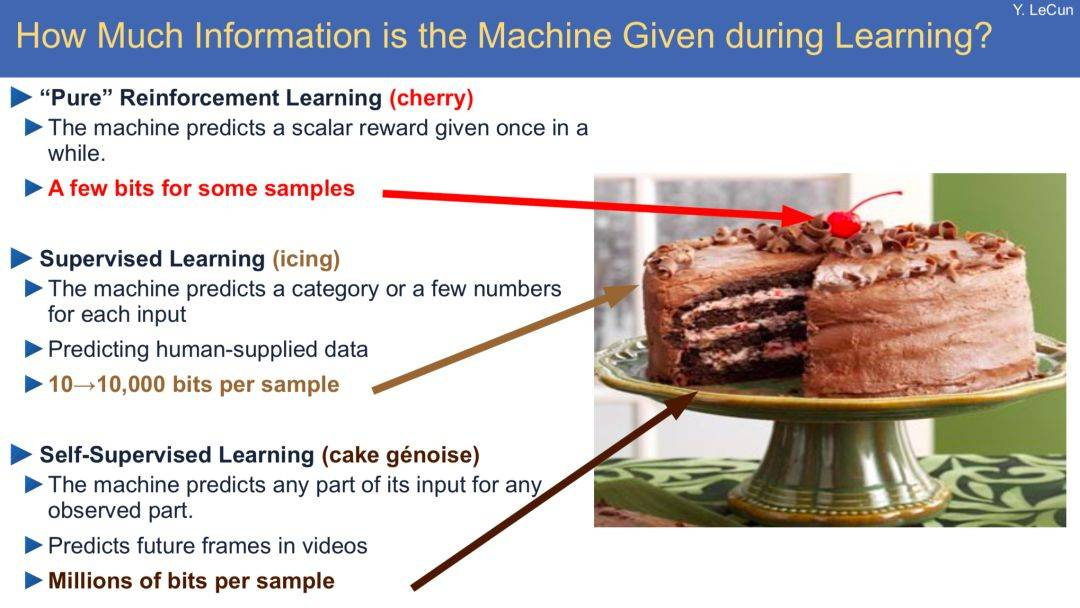
大牛的比喻不用过于较真,而且这个说法也存在争议。但我们可以看到,在自然语言处理领域中应用自监督学习的思想确实已经取得了很大进展(例如 Word2Vec,Glove,ELMO,BERT)。
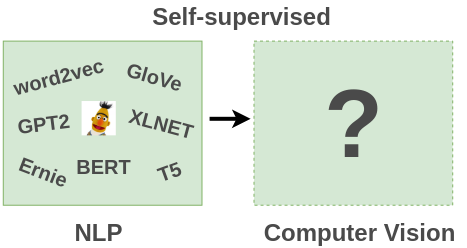
由于对自监督学习在图像领域的进展感兴趣,因此对一些相关文献做了调研和总结。这篇文章将解释什么是自监督学习,并总结自监督学习在图像领域中的应用。
1Why 自监督学习?
要用深度神经网络进行监督学习,需要足够的带标签数据。然而,人工标注大量数据既耗时又费力。另外,还有一些领域,例如医学领域,要获取足够的数据本身就是一个挑战。因此,当前监督学习范式的一个主要瓶颈就是标注数据或者叫标签生成。
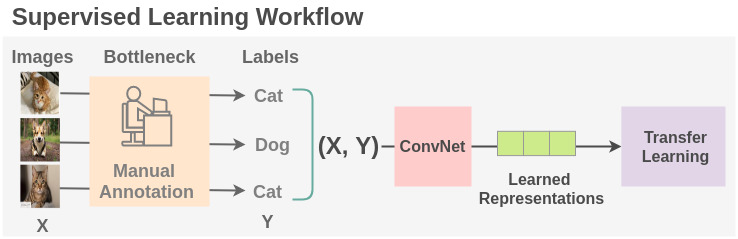
2自监督学习
自监督学习是一种提出以下问题并将一个无监督学习问题转化为监督问题的方法:
如何设计一个任务,从现有图像集中生成几乎无限多的标签,以便用来学习图像的表示呢?
