
NLP模型BERT和经典数据集!
对于刚入门NLP的伙伴来说,看到NLP任务很容易觉得眼花缭乱,找不到切入点。总的来说,NLP分为五大类无数小类,虽然种类繁多,却环环相扣。无论我们一开始学习的是什么方向,当做过的东西越来越多,学习范围越来越大的时候,总可以形成闭环。
这一次,我们从教机器做阅读理解题起航,介绍用火到“出圈”的Bert和常见数据集入手NLP的整体流程。
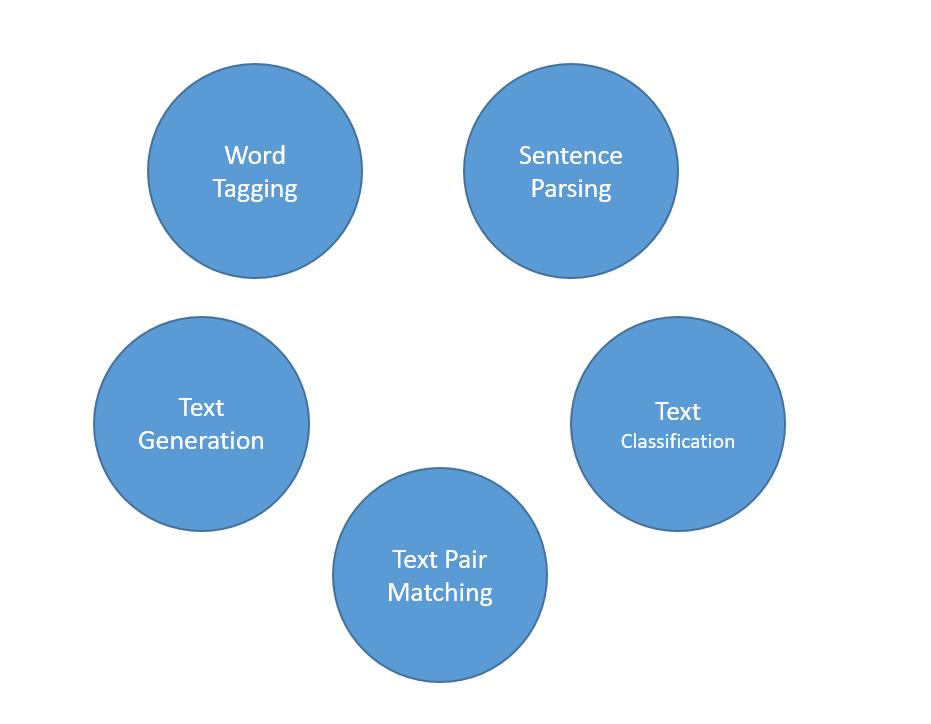
从机器阅读理解起步
什么是机器阅读理解?形式就像下图:

怎么样,是不是感觉很酷!让我们的模型来做阅读理解题目,好似机器有了人类理解的能力。当然,也不能太乐观,现在机器阅读理解任务还在逐步探索阶段。在训练方式上,对于不同机器阅读理解数据集,就会有对这个任务的不同解法。对于机器阅读理解任务,我们将其分为三个类型。难度逐步上升:
简单问题:对答案的简单匹配和抽取 复杂问题:加入推理 基于对话的问答系统:自由问答和特定任务场景的问答
可以看出,如果答案在文章内可以清晰的找到,那么模型就不需要生成答案,只需要将答案抽取出来就好了,这样的任务是简单的,可以使用SQuAD 1.0学习。
更近一步,有些阅读理解的问题中是没有答案的,正确的答案就是不回答,这种行为更接近智能,任务也变的更困难,需要用SQuAD 2.0学习。
此外还有对话系统,它的答案要和实时场景相匹配所以难度更高,这里主要讨论前两种。
绕不开的SQuAD数据集
上面关于机器阅读理解描述中,我们反复提及用SQuAD数据集进行训练。对于想要从事相关方向的同学来说,这个数据集几乎是绕不过的。
SQuAD(Stanford Question Answering Dataset)是斯坦福大学通过众包的方式来构建的一个机器阅读理解数据集。本质上,这就是一个大规模的英文阅读理解数据集,现在做和英文的阅读理解相关所有任务,都用它。
数据开源地址:https://gas.graviti.cn/dataset/hello-dataset/SQuAD_v2?utm_medium=0725datawhale
数据集现在有SQuAD1.0 和 SQuAD2.0两个版本,适用于不同的研究场景:
SQuAD1.0
1.0版本的数据集中包含107,785的问题以及对应的536篇文章。文章源自维基百科上的一系列文章。
与之前其他数据集的区别:相较于以前的阅读理解数据集,SQuAD更大,包含的文章内容也更多。其具体的形式是,SQuAD的答案是短语或者一段话,而不再是一个单词。答案里面包含的信息增多了,所以任务的难度也增加了。
特点:阅读理解的所有答案,都可以在文章中完全可以找到(答案可以从文章中完全copy过来)。并且文中的答案是不能是跨行的。也就是说答案是文章指定的一个区间。所以,SQuAD的答案生成是抽取式的。
