
卷积神经网络(CNN)概念解释
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:opencv学堂
传统的模式识别神经网络(NN)算法基于梯度下降,基于输入的大量样本特征数据学习有能力识别与分类不同的目标样本。这些传统模式识别方法包括KNN、SVM、NN等方法、他们有一个无法避免的问题,就是必须手工设计算法实现从输入图像到提取特征,而在特征提取过程中要考虑各种不变性问题、最常见的需要考虑旋转不变性、光照不变性、尺度不变性、通过计算图像梯度与角度来实现旋转不变性、通过归一化来避免光照影响,构建尺度金字塔实现尺度不变性,这其中SIFT与SURF是其这类特征的典型代表、此外还可以基于轮廓HOG特征、LBP特征等,然后把特征数据作为输入,选择适合的机器学习方法如KNN、SVM等方法实现分类或者识别。这些方法的一个最大的弊端就是特征提取设计过程完全依赖于人、人的因素太多,没有发挥出机器主动学习、提取特征的能力。好处就是人可以完全控制特征提取的每个细节、每个特征数据。图示如下:
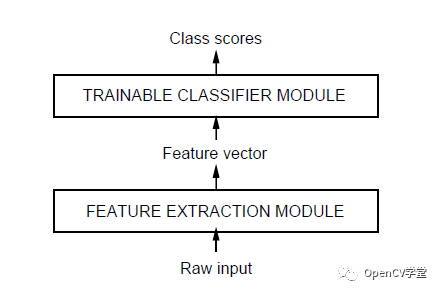
以卷积神经网络(CNN)为代表的深度学习方法实现对象识别与分类,则是把特征提取完全交给机器、整个特征提取的过程无需手工设计、全部由机器自动完成。通过不同filter的卷积实现特征提取,这样就可以对畸变与光照保持一定程度的不变性、通过最大池化层采样实现尺度不变性,在保持传统特征数据三个不变性的同时,在特征提取方法上尽量减少人工设计细节,通过监督学习把计算机的计算能力发挥出来,主动寻找合适的特征数据。完成了特征提取算法有传统的白盒机制到以机器为主导的黑盒机制,实现了识别分类结果的最优化求解。最早的卷积神经网络模型出现在1998年,主要是用来实现OCR(英文字母识别),它的名称叫做LeNet-5网络,其结构如下:
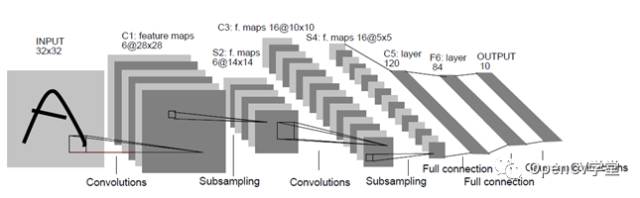
输入层(Input Layer)表示输入数据(图像)
卷积层(Convolution Layer)通过5x5的卷积核实现特征提取,然 后通过2x大小最大池化,降采样。上图有两个卷积层