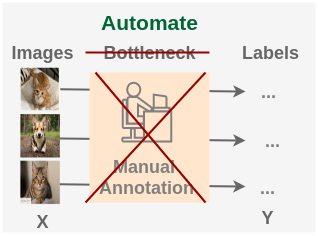
什么意思呢?图像集本身没有标签,只能干点无监督的任务,但是我们还是想用一个网络去学习图像的表示(提取它的特征),怎么办呢?那就用图像自身来制造 ‘标签’,这不就转化为一个监督学习的问题了吗!
在自监督学习中,我们通过创造性地利用数据的某些属性来设置伪监督任务以替代人类标注那个环节。例如,在这里我们可以将图像旋转 0/90/180/270 度,然后训练模型来预测正确的旋转,而不是显式地将图像标注为猫或者狗等类别。我们可以从互联网上免费提供的数百万张图像中生成几乎无限的训练数据。

一旦从数百万张图像中学习图像的表示后,我们可以使用迁移学习实现在一些监督任务(例如猫与狗的图像分类)上用少量几张实例图像进行微调。
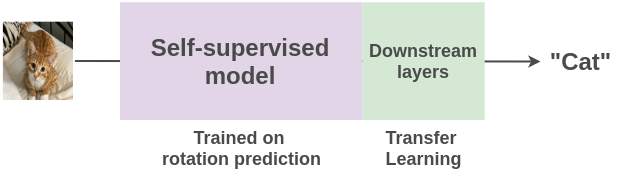
让我们来了解一下近年来研究人员提出的利用图像和视频属性的各种方法,以及应用自监督学习来实现表示学习。下面分别从图片和视频两方面来介绍自监督学习。
图像篇

3图像重构
〄图像着色
我们将免费可获取的数百万张彩色图像转化为灰度图,来构建(灰度图, 彩色图)图像对。
我们可以使用基于全卷积神经网络的编码器-解码器(encoder-decoder)网络架构,并计算预测彩色图像与实际彩色图像之间的 L2 损失。
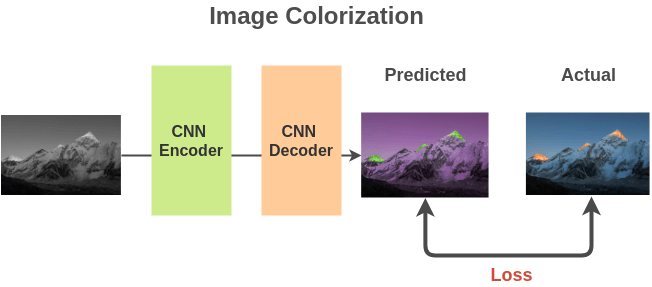
为了完成此任务,模型需要学习图像的表示,即图像中有哪些物体及相关 part,以便用相同颜色来绘制这些 part。模型学习到的图像表示将用于下游任务。
Colorful Image Colorization
Real-Time User-Guided Image Colorization with Learned Deep Priors
Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic
