
图解:卷积神经网络数学原理解析
原标题 | Gentle Dive into Math Behind Convolutional Neural Networks
作 者 | Piotr Skalski 编 辑 | Pita
翻 译 | 通夜(中山大学)、had_in(电子科技大学)
介绍
数字图像的数据结构
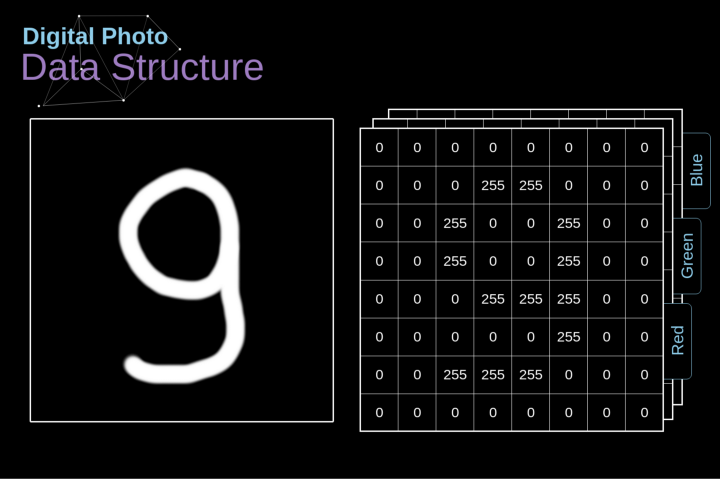
图2. 数字图像的数据结构
卷积

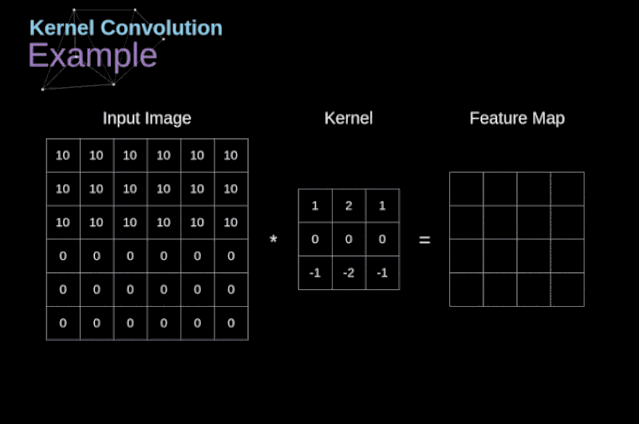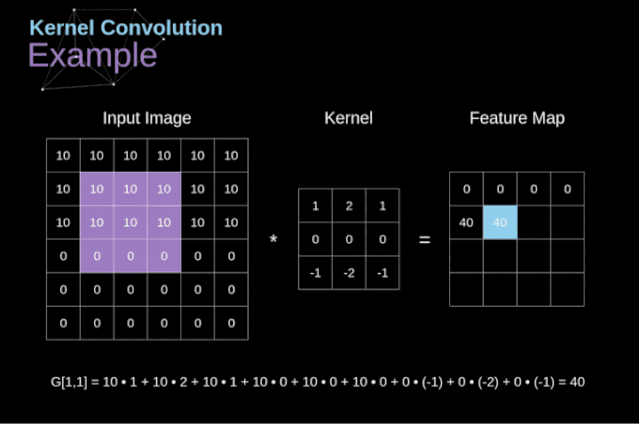