
机器学习最优化算法(全面总结)
导言
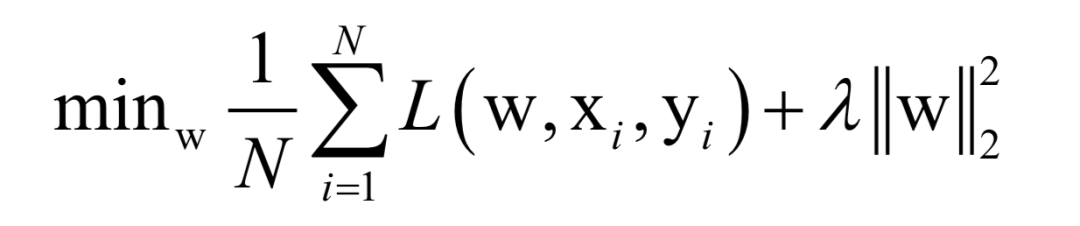
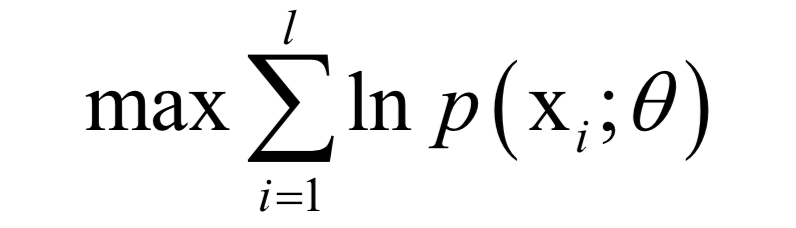
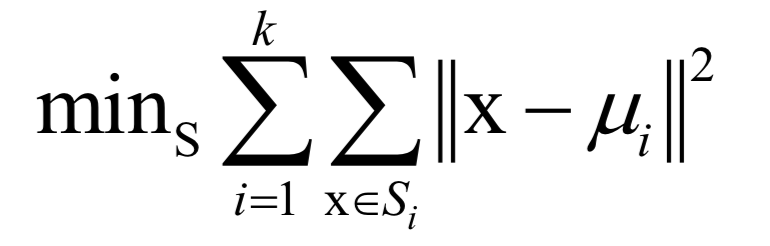

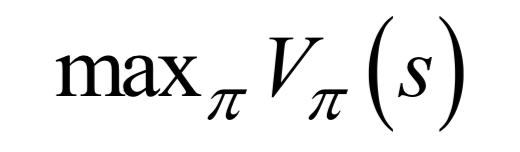
公式求解
-
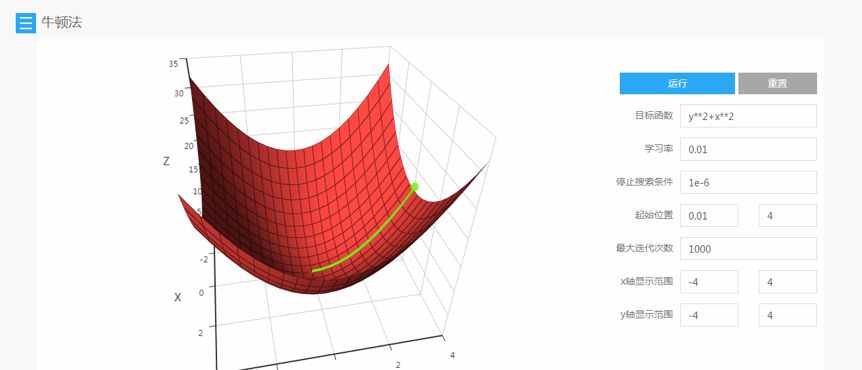
数值优化
能正确的找到各种情况下的极值点
-
速度快

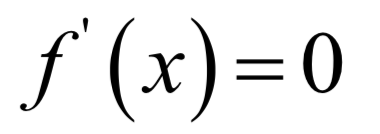

如果f''(x)>0,则在该点处去极小值
如果f''(x)<0,则在该点处去极大值
-