Image Colorization with Simultaneous Classification
〄图像超分辨率
基于 GAN 的模型(例如 SRGAN)非常适合这样的任务。生成器使用全卷积网络获取低分辨率图像并输出高分辨率图像。使用均方误差和内容损失来比较实际图像和生成的图像,以模仿人类对图像的质量评估。二分类判别器会将图像识别为真实的高分辨率图像(1)还是伪造的超分辨率图像(0)。这两个模型之间的相互作用导致生成器不断学习最终能够生成具有精细细节的图像。
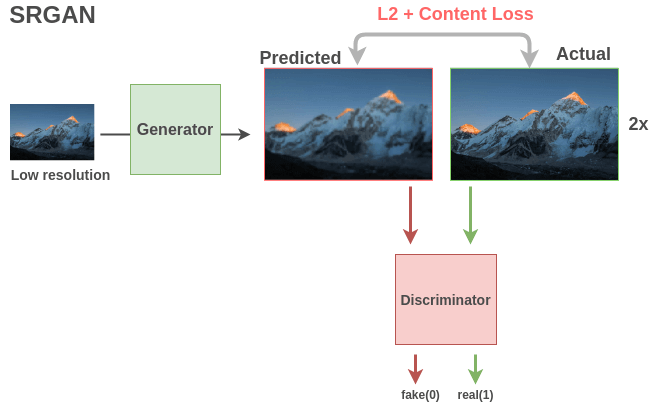
生成器和判别器都学习到了可用于下游任务的图像语义特征。
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
〄图像修复
通过随机删除图像的部分区域来构建(损坏的, 修复的)图像对。
与超分辨率任务相似,我们可以利用基于 GAN 架构,在该架构中生成器可以学习重建图像,而判别器则辨别真实图像和生成图像。
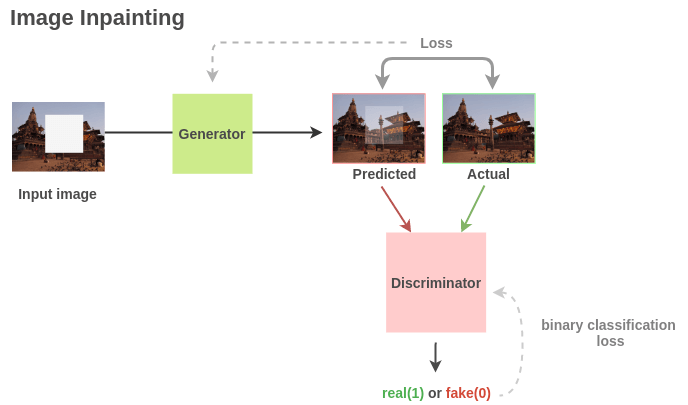
对于下游任务,Pathak 等人的工作说明在 PASCAL VOC 2012 语义分割任务上,生成器学到的语义特征相比随机初始化有 10.2% 的提升,在分类和物体检测任务上则有 < 4% 的提升。
Context encoders: Feature learning by inpainting
〄交叉通道预测
用图像的一个通道预测另一个通道并将它们重新组合以重建原始图像。
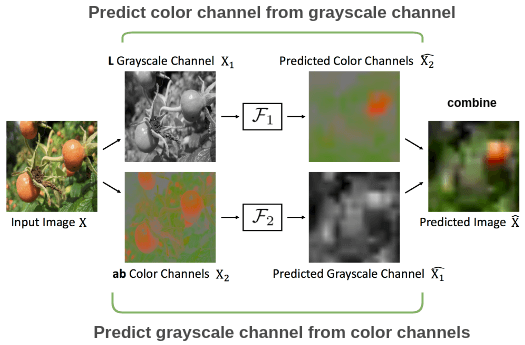
Split-Brain Autoencoder 论文的示例。张等人在论文 Split-Brain Autoencoder 中使用了这种想法。为了理解这种思想,让我们以番茄的彩色图像为例。
对于彩色图像,我们可以将其分为灰度和彩色通道。对于灰度通道,预测彩色通道;对于颜色通道,预测灰度通道。将两个预测通道