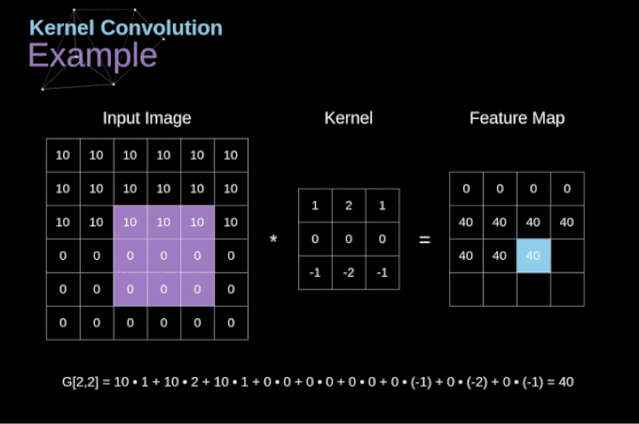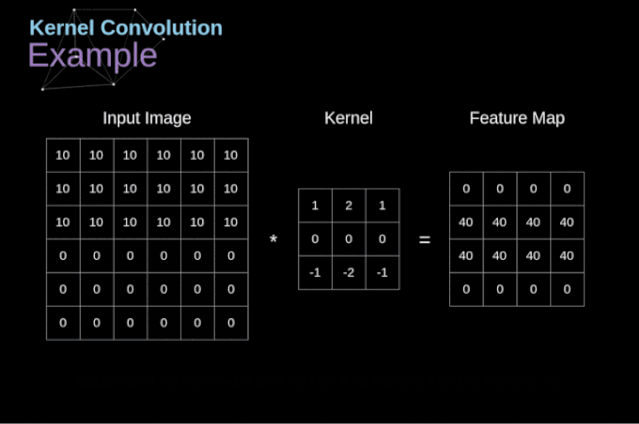
图3. 核卷积的例子

图4. 通过核卷积得到边缘[原图像:https://www.maxpixel.net/Idstein-Historic-Center-Truss-Facade-Germany-3748512]
有效卷积和相同卷积
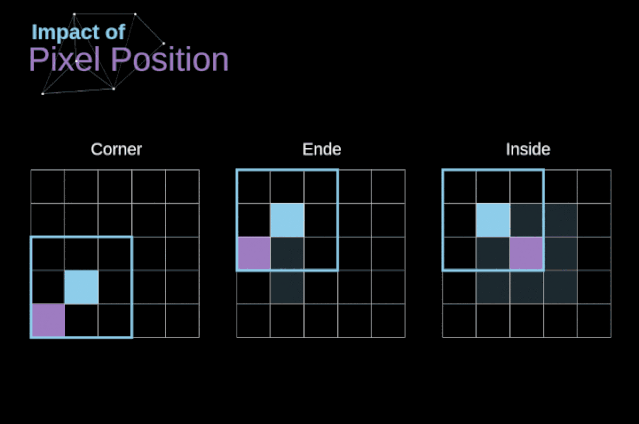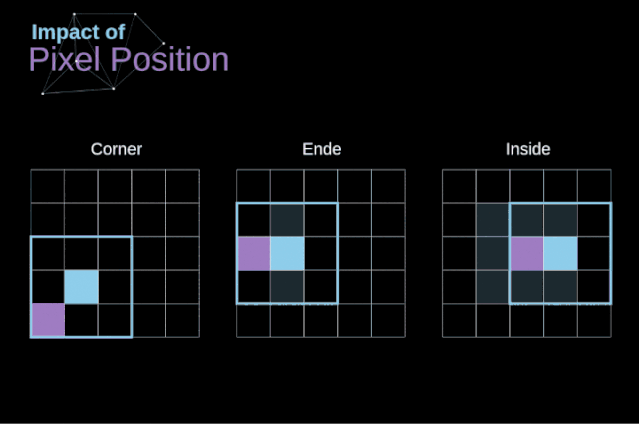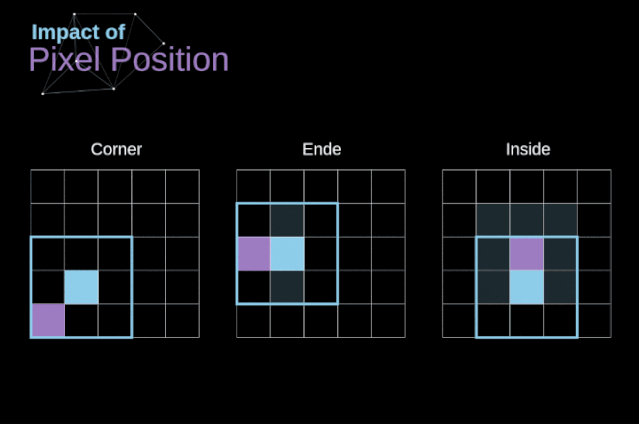