如果f''(x)>=0,还要看更高阶导数
如果Hessian矩阵正定,函数在该点有极小值
如果Hessian矩阵负定,函数在该点有极大值
-
如果Hessian矩阵不定,还需要看更(此处误)
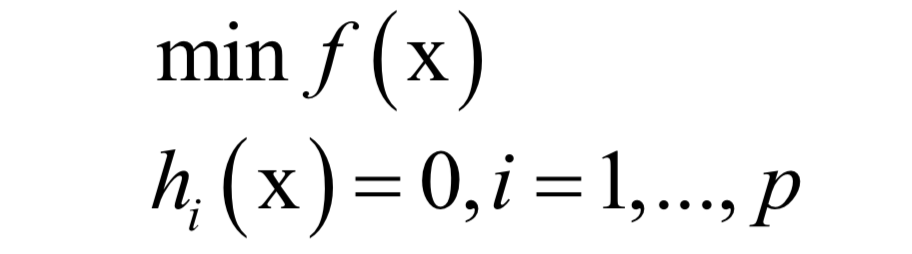
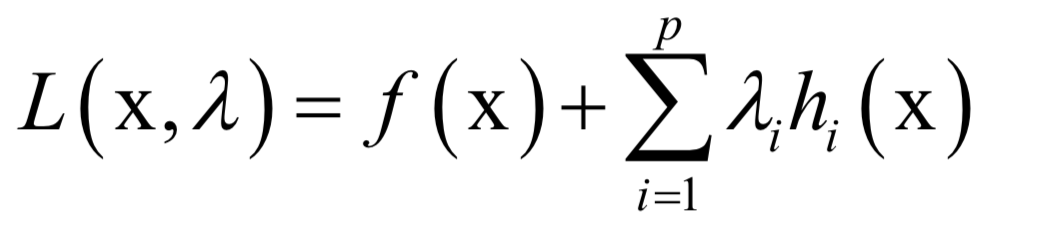
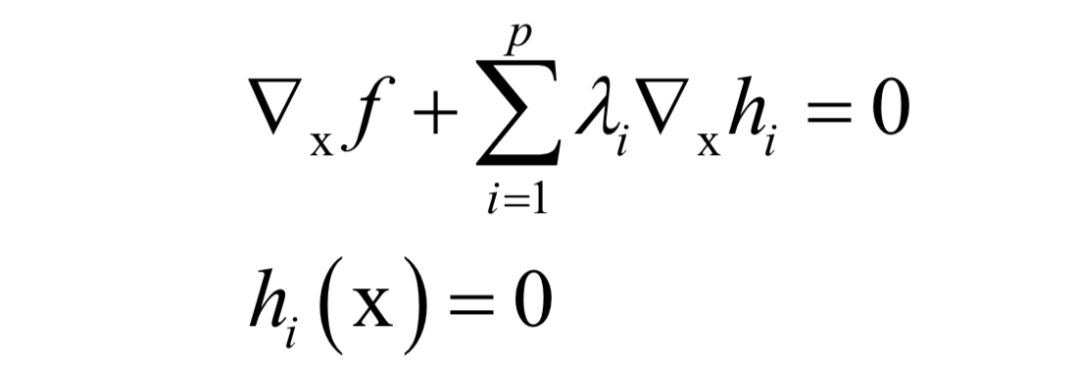
主成分分析
线性判别分析
流形学习中的拉普拉斯特征映射
-
隐马尔可夫模型
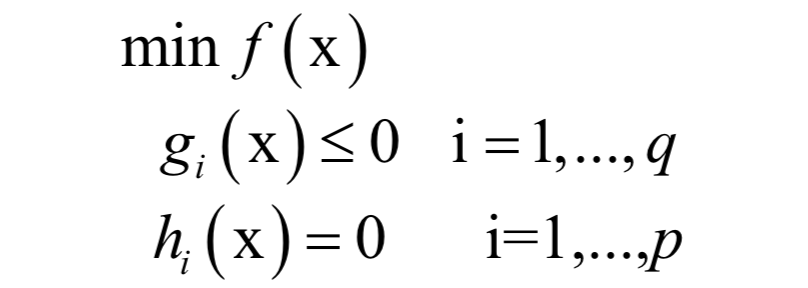
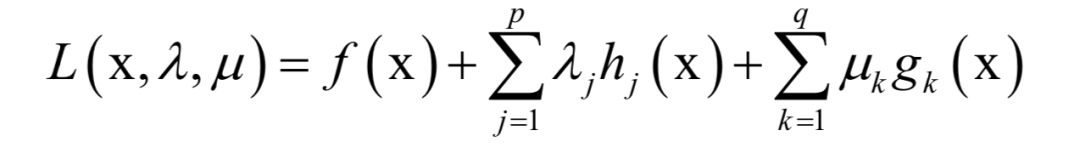