同样的设置也可以应用于具有深度的图像,其中我们使用来自 RGB-HHA 图像的颜色通道和深度通道相互预测并比较输出图像和原始图像。
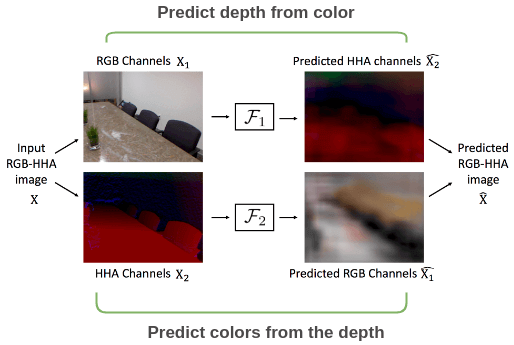
Split-Brain Autoencoder 论文的示例。Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction
4常识任务
〄图像拼图
通过随机打乱图像 patch 构建训练拼图对(随机, 有序)。

即使只有 9 个 patch,也可能存在 362880 个排列方式。为了克服这个问题,仅仅选取具有最大汉明距离的 64 个排列。
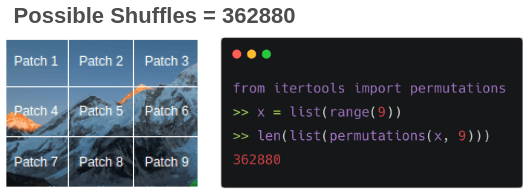
可以使用排列来改变图像,总共用到 64 个排列,其中一个如下图所示,
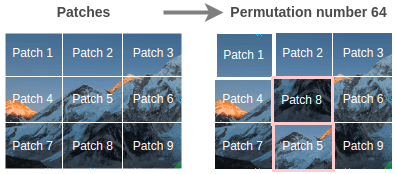
为了恢复图像,Noroozi 等人提出了一个称为上下文无关的神经网络(CFN),如下图所示。在这里,各个 patch 通过相同的共享权值的 siamese 卷积层传递。然后,将这些特征组合在一个全连接的层中。在输出中,模型必须预测在 64 个可能的排列类别中使用了哪个排列。
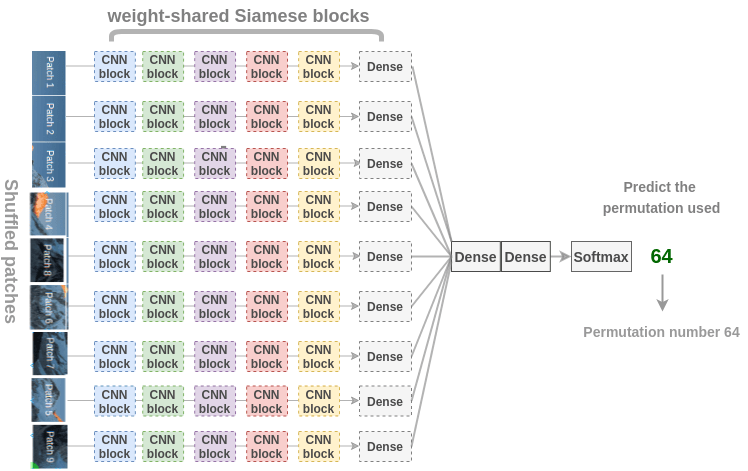
为了解决拼图问题,模型需要学习识别 parts 是如何组装成物体的,物体不同 parts 的相对位置以及物体的形状。因此,这些表示对于下游的分类和检测任务是有用的。
Unsupervised learning of visual representations by solving jigsaw puzzles
〄内容预测
从不带标记的大型图像集中随机获取一个图像 patch 及其相邻 patch 来构建训练对(图像 patch, 相邻 patch)。
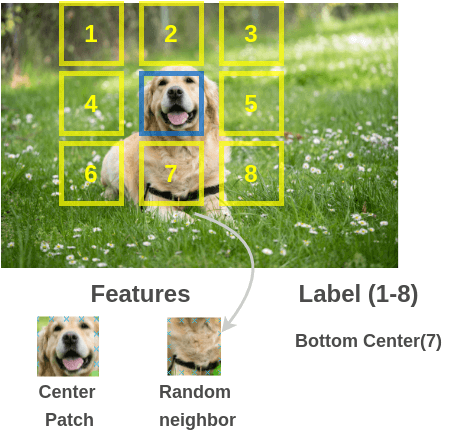
