
一份最新的、全面的NLP文本分类综述|模型&代码&技巧

Paper:Deep Learning Based Text Classification: A Comprehensive Review(Computer Science, Mathematics-ArXiv)2020
Link:https://arxiv.org/pdf/2004.03705.pdf
这是一份最新的、全面的NLP文本分类综述,也是在你入门之后,想要进一步挖掘、深入阅读自己感兴趣的领域方向的一份指南。
文本讨论的基于深度学习的模型在各种文本分类任务(包括情感分析,新闻分类,问题回答和自然语言推理)已经超越了基于经典机器学习的方法。
TL; DR
提供了150多个用于文本分类的深度学习模型的详细概述,它们的技术贡献,相似性和优势。 介绍了使用深度学习模型构建文本分类器的方法。 给出了如何给自己的任务选择最佳的神经网络模型的建议。 总结了40多个流行的文本分类数据集。 在16个主流的基准上进行深度学习模型性能的定量分析。 讨论了基于深度学习的文本分类现存的挑战和未来的方向。
其他关键词和短语:文本分类,情感分析,问题解答,新闻分类,深度学习,自然语言推理,主题分类。
1 文本分类任务
情感分析 新闻分类 主题分析 问答系统 自然语言推断(NLI)
2 用于文本分类的深度学习模型
本节回顾了用于文本分类任务提出的150多种DL(深度学习)模型。根据模型结构将这些模型分为几大类:
前馈网络。将文本视为词袋。 基于RNN的模型。将文本视为一系列单词,旨在捕获文本单词依存关系和文本结构。 基于CNN的模型。经过训练,可以识别文本分类的文本模式(例如关键短语)。 胶囊网络(Capsule networks)。解决了CNN在池化操作时所带来的信息丢失问题。 注意力机制。可有效识别文本中的相关单词,并已成为开发DL模型的有用工具。 内存增强网络(Memory-augmented)。将神经网络与某种外部存储器结合在一起,该模型可以读取和写入。 图神经网络。旨在捕获自然语言的内部图结构,例如句法和语义解析树。 暹罗神经网络(Siamese)。专门用于文本匹配,这是文本分类的特殊情况。 混合模型(Hybrid models)。结合了注意力,RNN,CNN等以捕获句子和文档的局部和全局特征。 Transformers。比RNN拥有更多并行处理,从而可以使用GPU高效的(预)训练非常大的语言模型。 监督学习之外的建模技术,包括使用自动编码器和对抗训练的无监督学习,以及强化学习。
更多详细模型内容请看原论文。读者应该对基本的DL模型有一定的了解,Goodfellow等人也给读者推荐了DL教科书,了解更多详情看[1]。
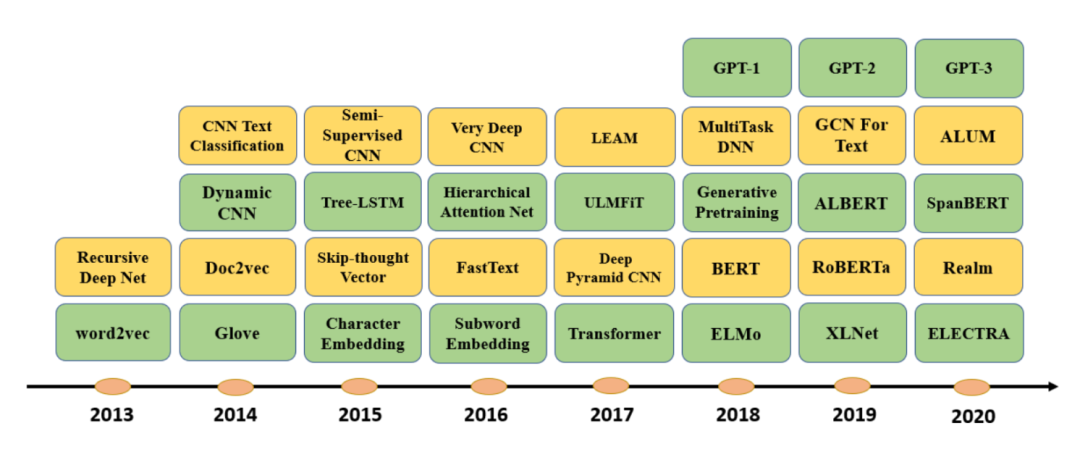
