Yann LeCun 新作!大幅超越 MAE,图像语义表示卷出新高度

论文标题: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture 论文链接: https://arxiv.org/pdf/2301.08243.pdf
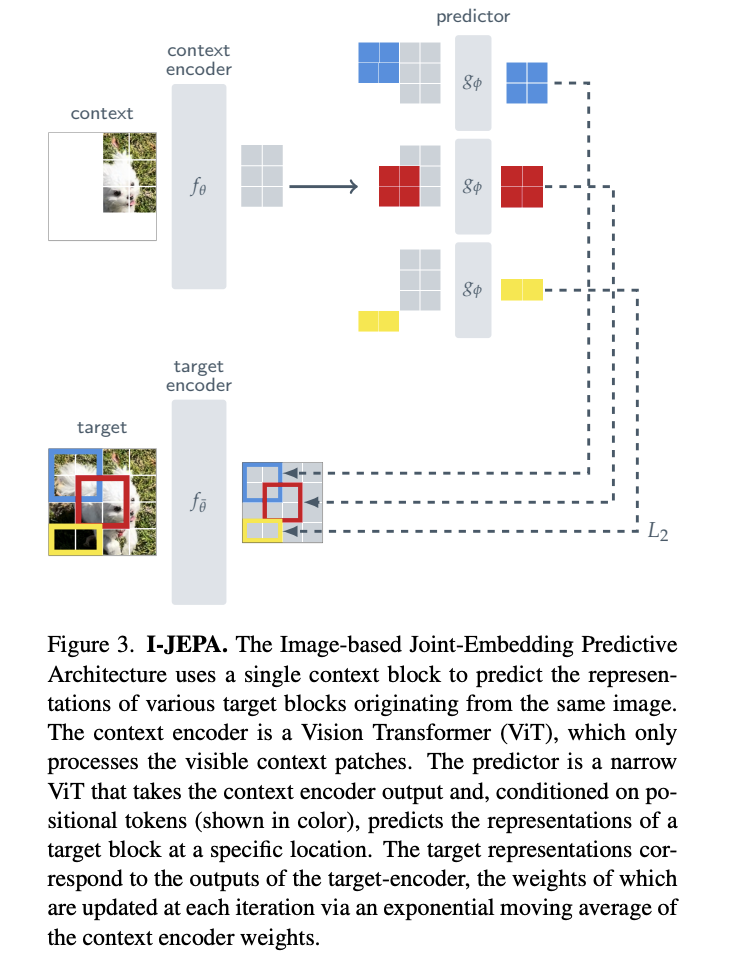
图像分类