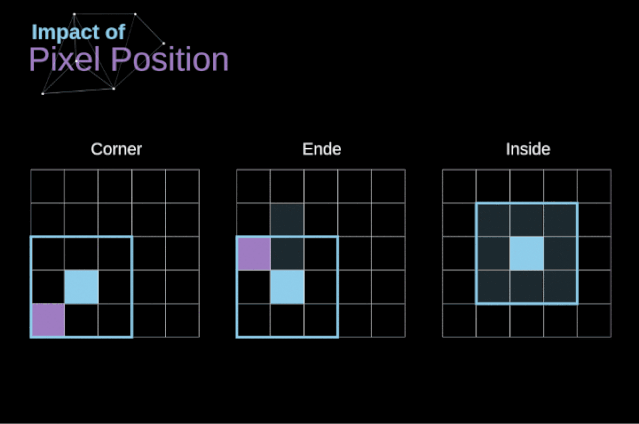
图5. 像素位置的影响

步幅卷积
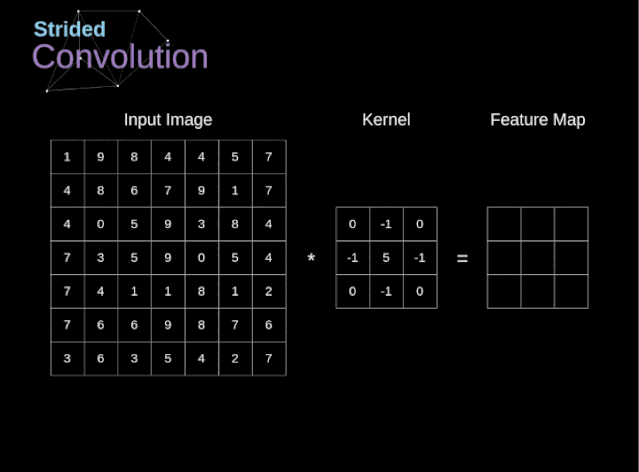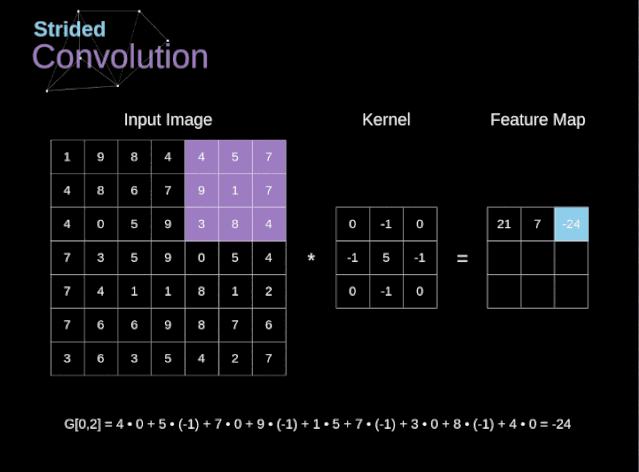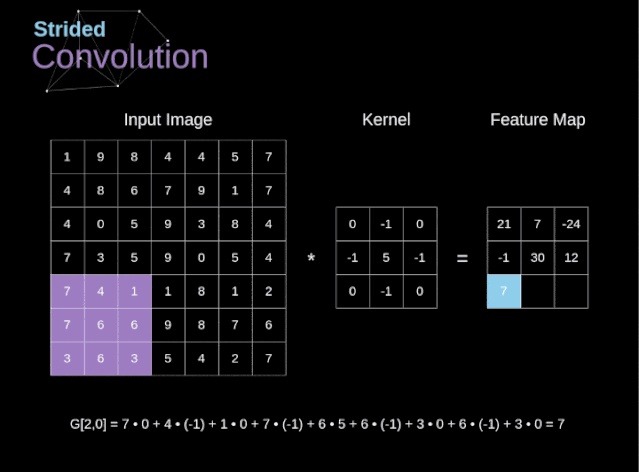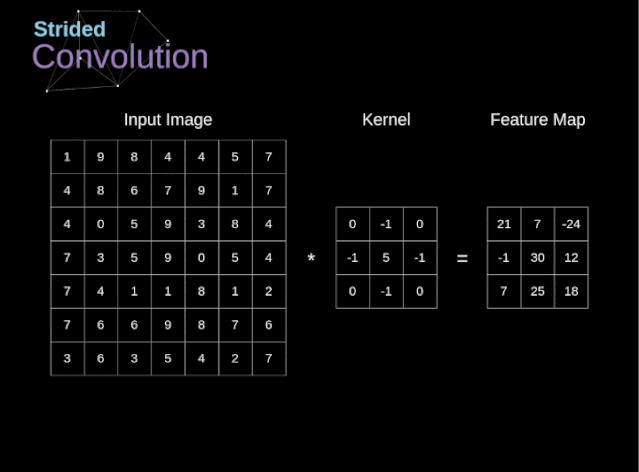
图6. 步幅卷积的例子

过渡到三维
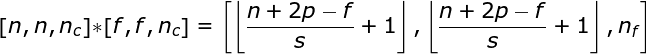