3 如何给自己的任务选择最佳的神经网络模型
对于文本分类任务来说最佳的神经网络结构是什么?这取决于目标任务和领域,领域内标签的可用性,应用程序的延迟和容量限制等,这些导致选择差异会很大。尽管毫无疑问,开发一个文本分类器是反复试错的过程,但通过在公共基准(例如GLUE [2])上分析最近的结果,我们提出了以下方法来简化该过程,该过程包括五个步骤:
选择PLM(PLM,pretraining language model预训练语言模型):使用PLM可以显着改善所有流行的文本分类任务,并且自动编码的PLM(例如BERT或RoBERTa)通常比自回归PLM(例如OpenAI GPT)更好。Hugging face拥有为各种任务开发的丰富的PLM仓库。 领域适应性:大多数PLM在通用领域的文本语料库(例如Web)上训练。如果目标领域与通用的领域有很大的不同,我们可以考虑使用领域内的数据,不断地预训练该PLM来调整PLM。对于具有大量未标记文本的领域数据,例如生物医学,从头开始进行语言模型的预先训练也可能是一个不错的选择[3]。 特定于任务的模型设计。给定输入文本,PLM在上下文表示中产生向量序列。然后,在顶部添加一个或多个特定任务的层,以生成目标任务的最终输出。特定任务层的体系结构的选择取决于任务的性质,例如,需要捕获文本的语言结构。比如,前馈神经网络将文本视为词袋,RNN可以捕获单词顺序,CNN擅长识别诸如关键短语之类的模式,注意力机制可以有效地识别文本中的相关单词,而暹罗神经网络则可以用于文本匹配任务,如果自然语言的图形结构(例如,分析树)对目标任务有用,那么GNN可能是一个不错的选择。 特定于任务的微调整。根据领域内标签的可用性,可以使用固定的PLM单独训练特定任务的层,也可以与PLM一起训练特定任务的层。如果需要构建多个相似的文本分类器(例如,针对不同领域的新闻分类器),则多任务微调[23]是利用相似领域的标记数据的好选择。 模型压缩。PLM成本很高。它们通常需要通过例如知识蒸馏[4,5]进行压缩,以满足实际应用中的延迟和容量限制。
4 文本分类的主流数据集
根据主要目标任务将各种文本分类数据集分为情感分析,新闻分类,主题分类,问答系统和NLI自然语言推断等类别。
情感分析数据集
Yelp。Yelp [6]数据集包含两种情感分类任务的数据。一种是检测细粒度的标签,称为Yelp-5。另一个预测负面和正面情绪,被称为“ Yelp评论极性”或“ Yelp-2”。Yelp-5每个类别有650,000个训练样本和50,000个测试样本,Yelp-2包含560,000个训练样本和38,000个针对积极和消极类的测试样本。 IMDb。IMDB数据集[7]是为电影评论的二分类情感分类任务而开发的。