数据集示例如下:

SQuAD2.0
在阅读理解中,遇到有些问题无法通过阅读现有文章的内容来回答,该怎么办?
有些信息我们无法通过文章找到,在使用1.0版本的数据集中,模型遇到了那些无法回答的问题,也会强制给出一个回答,这样的情况显然不够智能。所以在2.0版本的数据集中,增加了50,000条没有答案的问题,通过这个数据集中,希望模型可以学会对于没有答案的问题不作回答。也就是说希望我们的模型要有“知道自己不知道”的能力。

2.0版的数据集形式就如上面图片所示,上面的图片中展示的两个问题都是没有答案的,没有答案的问题不回答才是正确的。
总结来说,SQuAD是一个主流的抽取式的英语阅读理解数据集。现在大家都在SQuAD2.0上刷榜。
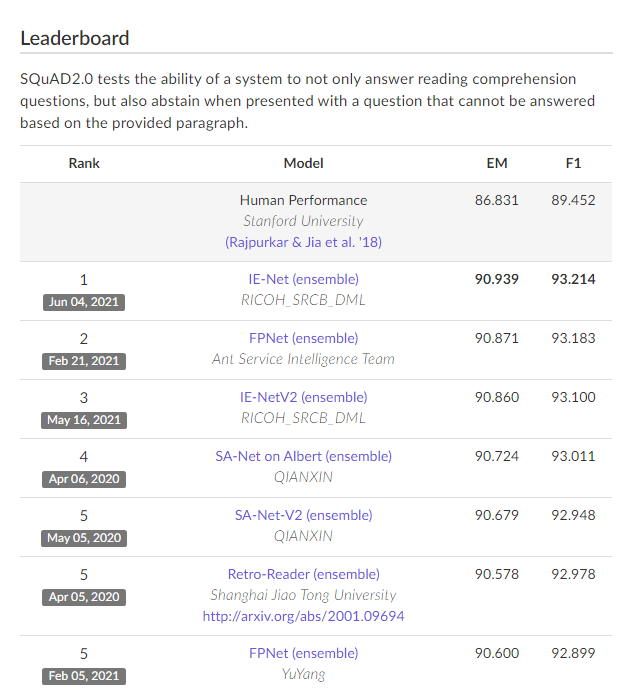
通过上面的榜单可以看到,在SQuAD2.0这个数据集中,前五名的模型获得的效果已经远超人类。如果将这些模型做一个分析,可以说每个模型里面都装着一个Bert。
浅说BERT
Bert这个预训练模型,在2021年的今天应该是当之无愧的”网红“。作为一个入门的介绍,这里先讲Bert在原论文中是如何被训练的。之后介绍SQUAD数据集是如何与Bert结合的。
从结构角度来说,Bert是由Transformer的Encoder(编码器)构成的。通过强大的编码能力,可以将语言映射在一个向量空间中,将单词表示为向量,也就是大家常说的Embedding(词向量)。Bert的所做的就是,输入一个句子,基于任务然后吐出来一个基于训练任务的词向量(embedding)。
知道Bert是什么,那么下面就介绍一下Bert在原论文中的两种训练方式。
两个训练方法
① Masked LM

将一句话输入之后,随机mask掉一个单词,具体mask的方式就是将那个词替换为[MASK]这个符号,然后再mask位置的输出接到一个简单的线性分类器当中。我们希望的是一个简单的线性分类器可以得到正确的答案。如果简单的分类器可以输出正确的答案,就说明这个embedding(词向量)的效果相当的好
② Next Sentence Prediction
预测输入的两个句子是不是一句话
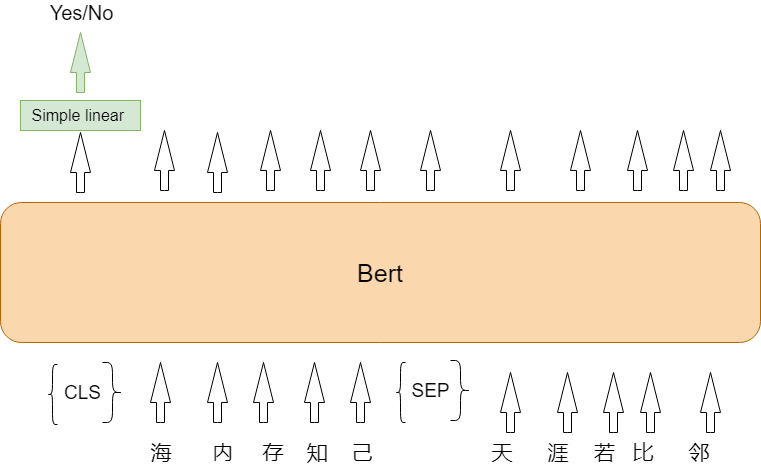
输入两句话,然后Bert输出的是单词的embedding(词向量)。这时从图中可以看出,有两个特殊的输入单词———SEP和CLS。SEP这个单词的意思就是告诉Bert,左右的两个句子是分开的。CLS这个单词的意思就是告诉Bert,这里是要做一个分类任务。然后将这个CLS输出的embedding放入一个简单的分类器中(simple linear)来预测两个句子是不是一句话。如何可以分辨的很好,说明了Bert对于语句相似性有很好的的表示效果。