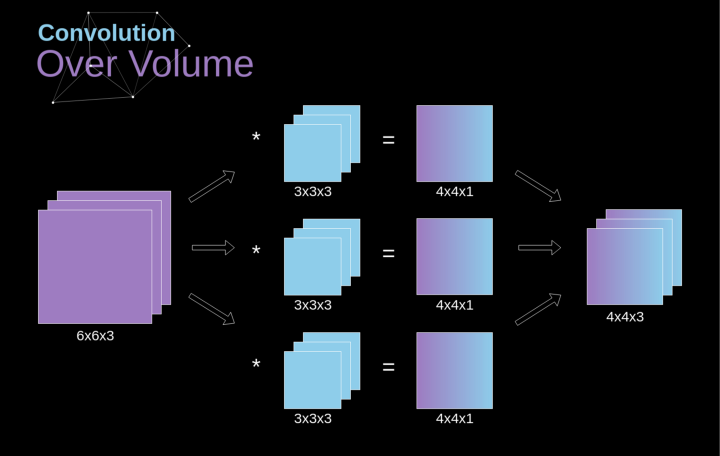
图7. 三维卷积
卷积层
图片

图8. 张量维度
连接剪枝和参数共享
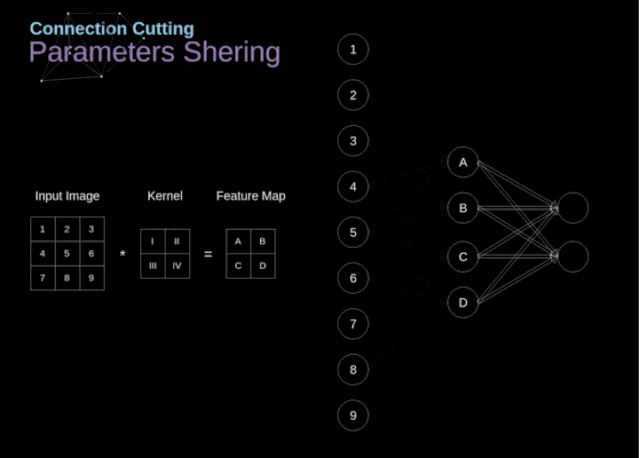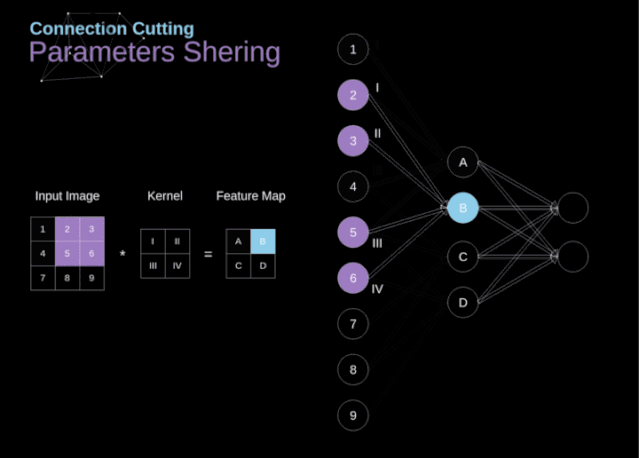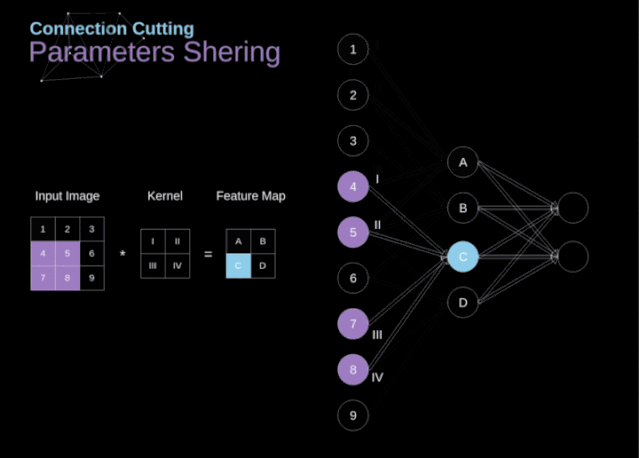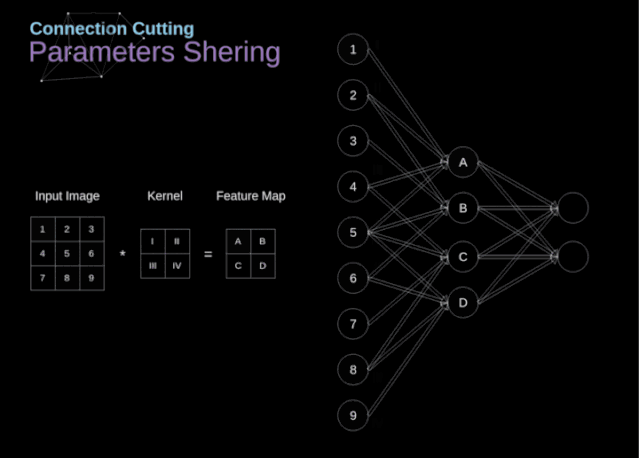
图9. 连接剪枝和参数共享
卷积层反向传播
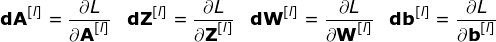