全连接层(Full connection Layer),传统神经网络的多层感知器 (MLP)。上图有两个全连接层
输出层(Output Layer)
首先要理解一下图像卷积的概念,卷积是一种数学操作,简单可以解释如下图:
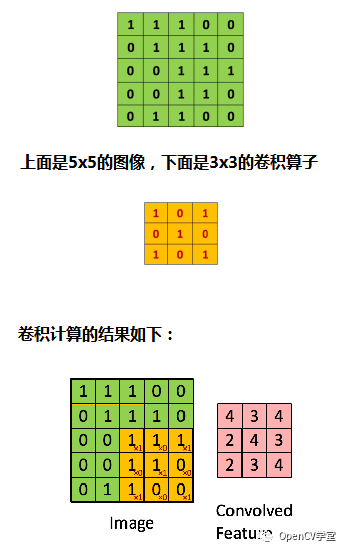
而对与卷积神经网络的卷积层来说,我们一般定义输入图像是wxh像素宽高大小,定义K个mxn卷积核,对每个卷积核完成输入图像与之卷积得到生成k(w-m+1)(h-n+1)卷积图像,降采样之后则得到DMN (M=(w-m+1)/2, N=(h-n+1)/2), 其中D表示深度即feature map的个数,输出第一层卷积池化之后,继续进行卷积操作的时候必须考虑图像的深度,在深度方向完成三维卷积,图示如下:
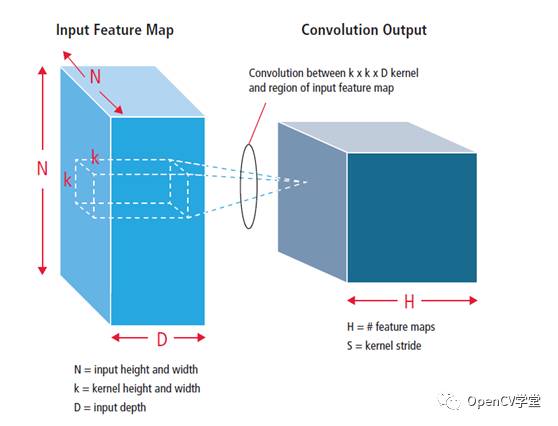
这样就得到了卷积第二层,如果还有需要还可以进行第三层卷积到~N层,卷积层操作。在每个卷积层操作完成之后,还需要做些额外的数据处理ReLU,下图是ReLU的数学表述与曲线
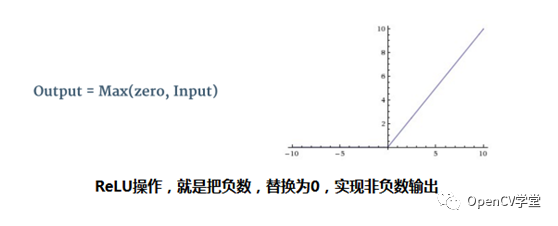
对比一下,ReLU操作之前与操作之后的Feature Map输出

全连接层是传统的神经网络的多层感知器(MLP),通过激活函数实现到最终输出层,全连接层是要对该层所有神经元,链接到下个层每个神经元,全连接层的目的是实现分类输出到最终的输出层。传统的MLP网络结构如下:
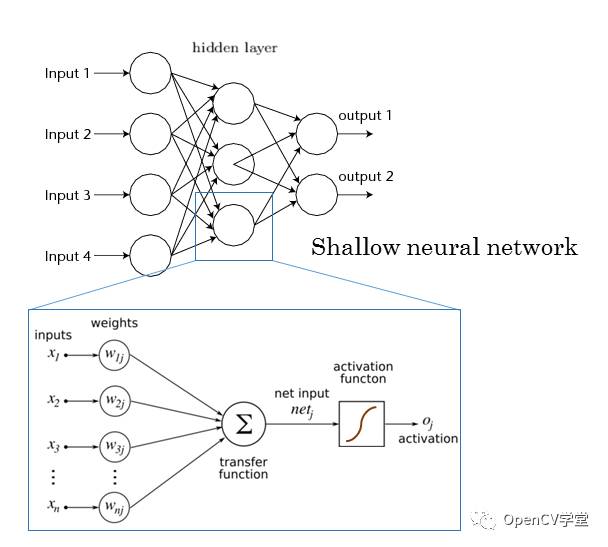
卷积神经网络相比传统特征提取与模式识别方法,具有以下几个方面的优势
训练相对容易,无需复杂的特征提取过程,可以说降低了图像识别的学习门槛,让更多懂数据人找到了学习图像处理与计算机视觉的捷径。
卷积层通过共享权重参数,相比传统的神经网络,减少参数个数,对内存要求降低
对图像的扭曲、变形、像素迁移保持稳定、具有一定不变性特征。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~