
机器学习最优化算法(全面总结)
转自:网络
导言
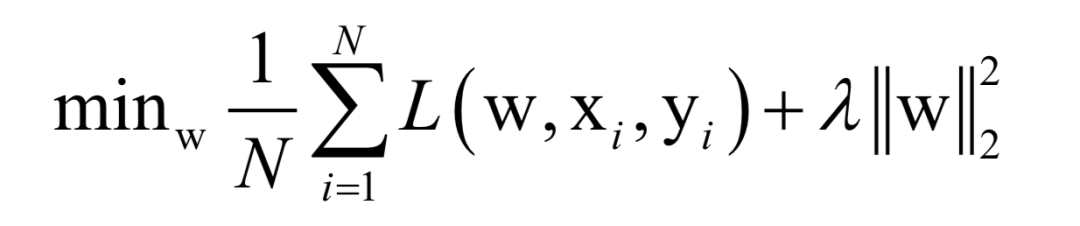
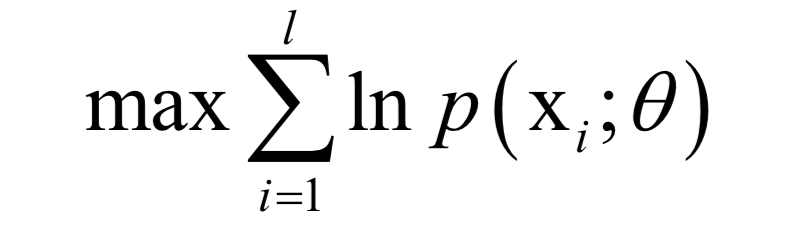
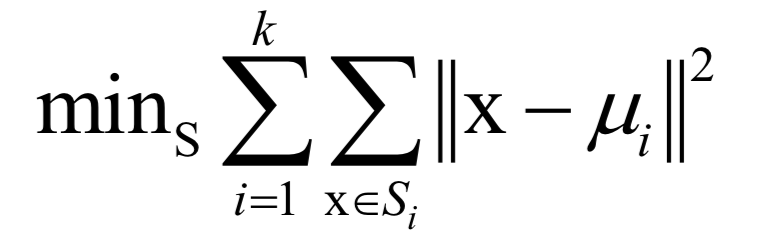
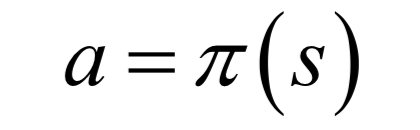
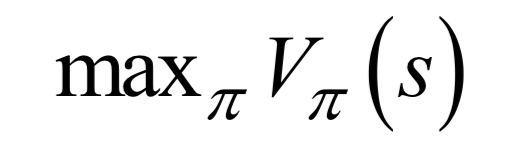
公式求解
-
数值优化
能正确的找到各种情况下的极值点
-
速度快
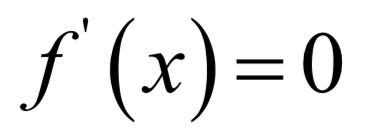
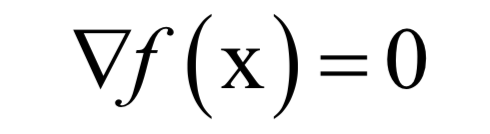
如果f''(x)>0,则在该点处去极小值
如果f''(x)<0,则在该点处去极大值
-
如果f''(x)>=0,还要看更高阶导数