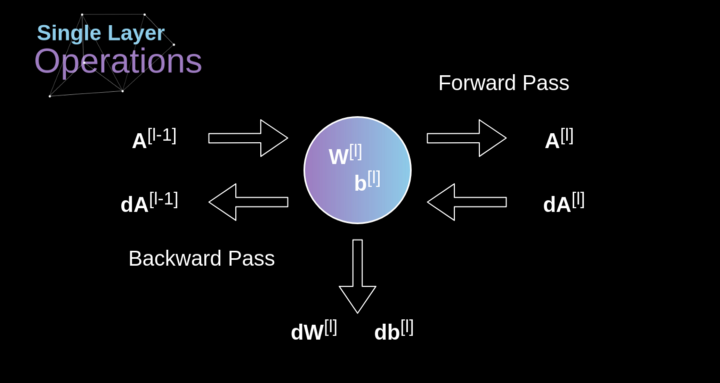
图10. 单卷积层的输入和输出的正向和反向传播
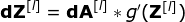
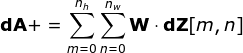
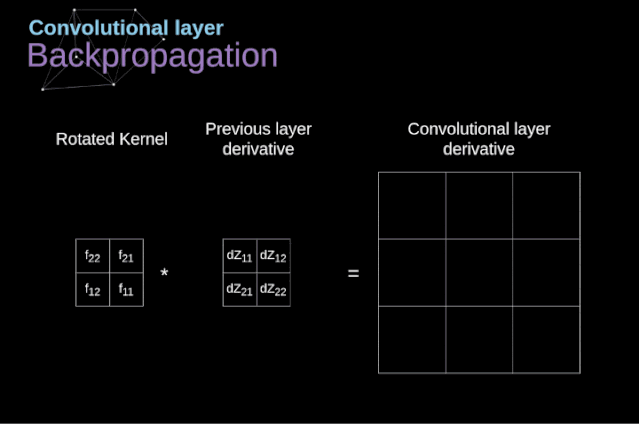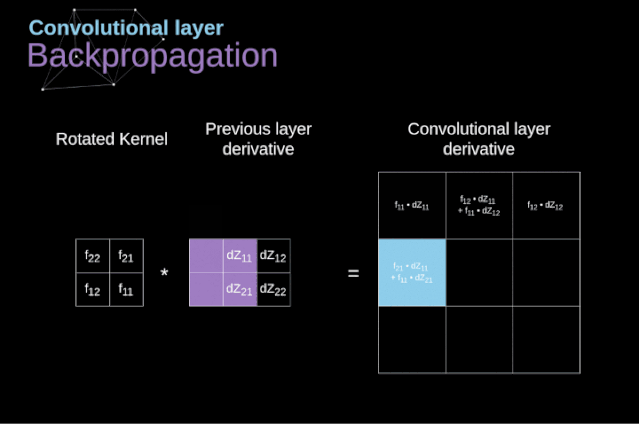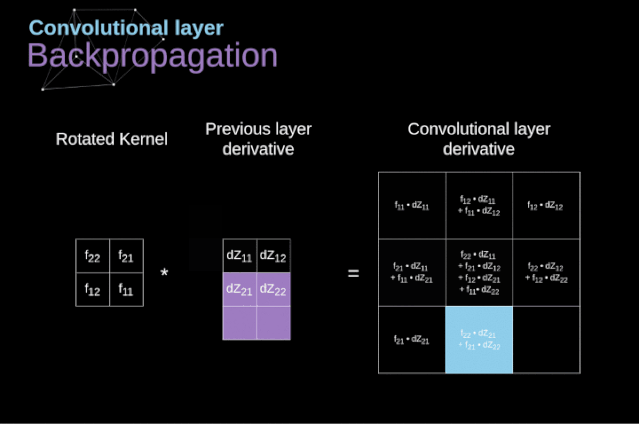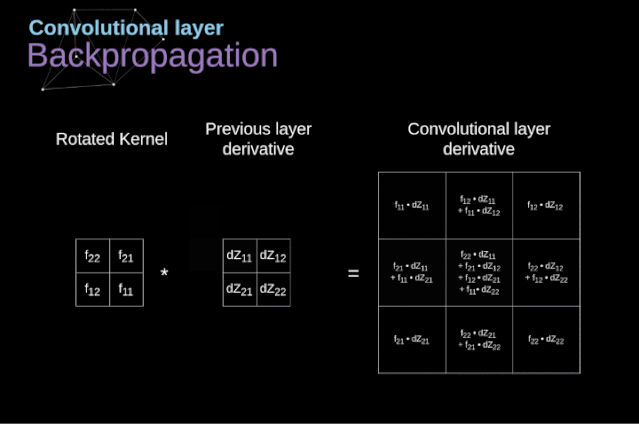
