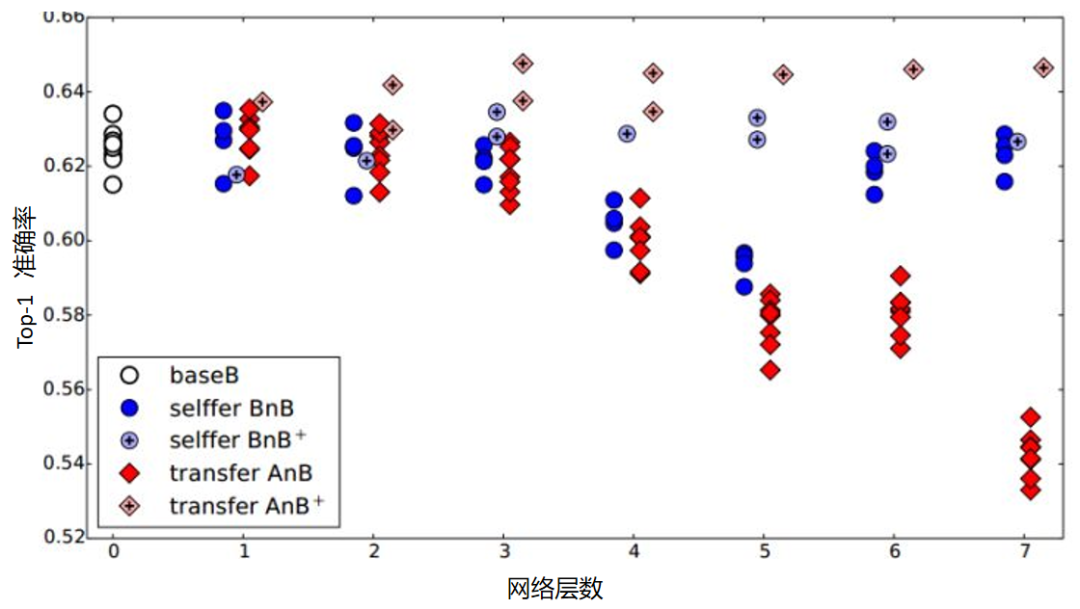
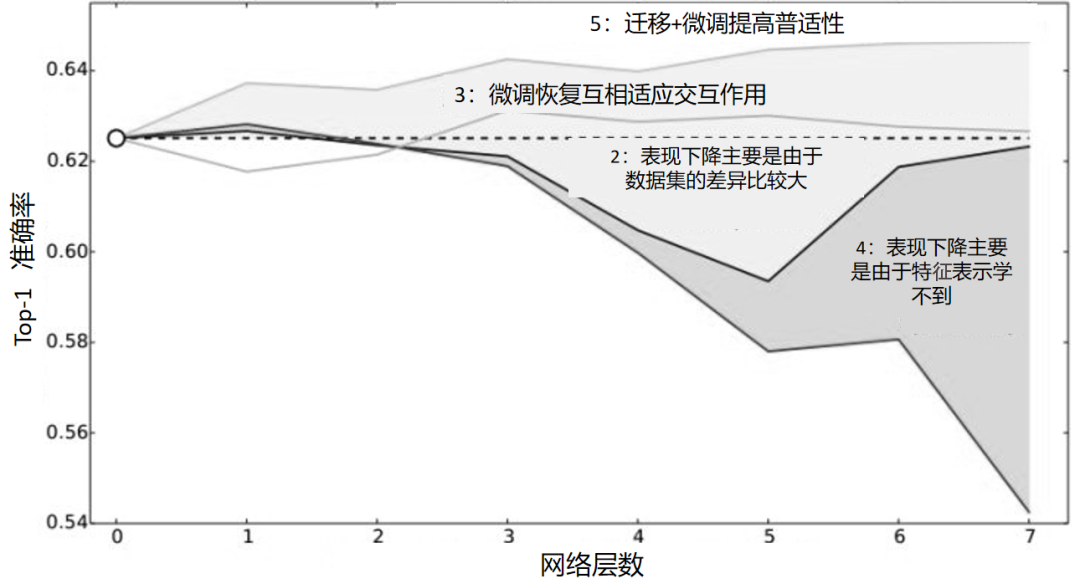
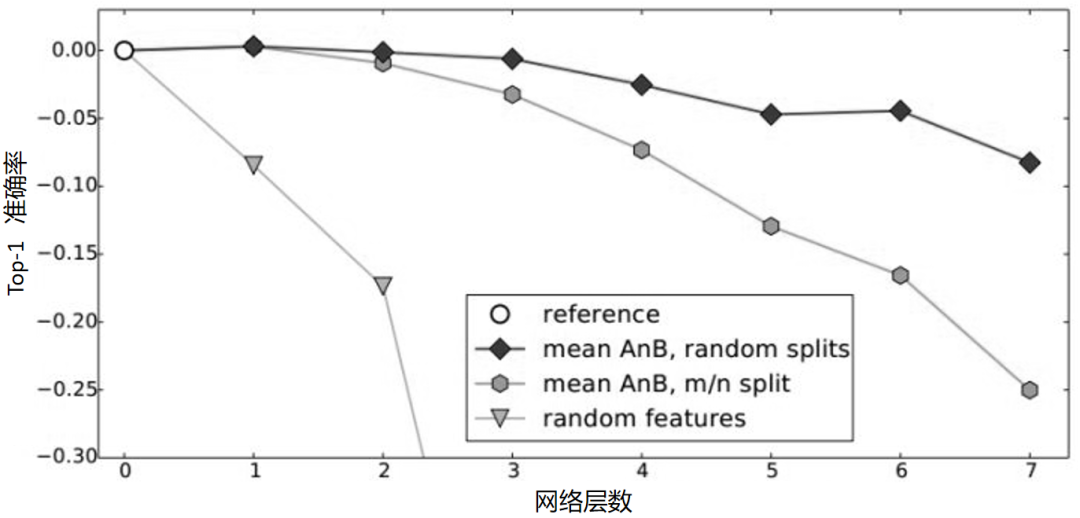
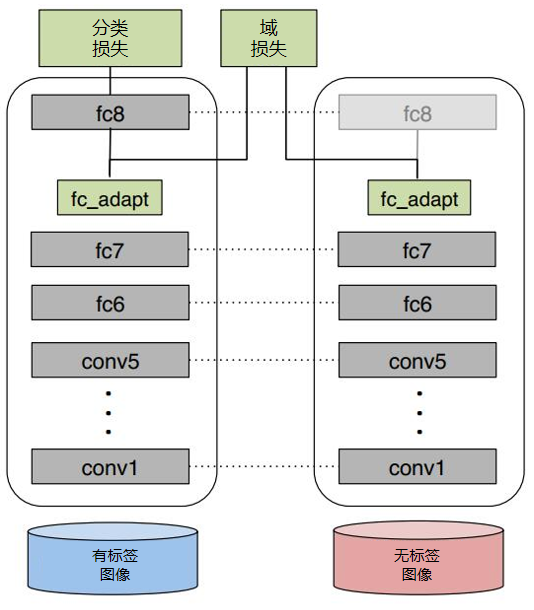
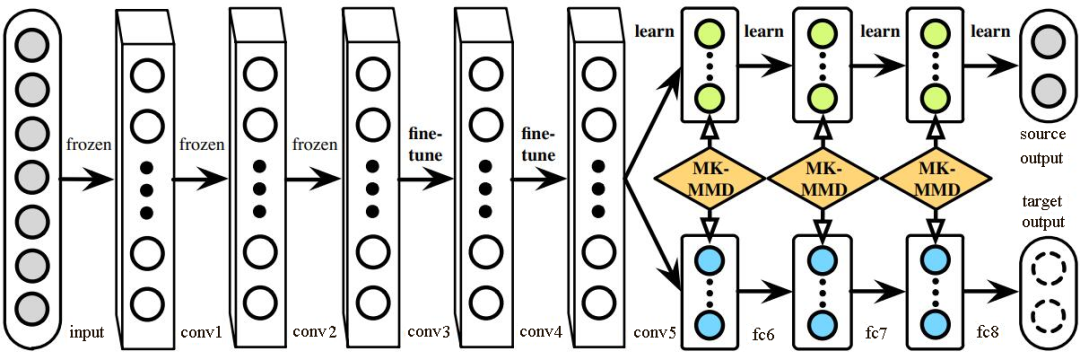
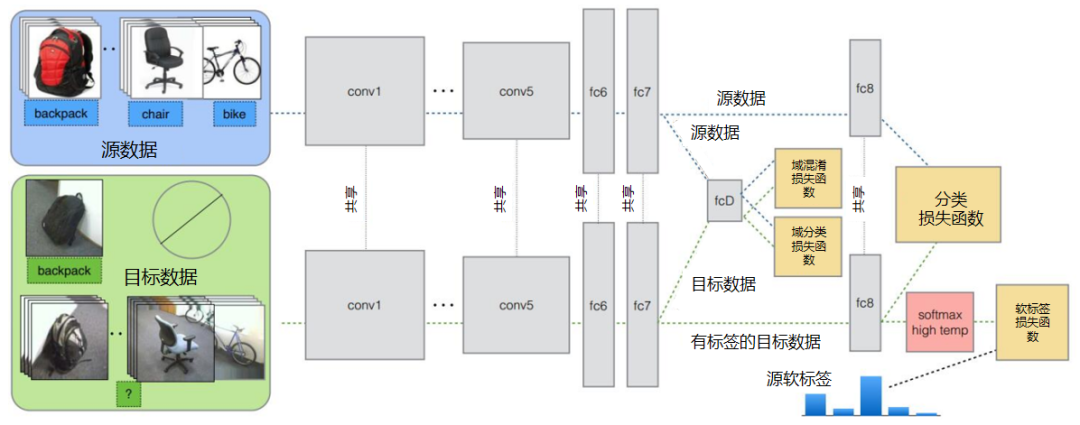
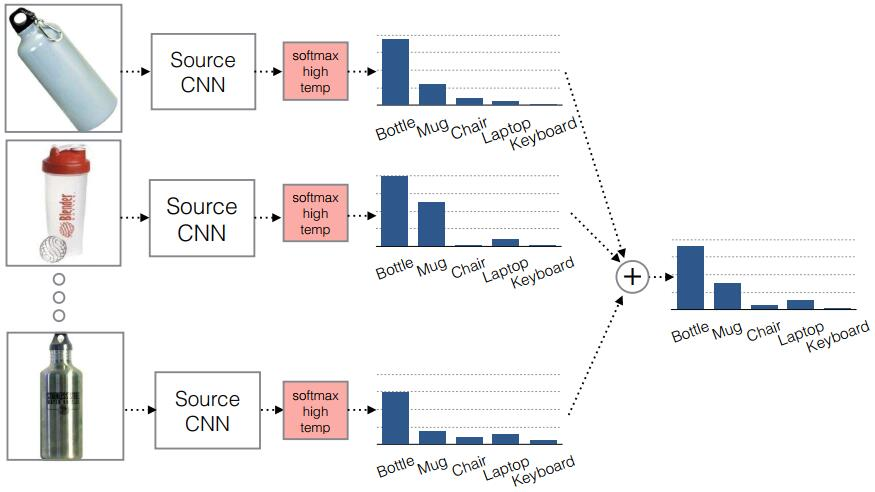
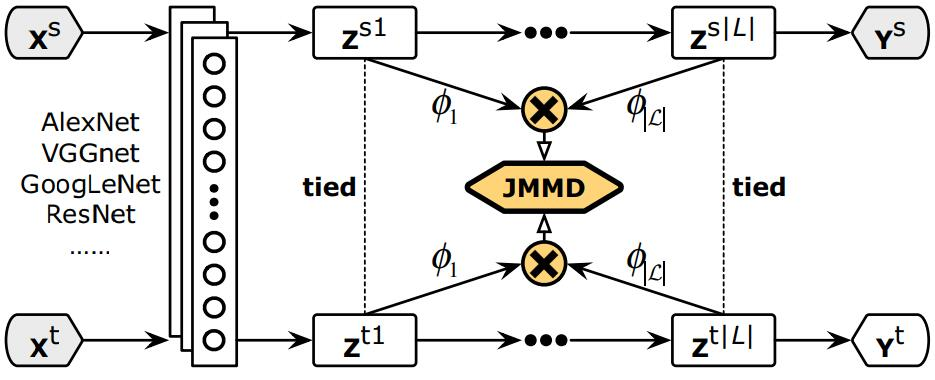
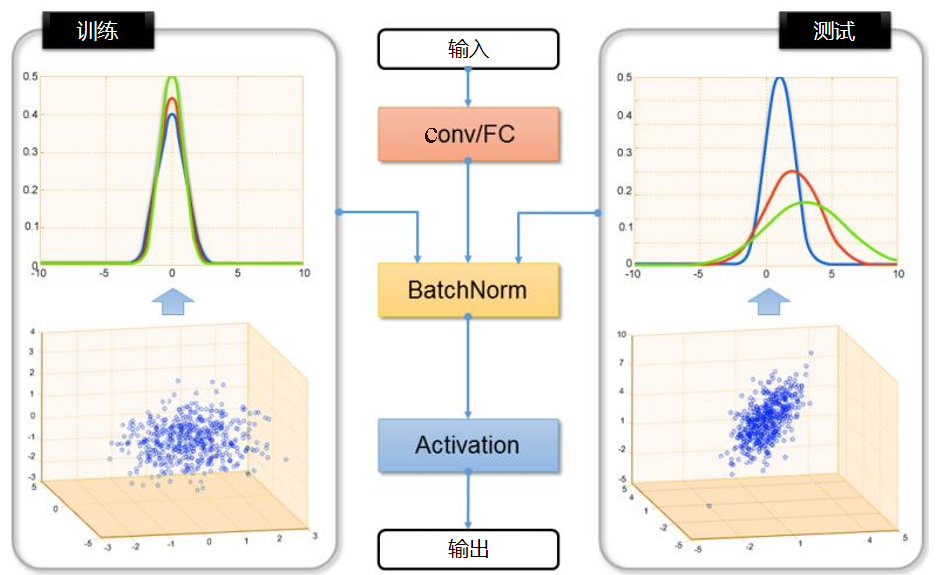
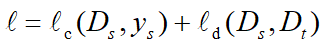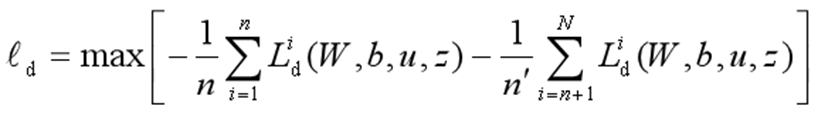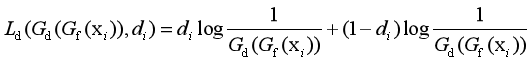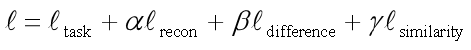(2)决定采用什么样的自适应方法(度量准则),这决定了网络的泛化能力。早期的研究者在2014年环太平洋人工智能大会(Pacific Rim International Conference on Artificial Intelligence,PRICAI)上提出了名为DANN(Domain Adaptive Neural Networks)的神经网络[Ghifary et al.,2014]。