如果Hessian矩阵正定,函数在该点有极小值
如果Hessian矩阵负定,函数在该点有极大值
-
如果Hessian矩阵不定,还需要看更(此处误)
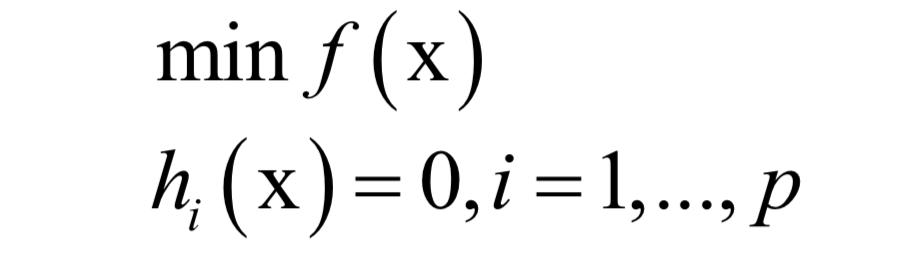
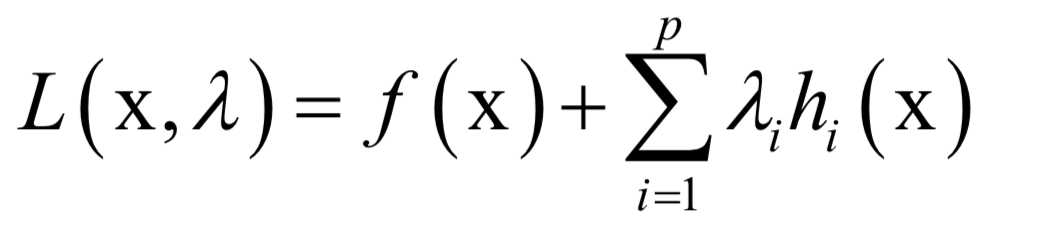
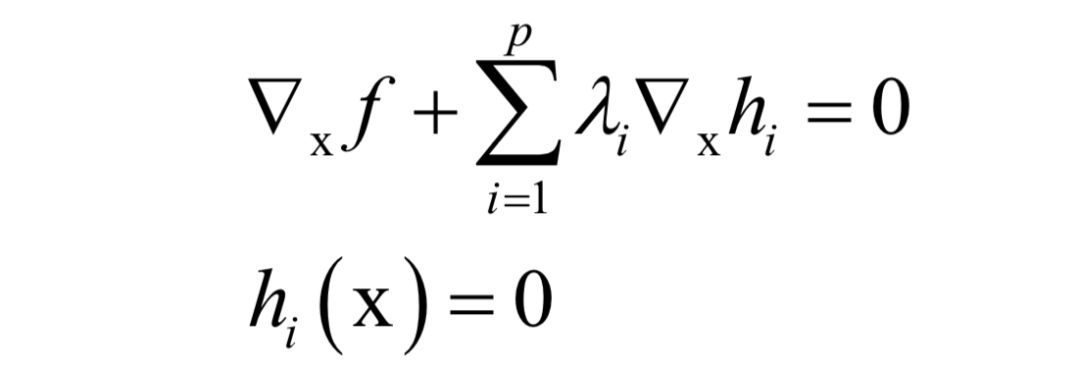
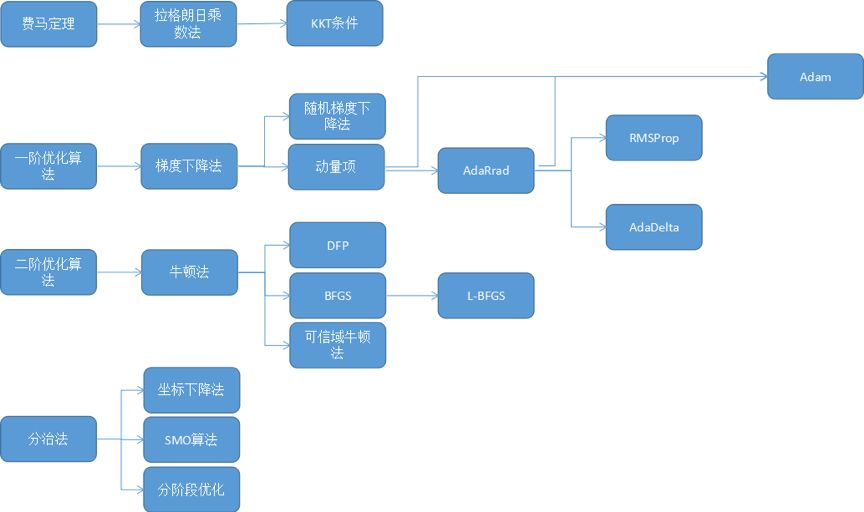
主成分分析
线性判别分析
流形学习中的拉普拉斯特征映射
-
隐马尔可夫模型
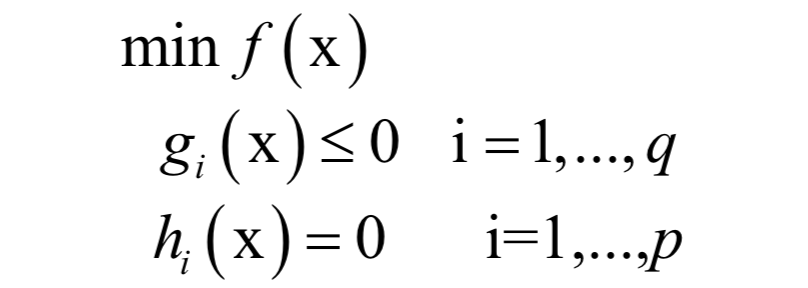
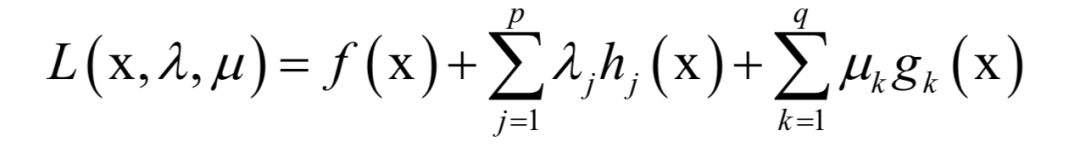
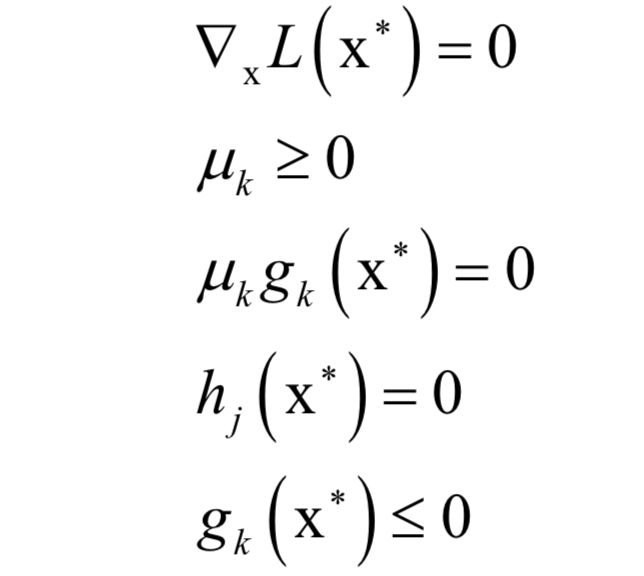