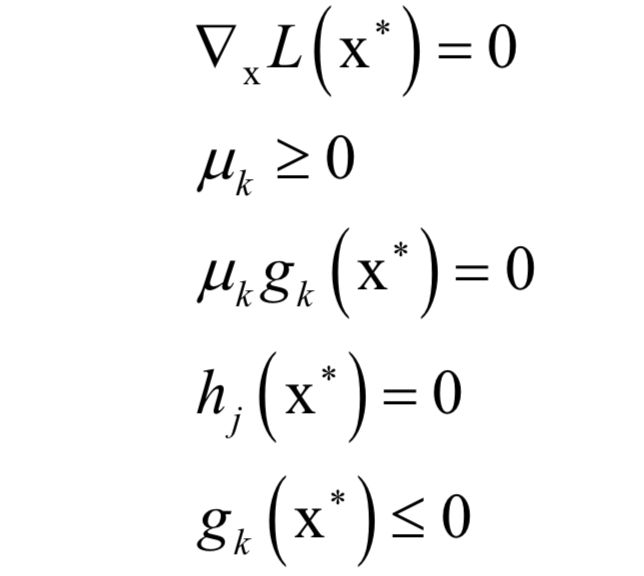
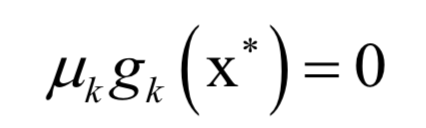
支持向量机(SVM)
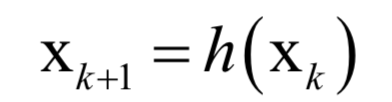
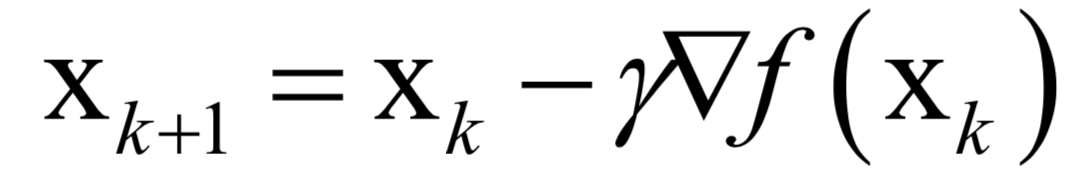
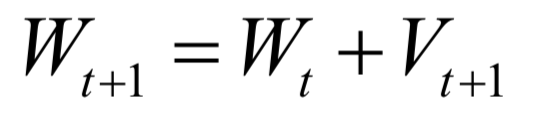
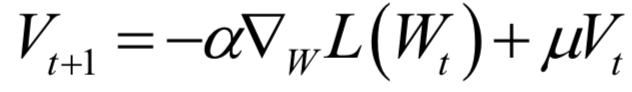
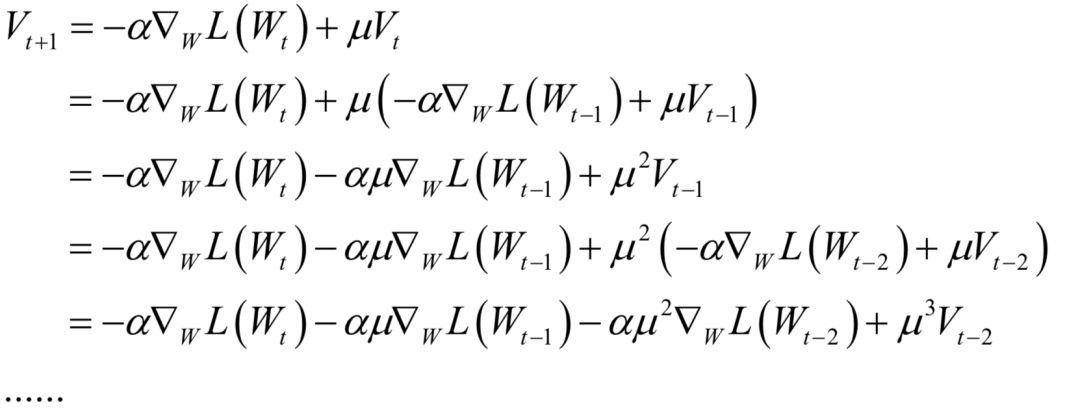
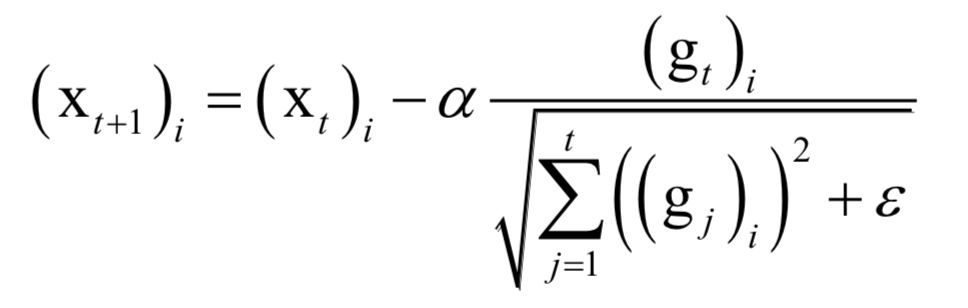