IMDB由相等数量的正面和负面评论组成。它在训练和测试集之间平均分配,每个测试集有25,000条评论。 电影评论(Movie Review)。电影评论(MR)数据集[8]是电影评论的集合,其目的是检测与特定评论相关的情绪并确定其是负面还是正面的。它包括10,662个句子,带有负面和正面的样本。通常使用10倍交叉验证和随机拆分来对此数据集进行测试。 SST。斯坦福情感树库(SST)数据集[9]是MR的扩展版本。有两个版本可用,一个带有细粒度标签(五类),另一个带有二分类的标签,分别称为SST-1和SST-2。SST-1包含11855条电影评论,分为8544个训练样本,1101个开发样本和2210个测试样本。SST-2分为三组,分别为训练集,开发集和测试集,大小分别为6,920、872和1,821。 MPQA。多视角问答(MPQA)数据集[10]是具有两个类别标签的观点语料库。MPQA包含从与各种新闻来源相关的新闻文章中提取的10606个句子,这是一个不平衡的数据集,包含3,311个肯定文档和7,293个否定文档。 亚马逊Amazon。这是从亚马逊网站[11]收集的热门产品评论集。它包含用于二分类和多类(5类)分类的标签。Amazon二进制分类数据集包含3,600,000条和40万条评论,分别用于培训和测试。亚马逊5级分类数据集(Amazon-5)分别包含3,000,000条评论和650,000条关于训练和测试的评论。
新闻分类数据集
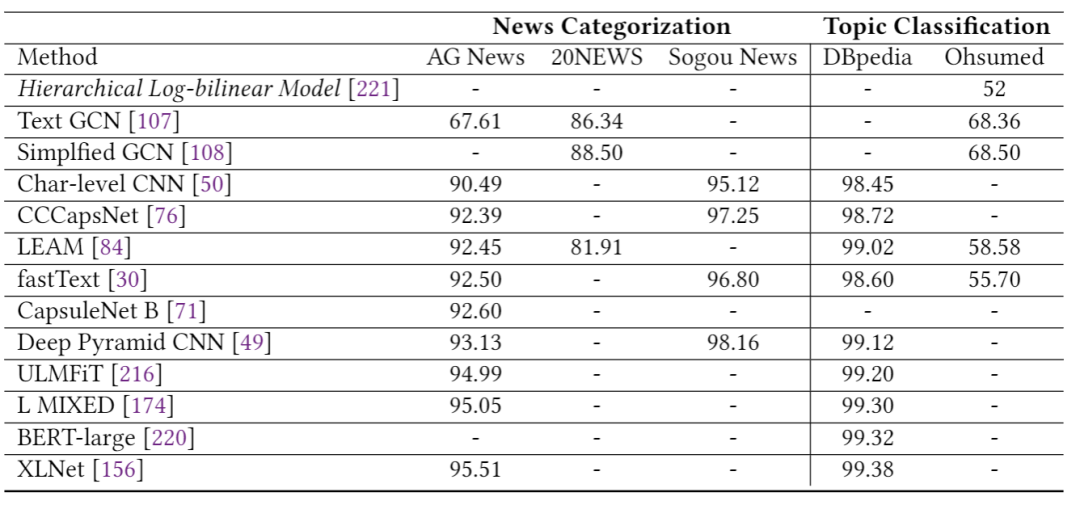
AGNews。AGNews数据集[12]是学术新闻搜索引擎ComeToMyHead从2000多个新闻源收集的新闻文章的集合。该数据集包括120,000个训练样本和7,600个测试样本。每个样本都是带有四类标签的短文本。 20个新闻组。20个新闻组数据集[13]是张贴在20个不同主题上的新闻组文档的集合。此数据集的各种版本用于文本分类,文本聚类等等。最受欢迎的版本之一包含18,821个文档,该文档在所有主题中平均分类。 搜狗新闻。搜狗新闻数据集[14]是搜狗CA和搜狗CS新闻语料的混合。新闻的分类标签由URL中的域名决定。例如,URL为http://sports.sohu.com的新闻被归为体育类。 路透社新闻Reuters。Reuters-21578数据集[15]是用于文本分类的最广泛使用的数据收集之一,它是从1987年建立了路透社金融新闻专线。ApteMod是Reuters-21578的多类版本,具有10,788个文档。它有90个课程,7,769个培训文档和3,019个测试文档。从路透社数据集的子集派生的其他数据集包括R8,R52,RCV1和RCV1-v2。为新闻分类开发的其他数据集包括:Bing新闻[16],BBC [17],Google新闻[18]。
