
通用卷积神经网络CCNN
前言 在本文中,来自阿姆斯特丹自由大学、阿姆斯特丹大学、斯坦福大学的研究者提出了 CCNN,单个 CNN 就能够在多个数据集(例如 LRA)上实现 SOTA 。


该研究提出 Continuous CNN(CCNN):一个简单、通用的 CNN,可以跨数据分辨率和维度使用,而不需要结构修改。CCNN 在序列 (1D)、视觉 (2D) 任务、以及不规则采样数据和测试时间分辨率变化的任务上超过 SOTA。 该研究对现有的 CCNN 方法提供了几种改进,使它们能够匹配当前 SOTA 方法,例如 S4。主要改进包括核生成器网络的初始化、卷积层修改以及 CNN 的整体结构。
 作为核生成器网络,同时将卷积核参数化为连续函数。该网络将坐标
作为核生成器网络,同时将卷积核参数化为连续函数。该网络将坐标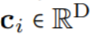 映射到该位置的卷积核值:
映射到该位置的卷积核值: (图 1a)。通过将 K 个坐标
(图 1a)。通过将 K 个坐标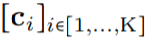 的向量通过 G_Kernel,可以构造一个大小相等的卷积核 K,即
的向量通过 G_Kernel,可以构造一个大小相等的卷积核 K,即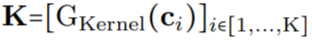 。随后,在输入信号
。随后,在输入信号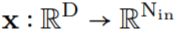 和生成的卷积核
和生成的卷积核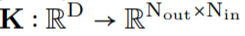 之间进行卷积运算,以构造输出特征表示
之间进行卷积运算,以构造输出特征表示 ,即
,即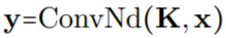 。
。
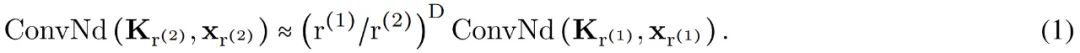
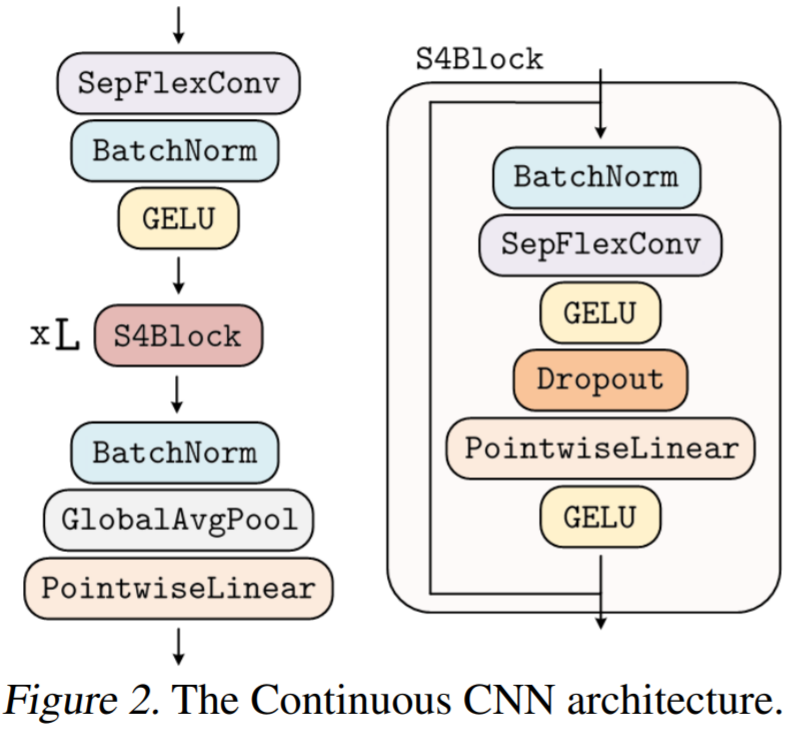
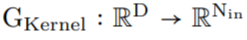 生成的核计算的,之后是从 N_in 到 N_out 进行逐点卷积。这种变化允许构建更广泛的 CCNN—— 从 30 到 110 个隐藏通道,而不会增加网络参数或计算复杂度。
生成的核计算的,之后是从 N_in 到 N_out 进行逐点卷积。这种变化允许构建更广泛的 CCNN—— 从 30 到 110 个隐藏通道,而不会增加网络参数或计算复杂度。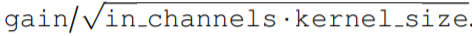 重新加权核生成器网络的最后一层。因此,核生成器网络输出的方差遵循传统卷积核的初始化,而 CCNN 的 logits 在初始化时呈现单一方差。
重新加权核生成器网络的最后一层。因此,核生成器网络输出的方差遵循传统卷积核的初始化,而 CCNN 的 logits 在初始化时呈现单一方差。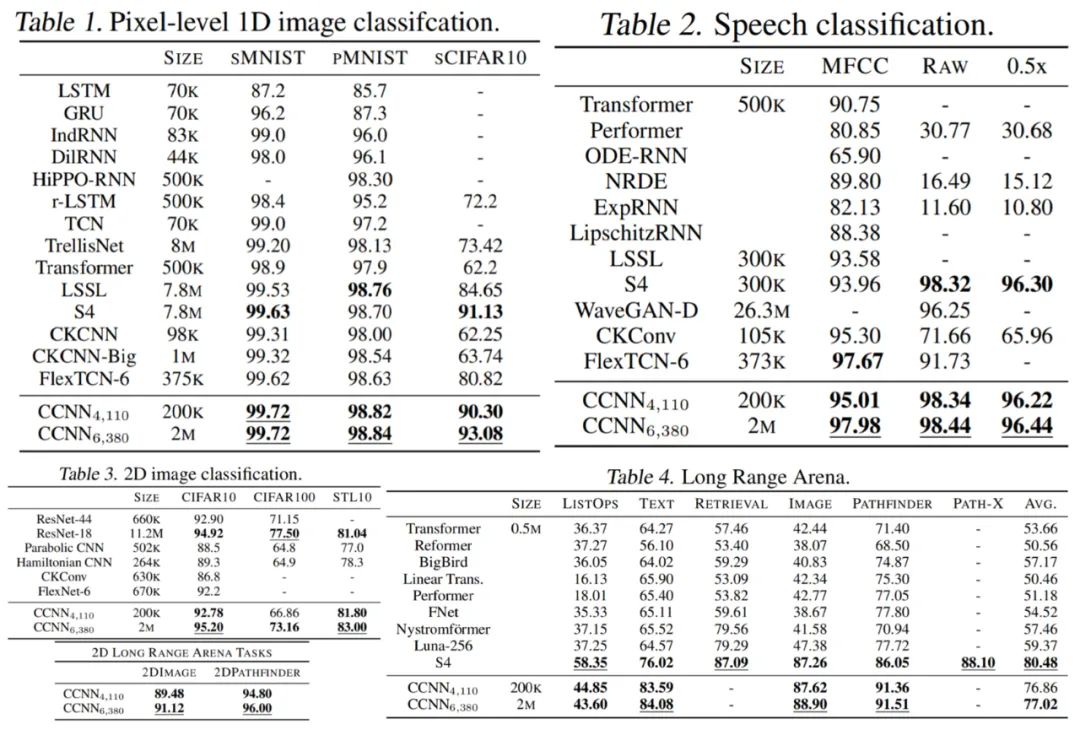
若觉得还不错的话,请点个 “赞” 或 “在看” 吧
评论