图11. 全卷积
池化层
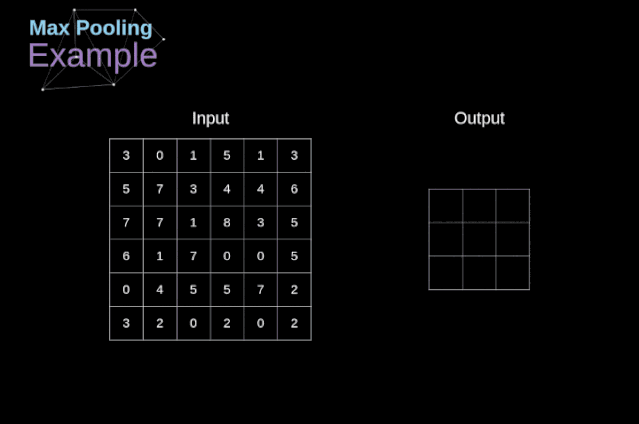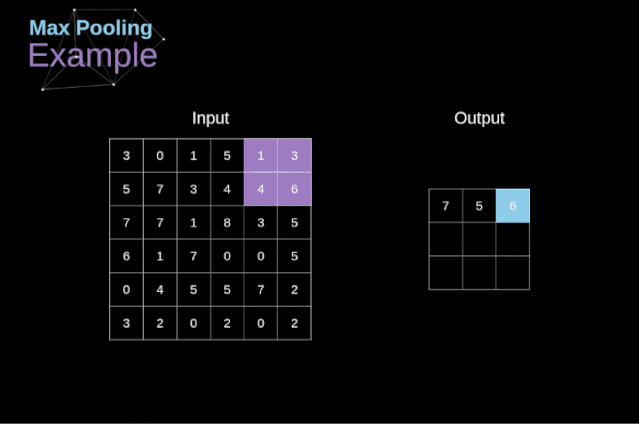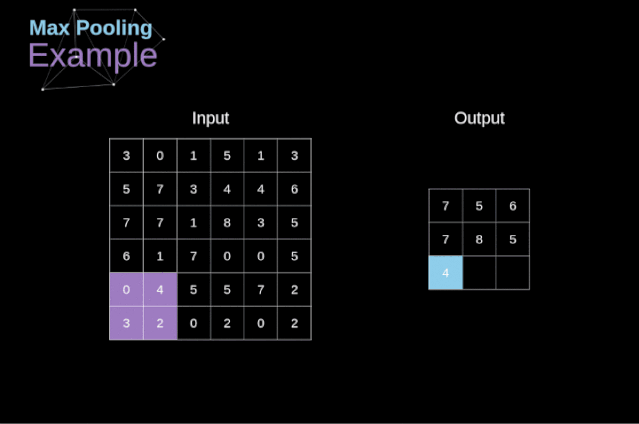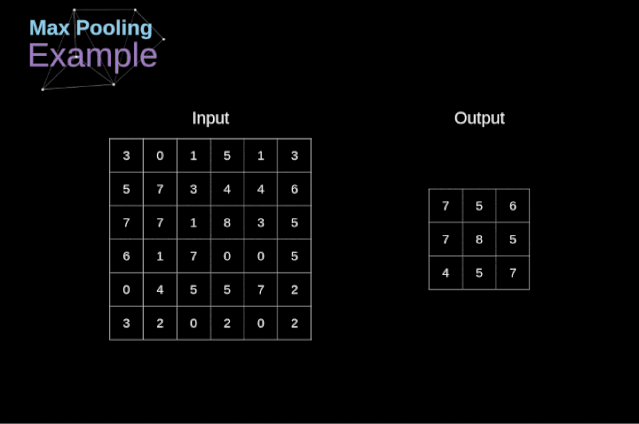
图12. 最大值池化的例子
池化层反向传播

图13. 最大值池化的反向传播
结论
本文是“神经网络之谜”系列文章的另一部分,如果您还没有机会阅读其他文章,请阅读其他文章(https://towardsdatascience.com/preventing-deep-neural-network-from-overfitting-953458db800a)。另外,如果你喜欢我所做的工作,在Twitter和Medium上关注我,也可以看看我正在做的其他项目,如GitHub(https://github.com/SkalskiP)和Kaggle(https://www.kaggle.com/skalskip)。保持好奇心!
via https://towardsdatascience.com/gentle-dive-into-math-behind-convolutional-neural-networks-79a07dd44cf9