主题分类数据集
DBpedia。DBpedia数据集[19]是大规模的多语言知识库,它是根据Wikipedia中最常用的信息框创建的。DBpedia每月发布一次,并且在每个发行版中添加或删除一些类和属性。DBpedia最受欢迎的版本包含560,000个训练样本和70,000个测试样本,每个样本都带有14类标签。 Ohsumed。Ohsumed集合[20]是MEDLINE数据库的子集。总计包含7,400个文档。每个文档都是医学摘要,用从23种心血管疾病类别中选择的一个或多个类别来标记。 EUR-Lex。EUR-Lex数据集[21]包含不同类型的文档,它们根据几种正交分类方案进行索引,以允许多个搜索设施。该数据集的最流行版本基于欧盟法律的不同方面,有19,314个文档和3,956个类别。 WOS。Web Of Science(WOS)数据集[22]是可从以下网站获取的已发表论文的数据和元数据的集合Web of Science,是世界上最受信任的发行商独立的全球引文数据库。WOS已发布三个版本:WOS-46985,WOS-11967和WOS-5736。WOS-46985是完整的数据集。WOS-11967和WOS-5736是WOS-46985的两个子集。 PubMed。PubMed [23]是由美国国家医学图书馆为医学和生物科学论文开发的搜索引擎,其中包含文档集合。每个文档都标有MeSH集的类,而MeSH集是PubMed中使用的标签集。摘要中的每个句子均使用以下类别之一标记其摘要中的角色:背景,目标,方法,结果或结论。 其他用于主题分类的数据集包括PubMed 200k RCT [24],Irony(由anno组成)来自社交新闻网站reddit的注解,Twitter数据集(用于推文的主题分类,arXivcollection)[25],仅举几例。
QA问答数据集
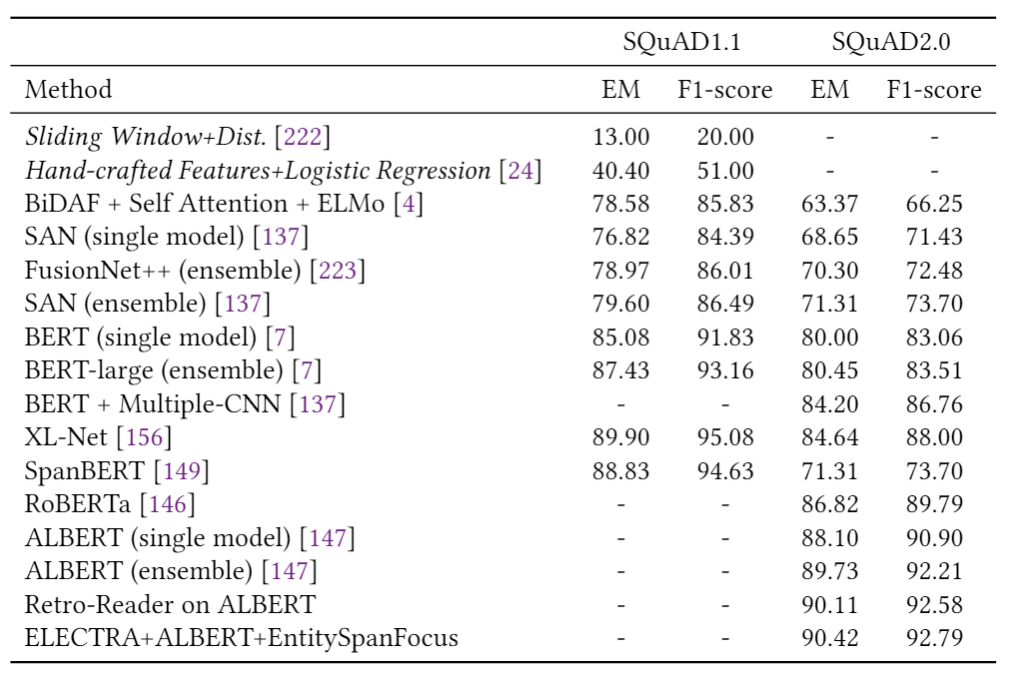
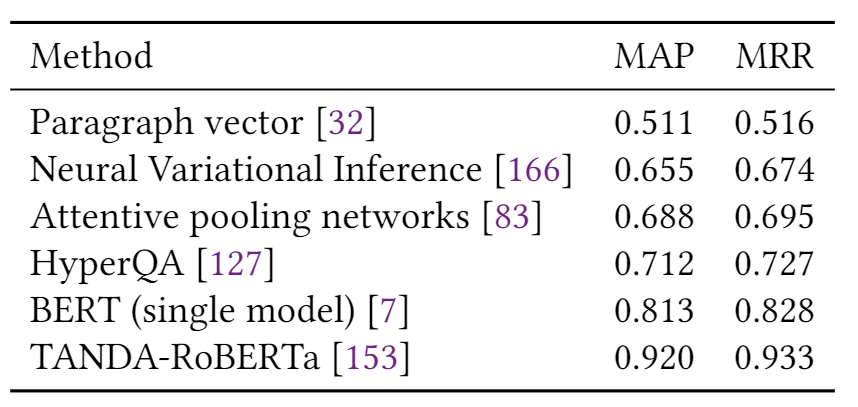
SQuAD。Stanford问答数据集(SQuAD)[26]是从Wikipedia文章派生的问题-答案对的集合。在SQuAD中,问题的正确答案可以是给定文本中的任何令牌序列。由于问题和答案是由人类通过众包产生的,因此它比其他一些问答数据集更具多样性。SQuAD 1.1包含536篇文章中的107,785个问题-答案对。最新版本的SQuAD2.0将SQuAD1.1中的100,000个问题与超过50,000个由反抗工作者以对抗形式写的对抗性问题相结合[27] 。 MS MARCO。此数据集由Microsoft[28]发布。