DANN的结构异常简单,它只由两层神经元——特征层神经元和分类器层神经元组成。作者的创新之处在于,在特征层后加入MMD适配层,用来计算源域和目标域的距离,并将其加入网络的损失中进行训练。但是,由于网络太浅,表征能力有限,故无法很有效地解决领域自适应问题。因此,后续的研究者大多都基于其思想进行改进,如将浅层网络改为更深层的AlexNet、ResNet、VGG等,将MMD换为多核MMD等。下面将介绍几种常见的深度网络自适应方法。▊ 基本方法(1)DDC方法。加州大学伯克利分校的Tzeng等人首先提出了DDC(Deep Domain Confusion)方法来解决深度网络的自适应问题[Tzeng et al.,2014]。DDC方法遵循了上面讨论过的基本思路,采用了在ImageNet数据集上训练好的AlexNet网络进行自适应学习[Krizhevsky et al.,2012]。下图是DDC方法示意图。DDC方法固定了AlexNet的前7层,在第8层(分类器前一层)上加入了自适应的度量。自适应度量方法采用了被广泛使用的MMD准则。 为什么选择倒数第2层?DDC方法的作者在文章中提到,他们经过多次实验,在不同的层进行了尝试,最终发现在分类器前一层加入自适应可以达到最好的效果。这与我们的认知也是相符合的。通常来说,分类器前一层即特征,在特征上加入自适应,也正是迁移学习要完成的工作。(2)DAN方法。清华大学的龙明盛等人于2015年发表在ICML(Internation Conference on Machine Learning)上的DAN(Deep Adaptation Networks)方法对DDC方法进行了几个方面的扩展[Long et al.,2015a]。