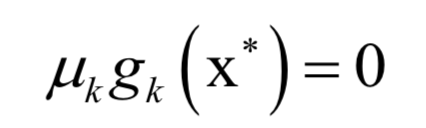
支持向量机(SVM)
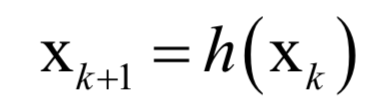
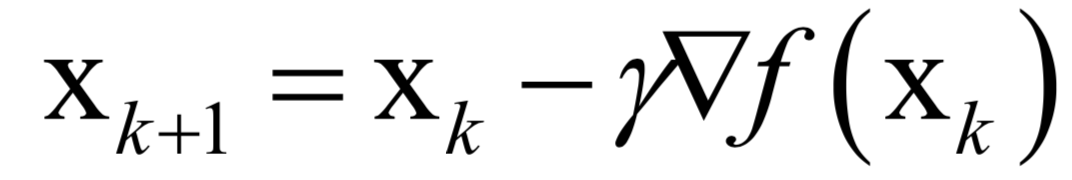
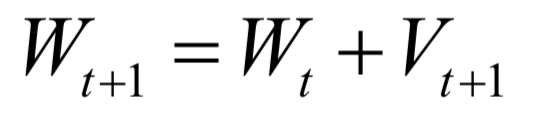
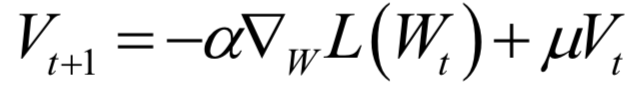
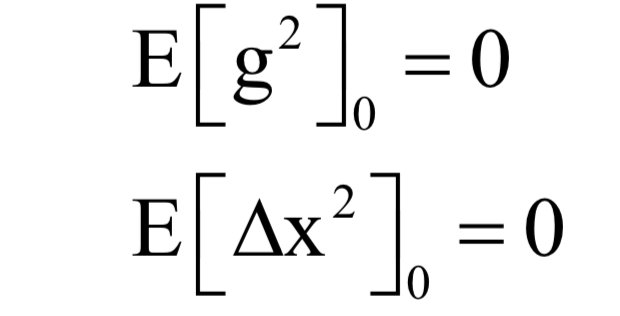
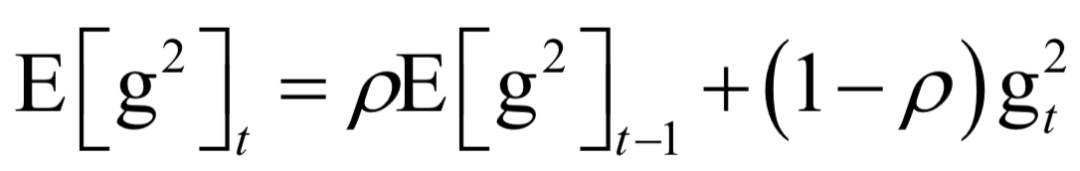
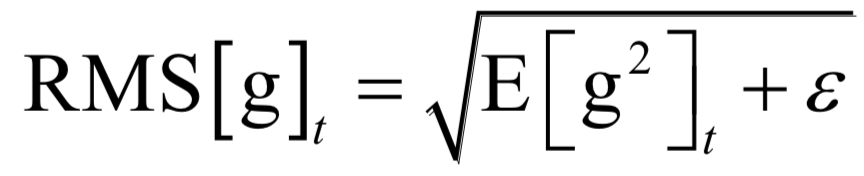
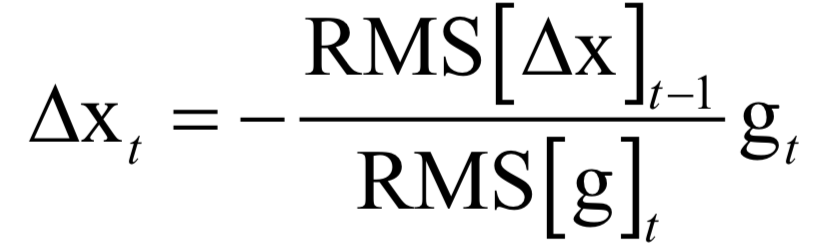
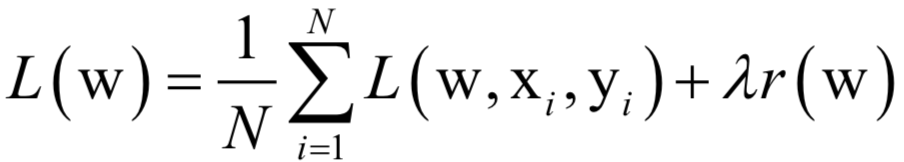