在Bert的完整训练过程中,这两个训练任务是都要有。这样可以训练出性能优秀的Bert。
在Bert里为了完成不同的任务,设计了不同的特殊单词。这里顺便做一下总结:
[CLS]:告诉模型要做分类任务,其中最后一层的第一个embedding作为分类任务的presention。[SEP]:告诉Bert左右两边的输入是不同的。[UNK]:没出现在Bert字典里的字会被这个单词替代。[PAD]:zero padding,将长度不同的序列补充为固定长度,方便做batch运算。[MASK]:未知遮罩
用Bert做机器阅读理解
现在我们已经知道了SQuAD这个数据集以及模型Bert。现在就可以通过Bert和SQuAD来做机器阅读理解了。
接下来详细说一说在Bert中,如何在SQuAD上解决阅读理解这个问题的。
在原始的Bert任务中,就已经利用SQuAD来做阅读理解任务了。它使用了SEP的这个特殊单词,将Qury(问题)和Document(文章)一起作为输入。然后在Bert中获取良好的embedding(词向量),然后将这个embedding(词向量)的结果接入一个分类器,分别得到答案在文章中位置的id和结束位置的id。因为SQuAD数据集中的答案是可以直接在文章中抽取出来,所以得到答案起始位置的id和结束位置的id可以直接抽取出正确的答案。
我们使用文章一开始那个例子给大家举例。当我将文章和问题输入给Bert之后,将Bert输出的Embedding(词向量)接入到一个阅读理解任务的模型中(这个模型可以先忽略,对于Bert来说,不同的任务会不同的模型来辅助)。我们发现,输出的结果是'雪'和‘藻’在文本中的位置65和67。然后我们将65-67这三个字抽取出来就得到了答案“雪衣藻”。
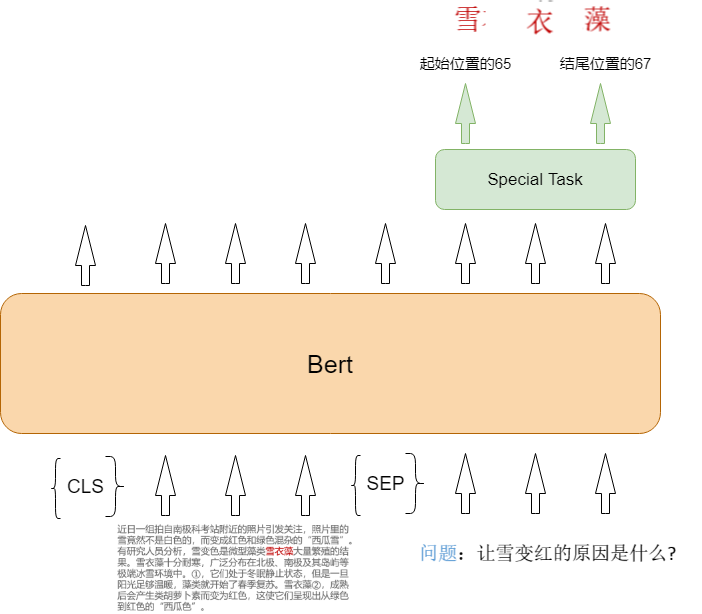
对于英文的SQuAD数据集,我们的做法和上面一模一样。
那么对于SQuAD2.0数据集来说,这个数据集中有一些没有答案的问题。我们对于这样的问题解法其实和上面没有任何区别,如果我们获得起始位置id比结束位置id大的情况,那么这种不合理的输出,我们就认为这个问题没有答案。
实践一下用Bert的效果:
# https://gas.graviti.cn/dataset/hello-dataset/SQuAD_v2 下载数据集
# 载入文本
with open('SQuAD_v2_dev-v2.json','r',encoding='utf-8') as reader:
input_data = json.load(reader)
# 看看这个json格式
input_data.keys()
squad_data = input_data['data']
