
无监督学习的12个最重要的算法介绍及其用例总结
来源:Deephub IMBA
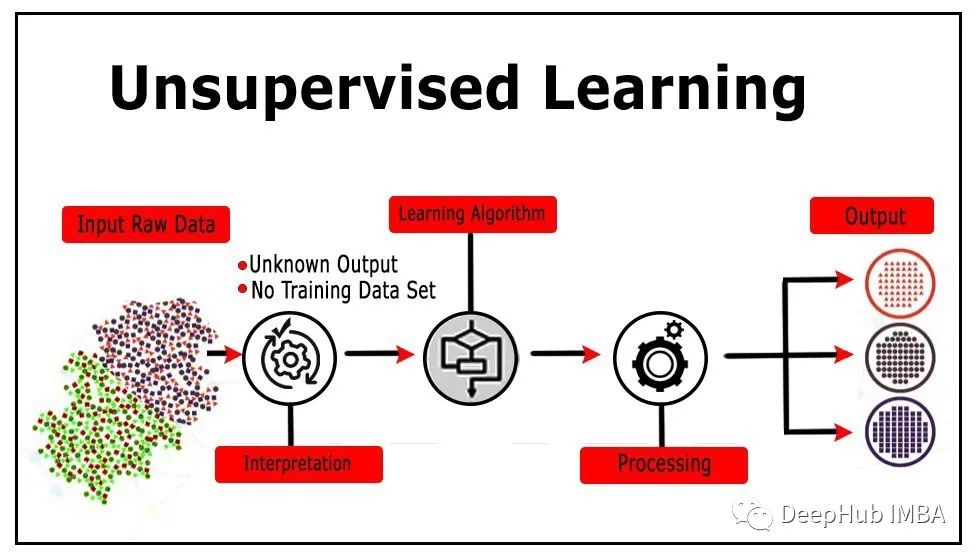
以上就是无监督学习中常用的算法, 如果你对他们感兴趣,请详细查看下面的引用(很长,建议之查看感兴趣的)
1.An introduction to Q-Learning: reinforcement learning: https://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/
2. Q-learning video walkthrough: https://www.youtube.com/watch?v=4dcgjcuR-1o
3. Unsupervised learning: clustering with DBSCAN: https://web.cs.dal.ca/~kallada/stat2450/lectures/Lecture15.pdf
4. DBSCAN clustering algorithm in machine learning: https://www.kdnuggets.com/2020/04/dbscan-clustering-algorithm-machine-learning.html
5. Unsupervised Learning of Global Factors in Deep Generative Models. arXiv:2012.08234
6. Harshvardhan GM, Mahendra Kumar Gourisaria, Manjusha Pandey, Siddharth Swarup Rautaray, A comprehensive survey and analysis of generative models in machine learning, Computer Science Review, Volume 38, 2020, 100285, ISSN 1574–0137, https://doi.org/10.1016/j.cosrev.2020.100285.
7. Boosting: https://aws.amazon.com/what-is/boosting/
8. Bagging: https://www.ibm.com/cloud/learn/bagging
9. Breiman, L. (2001). Random forests. Machine learning, 45(1), 5–32.
10. Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction (2nd ed.). Springer Science & Business Media.
11. Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
12. Machine Learning Techniques for the Segmentation of Tomographic Image Data of Functional Materials. https://www.frontiersin.org/articles/10.3389/fmats.2019.00145/full
13. Link Prediction in Complex Networks: A Survey. https://arxiv.org/pdf/1010.0725.pdf
14. Link Prediction. https://neo4j.com/developer/graph-data-science/link-prediction/
15. Preferential Attachment in Online Networks: Measurement and Explanations. https://arxiv.org/pdf/1303.6271.pdf
16. A novel similarity measure for mining missing links in long-path networks. https://arxiv.org/pdf/2110.05008.pdf
17. Fast Random Walk with Restart and Its Applications. https://www.cs.cmu.edu/~christos/PUBLICATIONS/icdm06-rwr.pdf
18. Q-Learning: A Tutorial and Extensions. https://link.springer.com/chapter/10.1007/978-1-4615-6099-9_3
19. Temporal-Difference Learning: https://web.stanford.edu/group/pdplab/pdphandbook/handbookch10.html
20. Machine Learning Techniques for Anomaly Detection: An Overview. https://www.researchgate.net/profile/Salima-Benqdara/publication/325049804_Machine_Learning_Techniques_for_Anomaly_Detection_An_Overview/links/5af3569b4585157136c919d8/Machine-Learning-Techniques-for-Anomaly-Detection-An-Overview.pdf
21. Machine Learning Approaches to Network Anomaly Detection. https://www.usenix.org/legacy/event/sysml07/tech/full_papers/ahmed/ahmed.pdf?ref=driverlayer.com/web
22. Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective (1st ed.). MIT Press.
23. A density-based algorithm for discovering clusters in large spatial …. https://www.osti.gov/biblio/421283.
24. Rakesh, Agrawal, and Ramakrishnan Srikant. “Fast Algorithms for Mining Association Rules.” https://www.researchgate.net/publication/2460430_Fast_Algorithms_for_Mining_Association_Rules
25. Parker, Iqbal. Machine Learning: Algorithms, Real-World Applications, and Research Directions. https://link.springer.com/article/10.1007/s42979-021-00592-x
26. Anomaly Detection Using Multi Agent Systems. https://users.encs.concordia.ca/~abdelw/papers/Khosravifar_MSc_S2018.pdf
27. A Systematic Survey on Deep Generative Models for Graph Generation | DeepAI. https://deepai.org/publication/a-systematic-survey-on-deep-generative-models-for-graph-generation
28. Hierarchical K-Means Clustering: Optimize Clusters — Datanovia. https://www.datanovia.com/en/lessons/hierarchical-k-means-clustering-optimize-clusters/
加入知识星球【我们谈论数据科学】
500+小伙伴一起学习!
· 推荐阅读 ·