不像SQuAD那样所有的问题都是由编辑产生的;在MS MARCO中,所有的问题都是使用必应搜索引擎从用户的查询和真实的网络文档中抽取的。MS MARCO的一些回答是有创造力的。因此,该数据集可用于生成QA系统的开发。 TREC-QA。TREC-QA [29]是用于QA研究的最受欢迎和研究最多的数据集之一。该数据集有两个版本,称为TREC-6和TREC-50。TREC-6分为6个类别的问题,而TREC-50则为20个类别。对于这两个版本,训练和测试数据集分别包含5,452和500个问题。 WikiQA。WikiQA数据集[30]由一组问题-答案对组成,它们被收集并注释以用于开放域QA研究。该数据集还包含没有正确答案的问题,使研究人员可以评估答案触发模型。 Quora。Quora数据库[31]用于释义识别(检测重复的问题)。为此,作者提出了Quora数据的子集,该子集包含超过40万个问题对。为每个问题对分配一个二进制值,指示两个问题是否相同。其他质量检查数据集包括对抗生成情况(SWAG)[32],WikiQA [30],SelQA [33]。
NLI数据集
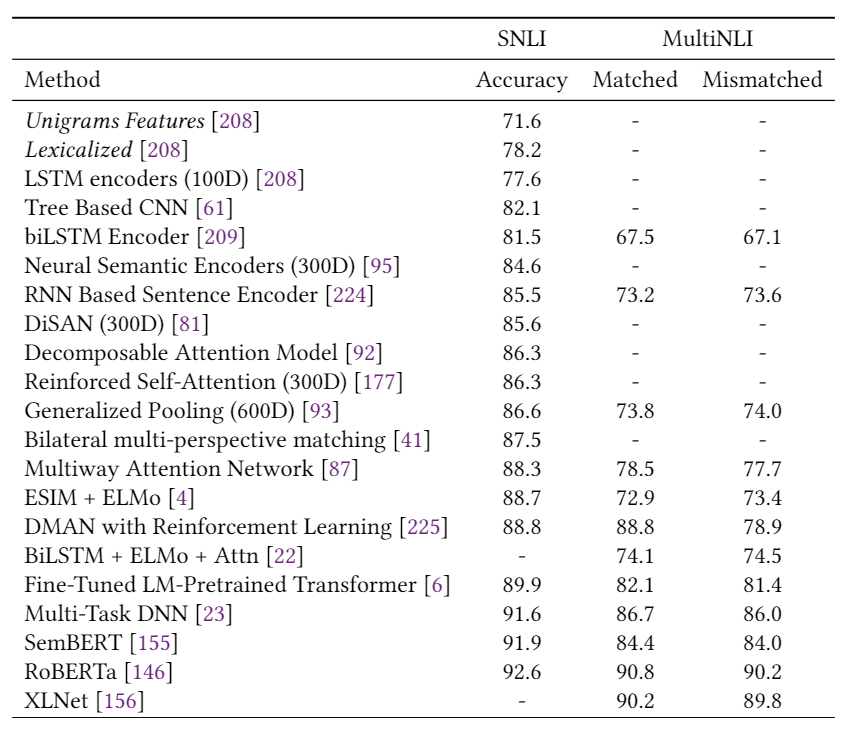
SNLI。斯坦福自然语言推理(SNLI)数据集[34]被广泛用于NLI。该数据集由550,152、10,000和10,000个句子对组成,分别用于训练,开发和测试。每对使用三个标签之一进行注释:中立,包含,矛盾。 Multi-NLI。多体裁自然语言推理(MNLI)数据集[35]是一个433k句子对的集合,这些句子对带有文本包含标签。语料库是SNLI的扩展,涵盖了广泛的口语和书面语体裁,并支持独特的跨体裁概括评估 SICK。包含构词知识的句子数据集(SICK)[36]包含大约10,000个英语句子对,并用三个标签进行注释:蕴涵,矛盾和中立。 MSRP。MicrosoftResearch Paraphrase(MSRP)数据集[37]通常用于文本相似性任务。MSRP包括用于训练的4,076个样本和用于测试的1,725个样本。每个样本都是一个句子对,并带有二进制标记,指示两个句子是否为释义。其他NLI数据集包括语义文本相似性(STS)[38],RTE [39],SciTail [40],仅举几例。
5 实验性能分析
在本节中,我们首先描述一组通常用于评估文本分类模型性能的指标,然后根据流行的基准对一组基于DL的文本分类模型的性能进行定量分析。
文本分类的流行评估指标
准确性和错误率(Accuracy and Error Rate)。这些是评估分类模型质量的主要指标。令TP,FP,TN,FN分别表示真积极,假积极,真消极和假消极。分类精度和错误率在等式中定义如下:
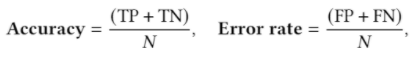