首先,有别于DDC方法只加入一个自适应层,DAN方法同时加入了3个自适应层(分类器前3层)。其次,DAN方法采用表征能力更好的多核MMD(MK-MMD)度量来代替DDC方法中的单核MMD[Gretton et al.,2012]。最后,DAN方法将多核MMD的参数学习融入深度网络的训练中,并且未额外增加网络的训练时间。DAN方法在多个任务上都取得了比DDC方法更好的分类效果。为什么适配3层?原来的DDC方法只适配了1层,现在DAN方法基于AlexNet网络,适配最后3层(第6、7、8层)。因为Jason在文献[Yosinski et al.,2014]中已经提出,网络的迁移能力从这3层开始就会有特定的任务倾向,所以要着重适配这3层。至于别的网络(如GoogLeNet、VGG等)是不是适配这3层就需要通过自己的实验来验证,要注意的是DAN方法只关注AlexNet。DAN方法示意图如下。(3)同时迁移领域和任务的方法。DDC方法的作者Tzeng在2015年扩展了DDC方法,提出了领域和任务同时迁移的方法[Tzeng et al.,2015]。他提出网络要进行两部分迁移。一是域迁移(Domain Transfer),尤其指适配边缘分布,但没有考虑类别信息。域迁移就是在传统深度网络的损失函数上,再加一个混淆损失(Confusion Loss)函数,两个损失函数一起计算。二是任务迁移(Task Transfer),就是利用类别之间的相似度进行不同任务间的学习。举个类别之间相似度的例子:杯子与瓶子更相似,而它们与键盘不相似。