print('有',len(squad_data),'个类别',)
# 看一篇文章的细节
squad_data[1].keys()
print('一个类有',len(squad_data[1]['paragraphs']),'篇文章')
squad_data[1]['paragraphs'][1].keys()
context = squad_data[1]['paragraphs'][1]['context']context
# 拿到一个问题
squad_data[1]['paragraphs'][1]['qas'][1]
question = squad_data[1]['paragraphs'][1]['qas'][1]['question']
# 得到这个题目的答案
answer = squad_data[1]['paragraphs'][1]['qas'][1]['answers']answer
# 调用Hugging Face 的API
# 使用Hugging Face 的API。Hugging Face已经帮大家训练好了Bert模型,大家可以直接用来做推理(记得注册Hugging Face)
# 推理API的调用指南:https://huggingface.co/docs/hub/inference
import json
import requests
headers = {"Authorization": f"Bearer {'此处用自己的API账号'}"} API_URL = "https://api-inference.huggingface.co/models/deepset/roberta-base-squad2"
def query(payload):
data = json.dumps(payload)
response = requests.request("POST", API_URL, headers=headers, data=data)
return json.loads(response.content.decode("utf-8"))
data = query(
{
"inputs": {
"question": question,
"context": context,
}
}
)
data['answer']
# 看看推理结果,和上边的答案是不是完全一样?
最后
这篇文章中,先是介绍了NLP的基本任务。然后以SQuAD数据集为中心,介绍了机器阅读理解任务的一些分类,知道抽取式任务是简单的,而问答任务是困难的。最后以Bert为例,介绍SQuAD数据集在Bert模型上是怎么解的。
本文为经典开源数据集介绍系列,如果有兴趣一起参与贡献,后台回复“开源数据”可加入我们。数据集已上传在开源数据平台Graviti,阅读原文可下载。