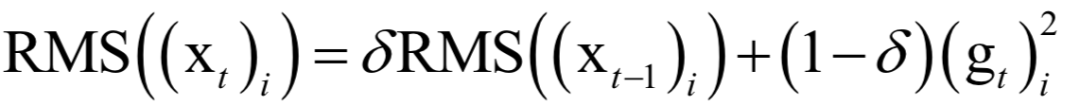

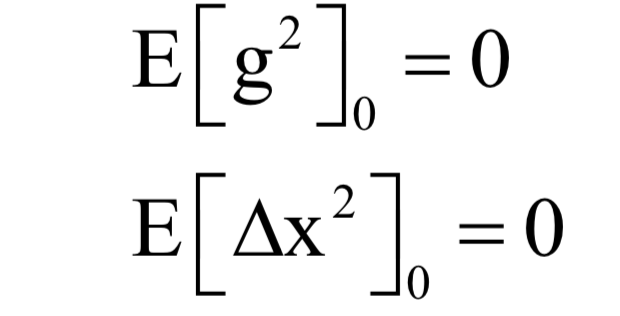
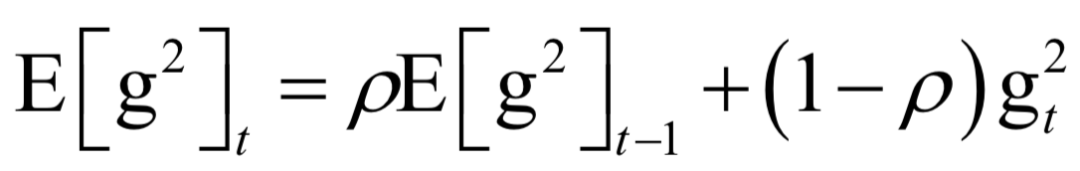
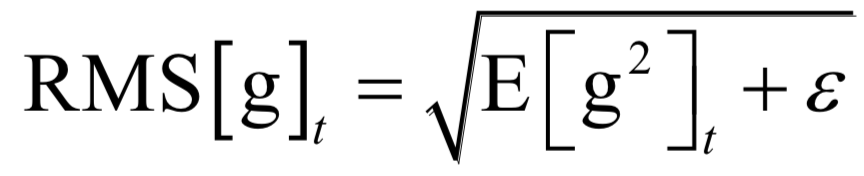
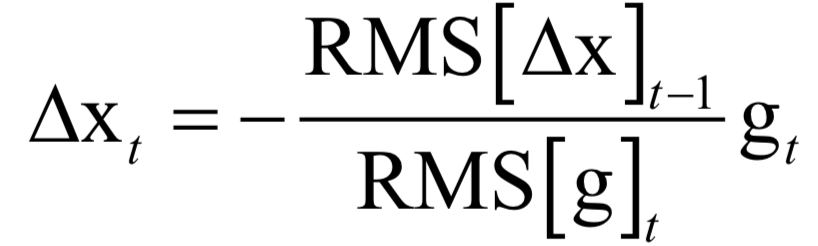




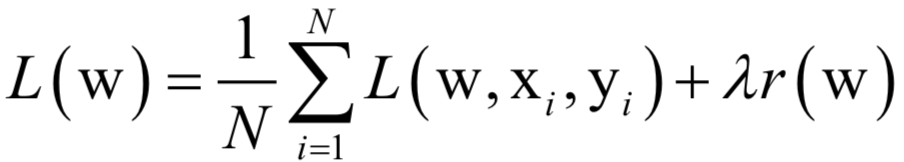
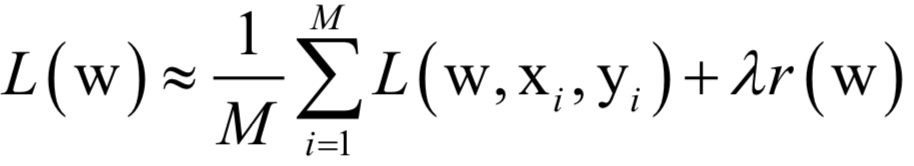

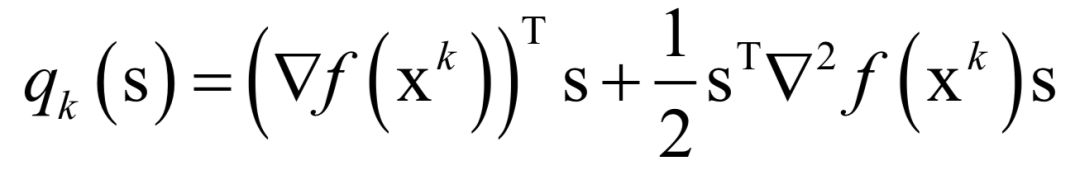
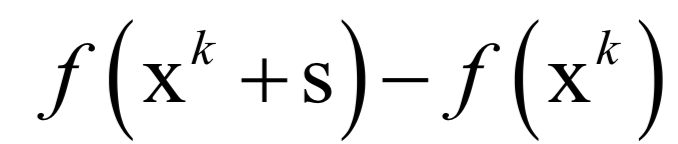