现有的深度迁移学习方法通常都只考虑域迁移,而没有考虑类别之间的信息。如何把域迁移和任务迁移结合起来,是一个需要研究的问题。Tzeng针对目标任务的部分类别有少量标签,剩下的类别无标签的情况,提出名为域迁移和任务迁移的联合CNN体系结构(Joint CNN Architecture For Domain and Task Transfer)。其最大的创新之处在于,提出现有的方法都忽略了类别之间的联系,并提出在现有损失函数的基础上还要再加一个软标签损失(Soft Label Loss)函数。意思就是在源域和目标域进行适配时,也要根据源域的类别分布情况来调整目标域。相应地,他提出的方法就是把这两个损失函数结合到一个新的CNN网络上,这个CNN是基于AlexNet修改而来的。总的损失函数由3部分组成,第1部分是普通训练的损失函数,第2部分是域自适应的损失函数,第3部分是目标域上的软标签损失函数。下图为同时迁移领域和任务的方法示意图。该网络由AlexNet修改而来,前面几层无变化,区别是在fc7层后面加入了一个域分类器,在该层实现域自适应,在fc8层后计算网络的损失函数和软标签损失函数。那么什么是软标签损失?软标签损失就是不仅要适配源域和目标域的边缘分布,还要把类别信息考虑进去。具体做法如下,在网络对源域进行训练时,把源域中的每一个样本处于每一个类的概率都记下来,然后,对于所有样本,属于每一个类的概率就可以通过先求和再求平均数得到。下为软标签损失示意图。这样做的目的是,根据源域中的类别分布关系,来对目标域做相应的约束。(4)JAN方法。