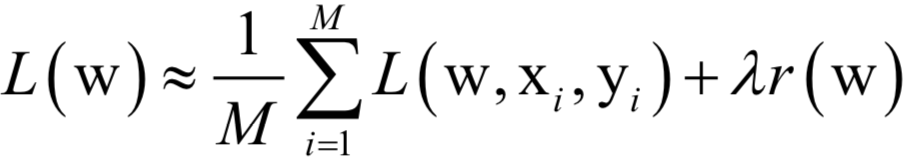
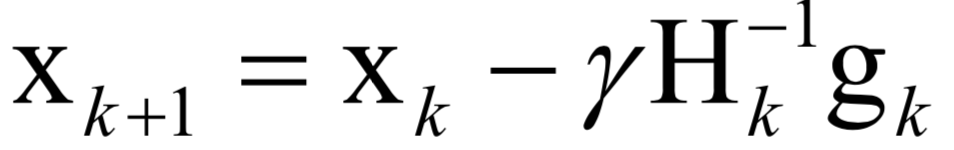
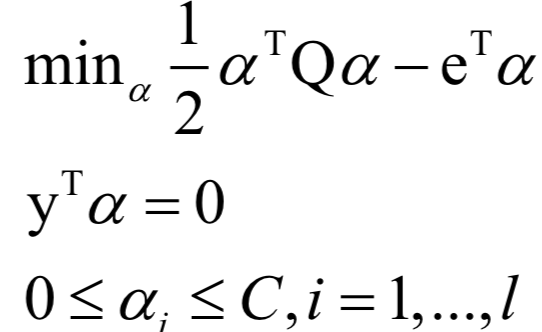
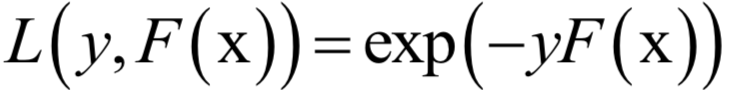
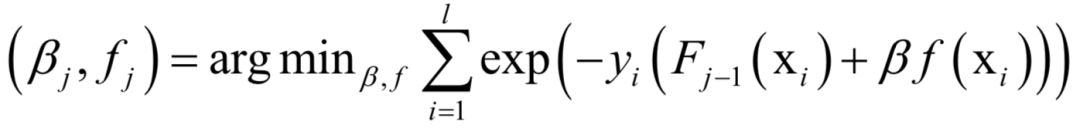
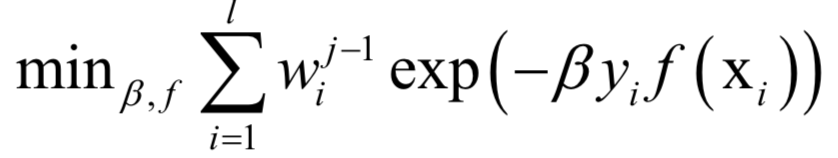
小码哥新手《Python + Excel/Word/PPT一本通》正式上市了!书中详细介绍了零基础用Python实现办公自动化的各方面知识,提高职场办公效率,附赠PPT/源代码/重点教学视频讲解和作者VIP一对一指导。
内容介绍:《Python + Excel/Word/PPT 一本通》内容介绍
扫码购买
▼点击阅读原文,了解本书详情

评论