𝑁是样本总数。显然,我们的 Error Rate= 1-Accuracy 。
精度/召回率/ F1分数(Precision / Recall / F1 score)。这些也是主要指标,在不平衡的测试集中比准确性或错误率更常用,例如,大多数测试样品都带有一个类别标签。二进制分类的精度和召回率定义为3. F1分数是精度和查全率的调和平均值,如等式。3. F1分数在1(最佳精度和召回率)达到最佳值,在0达到最差值
 对于多类别分类问题,我们始终可以为每个类别标签计算精度和召回率,并分析类别标签上的各个性能,或者对这些值取平均值以获取整体精度和召回率。
对于多类别分类问题,我们始终可以为每个类别标签计算精度和召回率,并分析类别标签上的各个性能,或者对这些值取平均值以获取整体精度和召回率。
Exact Match(EM)。精确匹配度量标准是问答系统的一种流行度量标准,它可以测量与任何一个基本事实答案均精确匹配的预测百分比。EM是用于SQuAD的主要指标之一。 Mean Reciprocal Rank(MRR)。MRR通常用于评估NLP任务中的排名算法的性能,例如查询文档排名和QA。MRR在等式中定义。在图4中,𝑄是所有可能答案的集合,,是真相答案的排名位置。
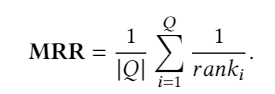 其他广泛使用的指标包括平均精度Mean Average Precision(MAP),曲线下面积 Area Under Curve(AUC),错误发现率False DiscoveryRate,错误遗漏率False Omission Rate,仅举几例。
其他广泛使用的指标包括平均精度Mean Average Precision(MAP),曲线下面积 Area Under Curve(AUC),错误发现率False DiscoveryRate,错误遗漏率False Omission Rate,仅举几例。
定量结果
我们将先前讨论的几种算法在流行的TC基准上的性能列表化。在每个表中,除了一组代表性的DL模型的结果之外,我们还使用非深度学习模型来介绍结果,该模型不是现有技术而是在DL时代之前被广泛用作基准。我们可以看到,在所有这些任务中,DL模型的使用带来了显着的改进。
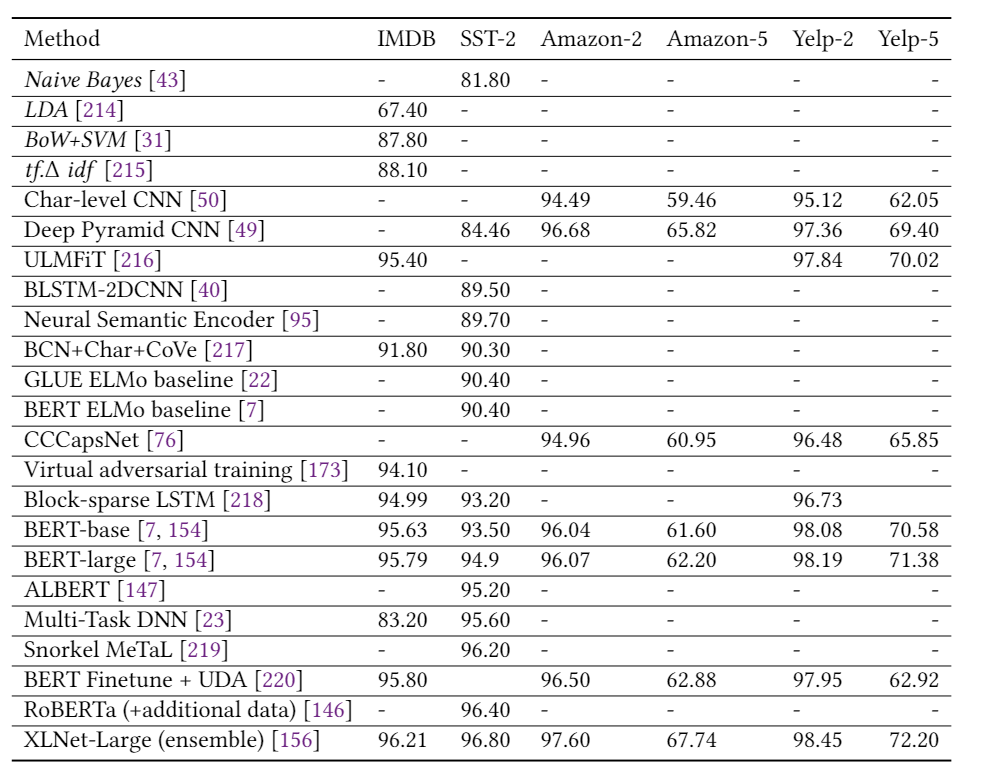
表1总结了第2节中描述的模型在多个情感分析数据集上的结果,包括Yelp,IMDB,SST和Amazon。我们可以看到,自从引入第一个基于DL的情感分析模型以来,准确性得到了显着提高,例如,相对减少的分类误差(在SST-2上约为78%)。 表2报告了三个新闻分类数据集的性能(即AG新闻,20-新闻,搜狗新闻)和两个主题分类数据集(即DBpedia和Ohsummed)。观察到与情绪分析相似的趋势。 表3和表4分别显示了一些DL模型在SQuAD和WikiQA上的性能。值得注意的是,这两个数据集的显着性能提升都归功于BERT的使用。 表5给出了两个NLI数据集(即SNLI和MNLI)的结果。在过去的5年中,我们观察到两个数据集的性能都有稳定的提高。