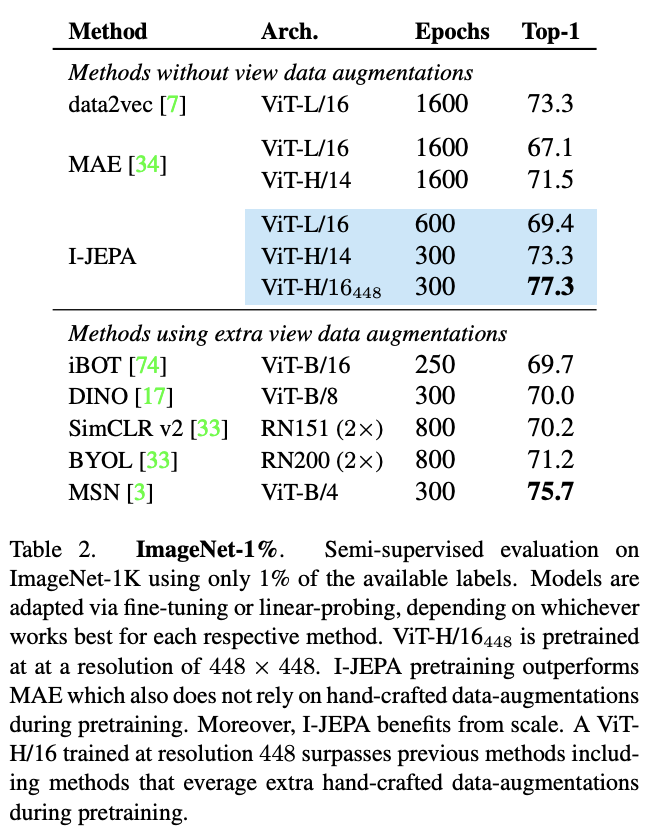
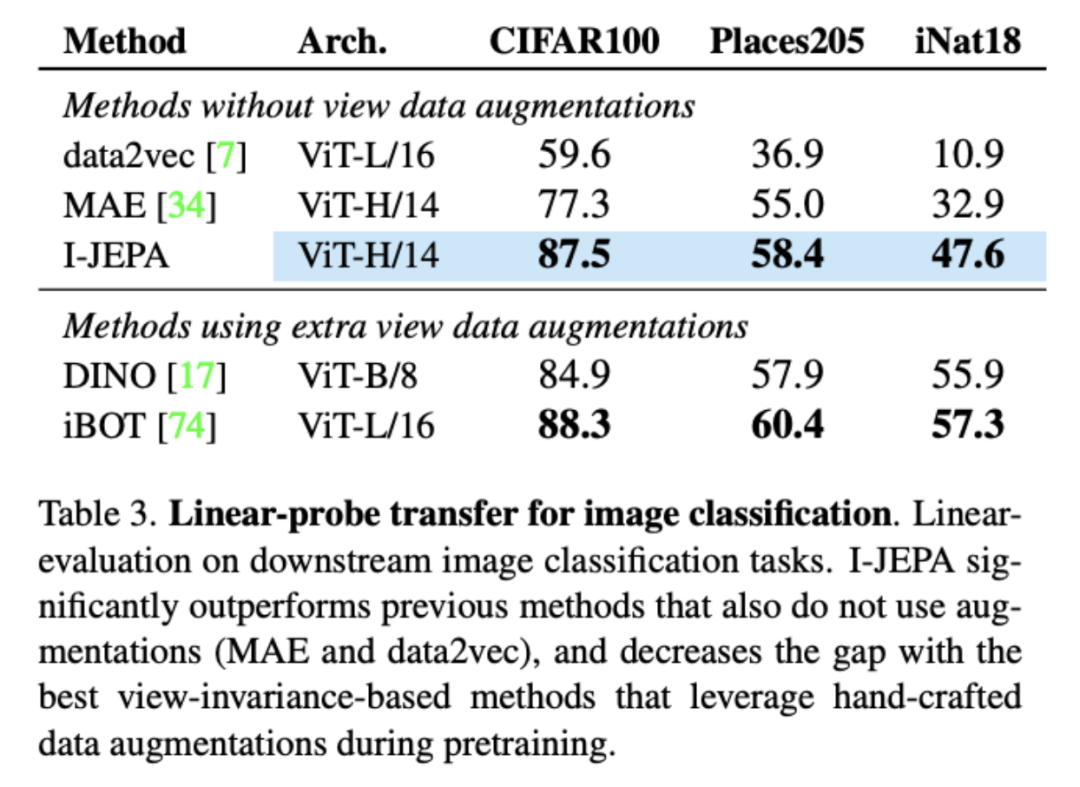
Local Prediction Tasks
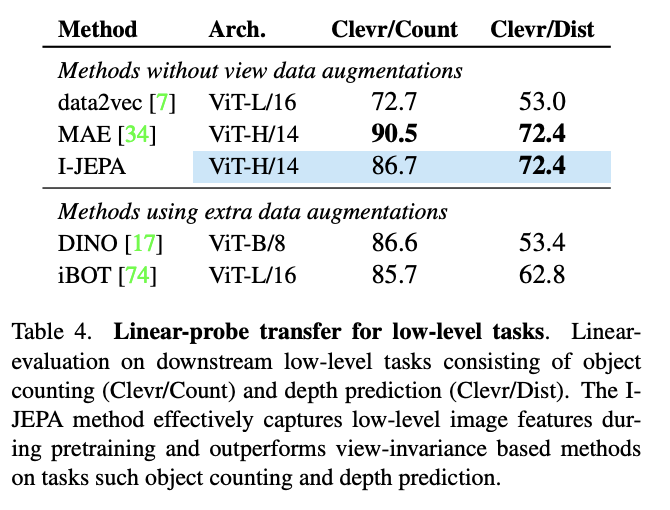
扩展性

预测器可视化

评论
 下载APP
下载APP论文标题: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture 论文链接: https://arxiv.org/pdf/2301.08243.pdf