为了解决这个任务,Doersch 等人使用了类似于拼图游戏的架构。通过两个 siamese 卷积神经网络传递图像 patch 来提取特征,连接特征并对 8 个类进行分类,表示 8 个可能的相邻位置。
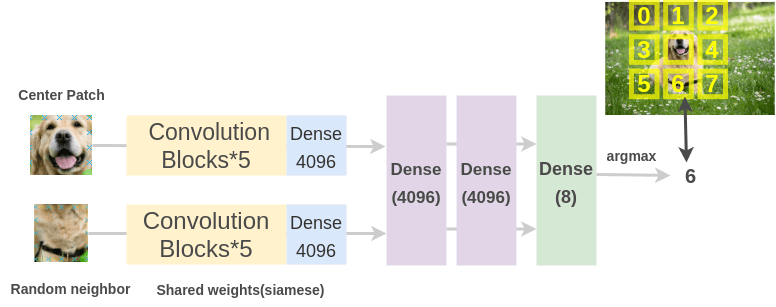
Unsupervised Visual Representation Learning by Context Prediction
〄几何变换识别
不带标记的大型图像集中随机旋转图像(0、90、180、270)度来构建训练对(旋转图像,旋转角度)。
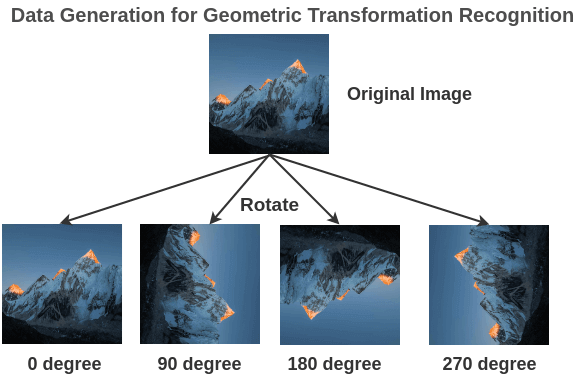
为了解决这个任务, Gidaris 等人提出了一种网络架构,将旋转后的图像输入一个卷积神经网络,网络把它分成 4 类(0、90、270、360)度。
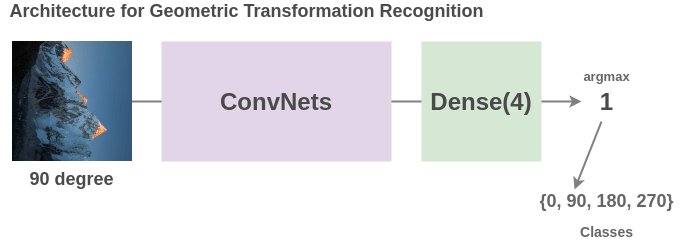
虽然这是一个非常简单的想法,但模型必须理解图像中物体的位置、类型和姿态才能完成这项任务,因此,学习到的表示方法对后续任务非常有用。
Unsupervised Representation Learning by Predicting Image Rotations
5自动标签生成
〄图像聚类
通过对不带标记的大型图像集进行聚类来构建训练数据对(图像, 簇编号)。
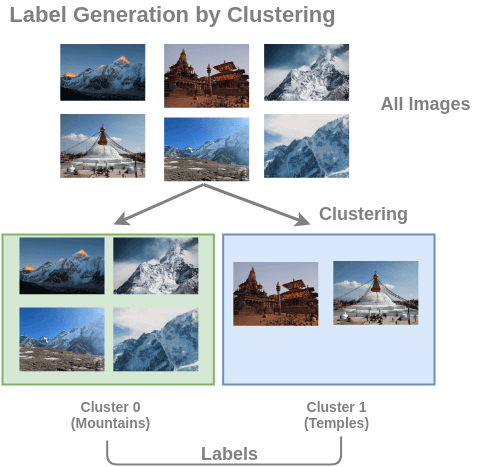
为了解决这个任务,Caron 等人提出了一种称为 deep clustering 的架构。在此,首先对图像进行聚类,然后将簇用作类。ConvNet 的任务是预测输入图像的簇标签。
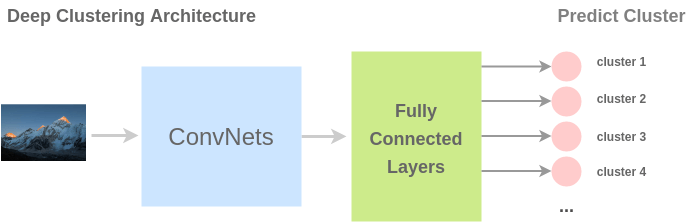
Deep clustering for unsupervised learning of visual features Self-labelling via simultaneous clustering and representation learning CliqueCNN: Deep Unsupervised Exemplar Learning