6 挑战与机遇
在过去的几年中,借助DL模型,文本分类取得了很大的进步。已经提出了一些新颖的思路(例如神经嵌入,注意力机制,自我注意力,Transformer,BERT和XLNet),这些思想导致了过去十年的快速发展。尽管取得了进展,但仍有挑战需要解决。本节介绍了其中一些挑战,并讨论了可以帮助推动该领域发展的研究方向。
针对更具挑战性任务的新数据集。尽管近年来已收集了许多常见的文本分类任务的大规模数据集,但仍需要针对更具挑战性的文本分类任务的新数据集,例如具有多步推理的QA,针对多语言文档的文本分类,用于极长的文档的文本分类。 对常识知识进行建模。将常识整合到DL模型中具有潜在地提高模型性能的能力,这几乎与人类利用常识执行不同任务的方式相同。例如,配备常识性知识库的QA系统可以回答有关现实世界的问题。常识知识还有助于解决信息不完整的情况下的问题。人工智能系统使用广泛持有的关于日常对象或概念的信念,可以以与人们类似的方式基于对未知数的“默认”假设进行推理。尽管已经对该思想进行了情感分类研究,但仍需要进行大量研究以探索如何在DL模型中有效地建模和使用常识知识。 不可预测的DL模型。虽然DL模型在具有挑战性的基准上取得了可喜的性能,但是其中大多数模型都是无法解释的。例如,为什么一个模型在一个数据集上胜过另一个模型,而在其他数据集上
本文部分素材来源于网络,如有侵权,联系删除。
回顾精品内容
推荐系统
机器学习
自然语言处理(NLP)
1、AI自动评审论文,CMU这个工具可行吗?我们用它评审了下Transformer论文
2、Transformer强势闯入CV界秒杀CNN,靠的到底是什么"基因"
计算机视觉(CV)
1、9个小技巧让您的PyTorch模型训练装上“涡轮增压”...
GitHub开源项目:
1、火爆GitHub!3.6k Star,中文版可视化神器现身
2、两次霸榜GitHub!这个神器不写代码也可以完成AI算法训练
每周推荐:
1、本周优秀开源项目分享:无脑套用格式、开源模板最高10万赞
2、本周优秀开源项目分享:YOLOv4的Pytorch存储库、用pytorch增强图像数据等7大项目
七月在线学员面经分享:
1、 双非应届生拿下大厂NLP岗40万offer:面试经验与路线图分享
2、转行NLP拿下40万offer:分享我面试中遇到的54道面试题(含参考答案)
3、NLP面试干货分享:从自考本科 在职硕士到BAT年薪80万