
NLP(五十三)在Keras中使用英文Roberta模型实现文本分类
英文Roberta模型是2019年Facebook在论文RoBERTa: A Robustly Optimized BERT Pretraining Approach中新提出的预训练模型,其目的是改进BERT模型存在的一些问题,当时也刷新了一众NLP任务的榜单,达到SOTA效果,其模型和代码已开源,放在Github中的fairseq项目中。众所周知,英文Roberta模型使用Torch框架训练的,因此,其torch版本模型最为常见。
当然,torch模型也是可以转化为tensorflow模型的。本文将会介绍如何将原始torch版本的英文Roberta模型转化为tensorflow版本模型,并且Keras中使用tensorflow版本模型实现英语文本分类。
项目结构如下图所示:
 项目结构图
项目结构图模型转化
本项目首先会将原始torch版本的英文Roberta模型转化为tensorflow版本模型,该部分代码主要参考Github项目keras_roberta。
首先需下载Facebook发布在fairseq项目中的roberta base模型,其访问网址为: https://github.com/pytorch/fairseq/blob/main/examples/roberta/README.md。
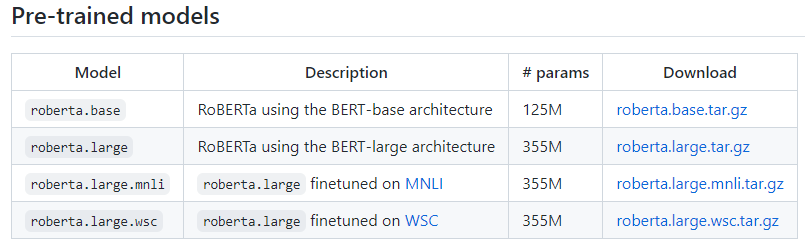 Roberta模型
Roberta模型运行
convert_roberta_to_tf.py脚本,将torch模型转化为tensorflow模型。具体代码不在此给出,可以参考文章后续给出的Github项目地址。在模型的tokenizer方面,将RobertaTokenizer改为GPT2Tokenizer,因为RobertaTokenizer是继承自GPT2Tokenizer的,两者相似性很高。测试原始torch模型和tensorflow模型的表现,代码如下(tf_roberta_demo.py):
import os
import tensorflow as tf
from keras_roberta.roberta import build_bert_model
from keras_roberta.tokenizer import RobertaTokenizer
from fairseq.models.roberta import RobertaModel as FairseqRobertaModel
import numpy as np
import argparse
if __name__ == '__main__':
roberta_path = 'roberta-base'
tf_roberta_path = 'tf_roberta_base'
tf_ckpt_name = 'tf_roberta_base.ckpt'
vocab_path = 'keras_roberta'
config_path = os.path.join(tf_roberta_path, 'bert_config.json')
checkpoint_path = os.path.join(tf_roberta_path, tf_ckpt_name)
if os.path.splitext(checkpoint_path)[-1] != '.ckpt':
checkpoint_path += '.ckpt'
gpt_bpe_vocab = os.path.join(vocab_path, 'encoder.json')
gpt_bpe_merge = os.path.join(vocab_path, 'vocab.bpe')
roberta_dict = os.path.join(roberta_path, 'dict.txt')
tokenizer = RobertaTokenizer(gpt_bpe_vocab, gpt_bpe_merge, roberta_dict)
model = build_bert_model(config_path, checkpoint_path, roberta=True) # 建立模型,加载权重
# 编码测试
text1 = "hello, world!"
text2 = "This is Roberta!"
sep = [tokenizer.sep_token]
cls = [tokenizer.cls_token]
# 1. 先用'bpe_tokenize'将文本转换成bpe tokens
tokens1 = cls + tokenizer.bpe_tokenize(text1) + sep
tokens2 = sep + tokenizer.bpe_tokenize(text2) + sep
# 2. 最后转换成id
token_ids1 = tokenizer.convert_tokens_to_ids(tokens1)
token_ids2 = tokenizer.convert_tokens_to_ids(tokens2)
token_ids = token_ids1 + token_ids2
segment_ids = [0] * len(token_ids1) + [1] * len(token_ids2)
print(token_ids)
print(segment_ids)
print('\n ===== tf model predicting =====\n')
our_output = model.predict([np.array([token_ids]), np.array([segment_ids])])
print(our_output)
print('\n ===== torch model predicting =====\n')
roberta = FairseqRobertaModel.from_pretrained(roberta_path)
roberta.eval() # disable dropout
input_ids = roberta.encode(text1, text2).unsqueeze(0) # batch of size 1
print(input_ids)
their_output = roberta.model(input_ids, features_only=True)[0]
print(their_output)
输出结果如下:
[0, 42891, 6, 232, 328, 2, 2, 713, 16, 1738, 102, 328, 2]
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
===== tf model predicting =====
[[[-0.01123665 0.05132651 -0.02170264 ... -0.03562857 -0.02836962
-0.00519008]
[ 0.04382067 0.07045364 -0.00431021 ... -0.04662359 -0.10770167
0.1121687 ]
[ 0.06198474 0.05240346 0.11088232 ... -0.08883709 -0.02932207
-0.12898633]
...