〄图像合成
通过使用游戏引擎合成图像并将其转换成真实图像来构建训练数据对(图像, 属性)。

为了解决这个任务,Ren 等人提出一个架构,使用共享权值的卷积网络在合成和真实图像上进行训练,然后鉴别器学习辨别合成图像是否是真实图像。由于对抗性,真实图像和合成图像之间的共享表示随着训练变得更好。
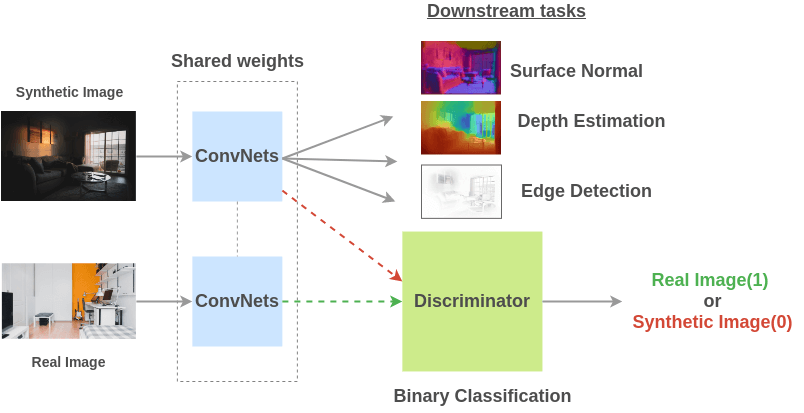
Cross-Domain Self-supervised Multi-task Feature Learning using Synthetic Imagery
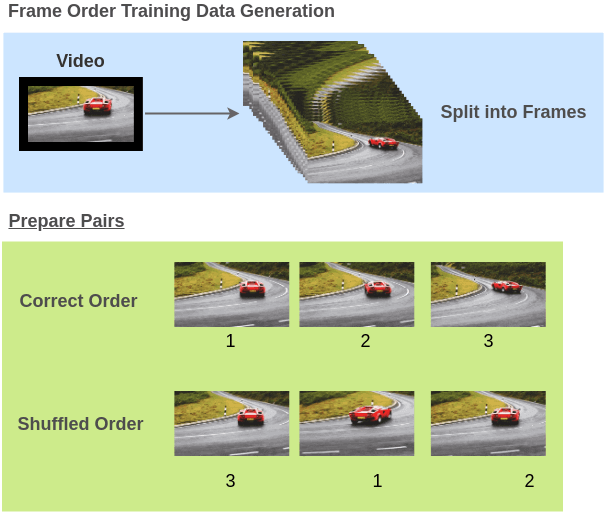
〄视频帧顺序验证
将运动对象的视频帧顺序打乱来构建训练对(视频帧, 正确/不正确的顺序)。
为了解决这个任务,Misra 等人提出了一个架构,其中视频帧通过共享权重的 ConvNets 传递,模型必须确定帧的顺序是否正确。在此过程中,该模型不仅学习了空间特征,还考虑了时间特征。
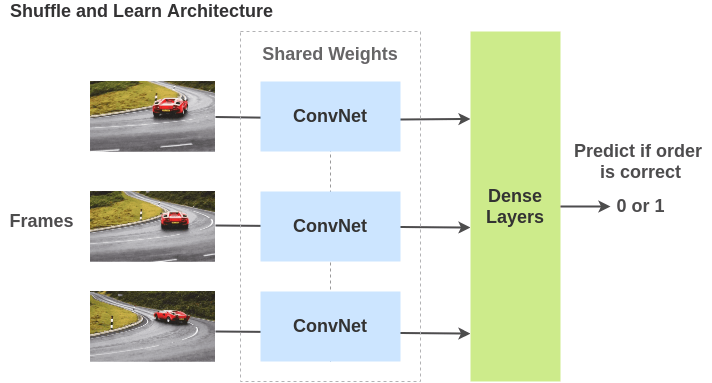
Shuffle and Learn: Unsupervised Learning using Temporal Order Verification Self-Supervised Video Representation Learning With Odd-One-Out Networks
6小结

⟳参考资料⟲
Jing et al.: https://arxiv.org/abs/1902.06162
[2]Amit Chaudhary: https://amitness.com/2020/02/illustrated-self-supervised-learning
这么好的知识藏着掖着