DAN方法的作者龙明盛2017年在ICML上提出了JAN(Joint Adaptation Networks)方法[Long et al.,2017],在深度网络中同时进行联合分布的自适应和对抗学习。JAN方法将只对数据进行自适应的方式推广到了对类别的自适应上,提出了JMMD度量(Joint MMD)。下为JAN方法示意图。(5)AdaBN方法。与上述研究选择在已有网络层中增加适配层不同,北京大学的H Li和图森科技的N Wang等人提出了AdaBN(Adaptive Batch Normalization)方法[Li et al.,2018],其通过在归一化层加入统计特征的适配来完成迁移。下图是AdaBN方法示意图。
▊ 核心方法(1)DANN方法。Yaroslav Ganin等人首先在迁移学习中加入了对抗机制,并将他们的网络称为DANN(Domain-Adversarial Neural Networks)方法[Ganin et al.,2016]。在此研究中,网络的学习目标是,生成的特征尽可能帮助区分两个领域的特征,同时使判别器无法对两个领域的差异进行判别。该方法的领域对抗损失函数表示为:
其中
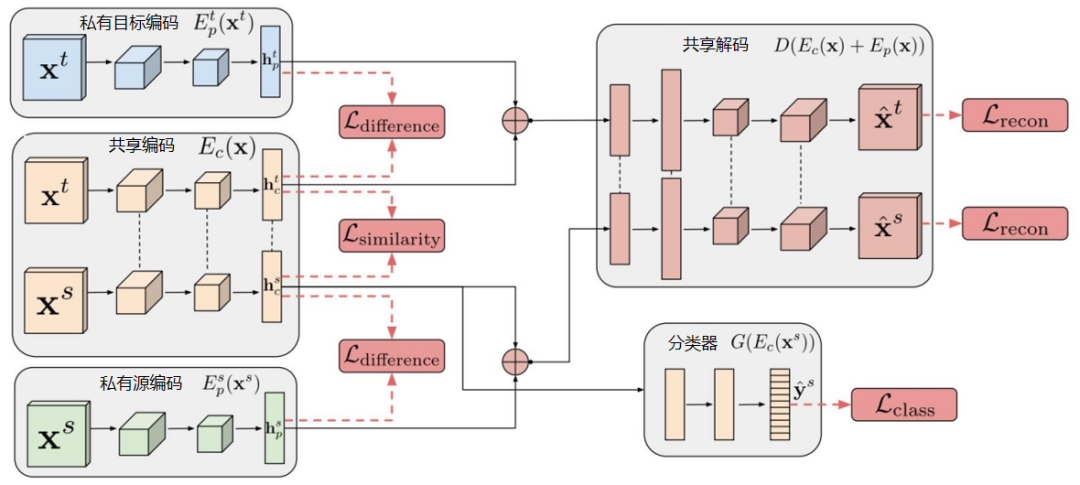
(2)DSN方法。来自Google Brain的Bousmalis等人提出DSN(Domain Separation Networks)方法对DANN进行了扩展[Bousmalis et al.,2016]。DSN方法认为,源域和目标域都由两部分构成:公共部分和私有部分。公共部分可以学习公共的特征,私有部分用来保持各个领域独立的特性。DSN方法进一步对损失函数进行了定义。