[-0.00229368 0.045834 0.00811818 ... -0.11751424 -0.06718166
0.04085271]
[-0.08509324 -0.27506304 -0.02425355 ... -0.24215901 -0.15481825
0.17167582]
[-0.05180666 0.06384835 -0.05997407 ... -0.09398533 -0.05159672
-0.03988626]]]
===== torch model predicting =====
tensor([[ 0, 42891, 6, 232, 328, 2, 2, 713, 16, 1738,
102, 328, 2]])
tensor([[[-0.0525, 0.0818, -0.0170, ..., -0.0546, -0.0569, -0.0099],
[-0.0765, -0.0568, -0.1400, ..., -0.2612, -0.0455, 0.2975],
[-0.0142, 0.1184, 0.0530, ..., -0.0844, 0.0199, 0.1340],
...,
[-0.0019, 0.1263, -0.0787, ..., -0.3986, -0.0626, 0.1870],
[ 0.0127, -0.2116, 0.0696, ..., -0.1622, -0.1265, 0.0986],
[-0.0473, 0.0748, -0.0419, ..., -0.0892, -0.0595, -0.0281]]],
grad_fn=)
可以看到,两者在tokenize时的token_ids是一致的。
英语文本分类
接着我们需要看下转化为的tensorflow版本的Roberta模型在英语文本分类数据集上的效果了。
这里我们使用的是GLUE数据集中的SST-2。SST-2(The Stanford Sentiment Treebank,斯坦福情感树库),单句子分类任务,包含电影评论中的句子和它们情感的人类注释。这项任务是给定句子的情感,类别分为两类正面情感(positive,样本标签对应为1)和负面情感(negative,样本标签对应为0),并且只用句子级别的标签。也就是,本任务也是一个二分类任务,针对句子级别,分为正面和负面情感。关于该数据集的具体介绍可参考网址:https://nlp.stanford.edu/sentiment/index.html。
SST-2数据集中训练集样本数量为67349,验证集样本数量为872,测试集样本数量为1820,数据存储格式为tsv,读取数据的代码如下:(utils/load_data.py)
def read_model_data(file_path):
data = []
with open(file_path, 'r', encoding='utf-8') as f:
lines = [_.strip() for _ in f.readlines()]
for i, line in enumerate(lines):
if i:
items = line.split('\t')
label = [0, 1] if int(items[1]) else [1, 0]
data.append([label, items[0]])
return data
在tokenizer部分,我们采用GTP2Tokenizer,该部分代码如下(utils/roberta_tokenizer.py):
# roberta tokenizer function for text pair
def tokenizer_encode(tokenizer, text, max_seq_length):
sep = [tokenizer.sep_token]
cls = [tokenizer.cls_token]
# 1. 先用'bpe_tokenize'将文本转换成bpe tokens
tokens1 = cls + tokenizer.bpe_tokenize(text) + sep
# 2. 最后转换成id
token_ids = tokenizer.convert_tokens_to_ids(tokens1)
segment_ids = [0] * len(token_ids)
pad_length = max_seq_length - len(token_ids)
if pad_length >= 0:
token_ids += [0] * pad_length
segment_ids += [0] * pad_length
else:
token_ids = token_ids[:max_seq_length]
segment_ids = segment_ids[:max_seq_length]
return token_ids, segment_ids
创建模型如下(model_train.py):
# 构建模型
def create_cls_model():
# Roberta model
roberta_model = build_bert_model(CONFIG_FILE_PATH, CHECKPOINT_FILE_PATH, roberta=True) # 建立模型,加载权重
for layer in roberta_model.layers:
layer.trainable = True
cls_layer = Lambda(lambda x: x[:, 0])(roberta_model.output) # 取出[CLS]对应的向量用来做分类
p = Dense(2, activation='softmax')(cls_layer) # 多分类
model = Model(roberta_model.input, p)
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(1e-5), # 用足够小的学习率
metrics=['accuracy']
)
return model
模型参数如下:
# 模型参数配置
EPOCH = 10 # 训练轮次
BATCH_SIZE = 64 # 批次数量
MAX_SEQ_LENGTH = 80 # 最大长度
模型训练完后,在验证数据集上的准确率(accuracy)为0.9415,F1值为0.9415,取得了不错效果。
模型预测
我们对新样本进行模型预测(model_predict.py),预测结果如下:
Awesome movie for everyone to watch. Animation was flawless.
label: 1, prob: 0.9999607I almost balled my eyes out 5 times. Almost. Beautiful movie, very inspiring.
label: 1, prob: 0.9999519Not even worth it. It's a movie that's too stupid for adults, and too crappy for everyone. Skip if you're not 13, or even if you are.
label: 0, prob: 0.9999864
总结
本文介绍了如何将原始torch版本的英文Roberta模型转化为tensorflow版本模型,并且Keras中使用tensorflow版本模型实现英语文本分类。
本项目代码已放至Github,网址为:https://github.com/percent4/keras_roberta_text_classificaiton。
感谢阅读,如有任何问题,欢迎大家交流~
参考网址
fairseq: https://github.com/pytorch/fairseqGLUE tasks: https://gluebenchmark.com/tasksSST-2: https://nlp.stanford.edu/sentiment/index.htmlkeras_roberta: https://github.com/midori1/keras_robertaRoberta paper: https://arxiv.org/pdf/1907.11692.pdf