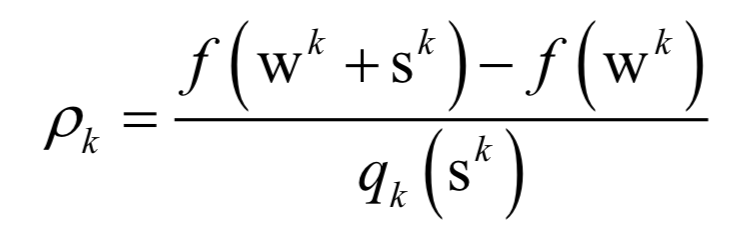
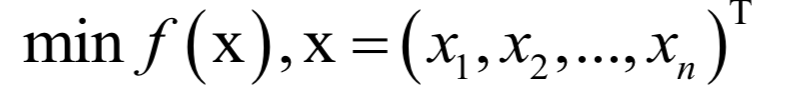
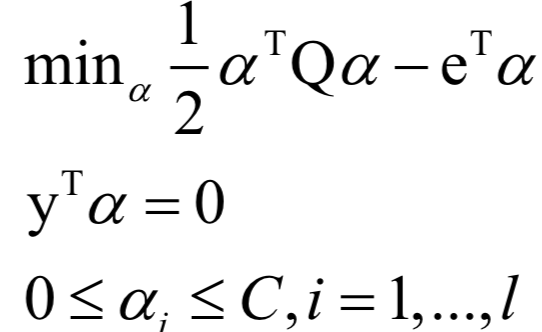
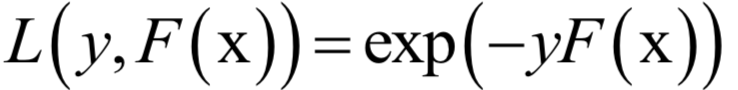
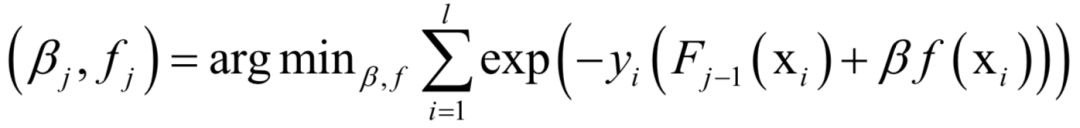
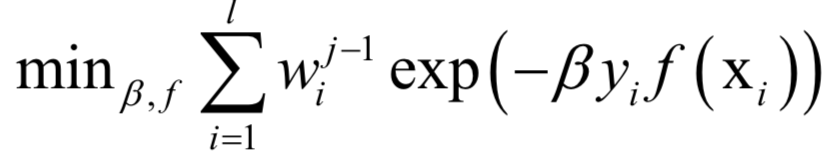
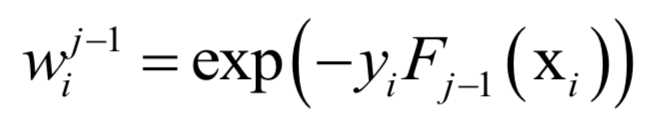
声明:部分内容来源于网络,仅供读者学习、交流之目的。文章版权归原作者所有。如有不妥,请联系删除。
评论