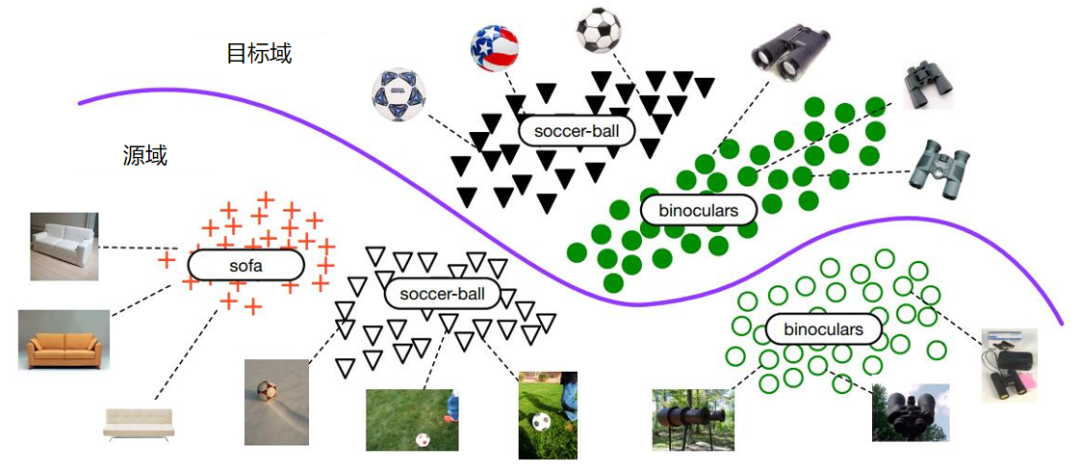
其具体含义如下。 为网络常规训练的损失函数。 为重构损失函数,确保私有部分仍然对学习目标有作用。公共部分与私有部分的差异损失函数。 源域和目标域公共部分的相似性损失函数。如下是DSN方法示意图。(3)SAN方法。清华大学龙明盛等人2018年发表在CVPR(Computer Vision and Pattern Recognition)上的文章提出了部分迁移学习(Partial Transfer Learning)。作者认为,在大数据时代,通常我们会有大量的源域数据。这些源域数据与目标域数据相比,在类别上通常更为丰富。例如,基于ImageNet训练的图像分类器,必然是针对几千个类别进行的分类。在实际应用时,目标域往往只是其中的一部分类别。这样就会带来一个问题:那些只存在于源域中的类别在迁移时,会对迁移结果产生负迁移影响。这种情况是非常普遍的,因此,就要求相应的迁移学习方法能够对目标域选择相似的源域样本(类别),同时也要避免负迁移。但是目标域通常是没有标签的,因此我们并不知道它和源域中哪个类别更相似。作者称这个问题为部分迁移学习(Partial Transfer Learning)。Partial即只迁移源域中和目标域相关的那部分样本。下图展示了部分迁移学习示意图。作者提出了名为选择性对抗网络(Selective Adversarial Networks,SAN)的方法来处理选择性迁移问题[Cao et al.,2017]。在该问题中,传统的对抗网络不再适用。所以需要对其进行一些修改,使它能够适用于选择性迁移问题。