
Flink CEP的基石:NFA-b自动机原理简介
点击上方蓝色字体,选择“设为星标”




前言
Flink的复杂事件处理(complex event processing, CEP)库能够在无界数据流中通过匹配定义好的事件模式来发现一系列事件之间的关联规律,从而有效支持趋势分析、风险监控、欺诈检测等业务场景。它提供了一套简单易用、表达性强的API,例如,在10秒的时间窗口内检测事件的报警级别:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val partitionedInput = sourceStream.keyBy(event => event.getId)
// start[] -> middle[name = 'error'] -> .. -> end[name = 'critical'] within 10 secs
val pattern = Pattern.begin[Event]("start")
.next("middle").where(_.getName == "error")
.followedBy("end").where(_.getName == "critical")
.within(Time.seconds(10))
val patternStream = CEP.pattern(partitionedInput, pattern)
val alerts = patternStream.select(createAlert(_))那么,Flink CEP是采用什么方法匹配事件规则的呢?在源码注释中,可以得知它是基于《Efficient Pattern Matching over Event Streams》这篇论文的思想实现的。该论文提出了一种在事件流上进行高效模式匹配的方法,即带匹配缓存的非确定有限状态机,又称为NFAb自动机。本文先介绍NFAb自动机的相关原理,在之后的文章中,再结合源码讲解Flink CEP库的具体实现。
NFAb自动机的定义与构造
在大学《形式语言与自动机》课程中,我们都学习过非确定有限状态机(NFA),用一句话概括就是:对于每个<状态,输入符号>二元组,其状态转移可以有多个,而不是确定的一个。NFAb自动机的形式化定义与普通NFA略有不同,为五元组:

其中:
Q为状态集合;
E为表示状态转移的有向边集合;
θ为表示状态转移的公式集合,与E共同作用;
q1表示起始状态;
F表示结束状态。
下面通过实例来构造NFAb自动机。先通过SASE+语言(一种专门用来描述CEP pattern的通用语言)定义如下的股票趋势匹配模式:
PATTERN SEQ(Stock+ a[], Stock b)
WHERE skip_till_next_match(a[], b) {
[symbol] // 表示只考虑相同的事件类型,此处恒为真
AND a[1].volume > 1000
AND a[i].price > avg(a[..i-1].price)
AND b.volume < 80% * a[a.LEN].volume
} WITHIN 1 hour // 时间窗口该模式以1小时作为时间窗口的长度,以“交易量大于1000”作为匹配序列的起始,且要求序列中股票的最近价格必须高于之前所有交易价格的均值。当检测到该股票的交易量下跌到最近一次交易量的80%以下时,匹配成功结束。
根据上面的条件,构造出NFAb自动机,如下图所示。这也是Flink CEP中NFACompiler组件需要做的事情。
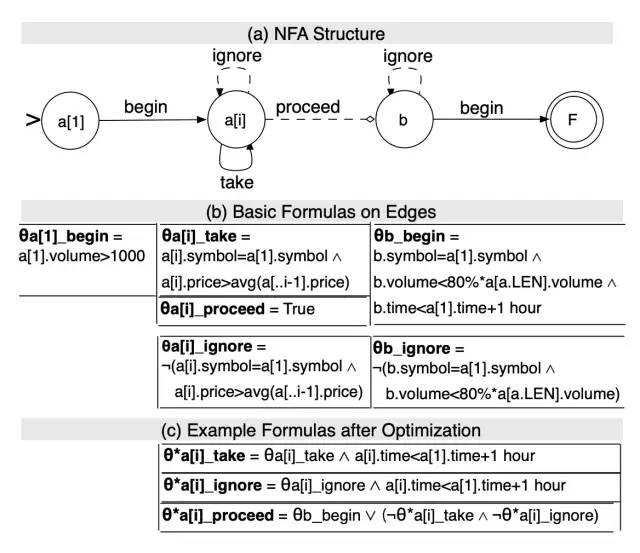
注意∧符号表示与,∨符号表示或,┐符号表示非
匹配序列a[]的生成实际上就是构造符合谓词约束的事件的正闭包Stock+ a[](克林闭包去掉ε)。也就是说,a[1]是上述自动机的起始状态(交易量大于1000),a[i]是正在构造正闭包的状态(最近价格高于之前所有交易价格的均值)。而b是从闭包中跳出并匹配下一事件的状态(交易量下跌到最近一次交易量的80%以下)。
NFAb自动机的每个状态都有各自的匹配缓存,用于在运行时存储当前的匹配结果。关于匹配缓存的细节,后文会讲到。
状态转移语义
复杂事件的匹配过程本质上就是输入事件流驱动NFAb自动机进行状态转移的过程。根据θ集合定义的条件,在有向边集合E上可以定义4种状态转移语义。
begin:消费输入事件,存入缓存,并转移到下一个状态;
take:消费输入事件,存入缓存,并保持当前状态;
ignore:忽略输入事件,不存入缓存,并保持当前状态;
proceed:感知输入事件,转移到下一个状态,同时保留该事件给下一个状态处理。
结合这4种状态转移语义,我们就可以读懂上图中的转移公式了。Flink CEP的StateTransitionAction定义中没有begin语义,仅有take、ignore和proceed语义,但是它和NFAb自动机是等价的,之后分析源码时将会看到。
事件选择策略
所谓事件选择策略,就是指选择符合条件的事件进入正闭包——即扩展匹配序列的方法。在时间窗口的限制之内,常用的有以下三种策略。
strict(严格连续):严格按顺序选择所有符合条件的事件,途中不能出现不符合条件的事件,对应Flink CEP API中的
Pattern.next()/notNext();skip till next match(宽松连续):按顺序选择所有符合条件的事件,而途中不符合条件的事件被忽略,对应Flink CEP API中的
Pattern.followedBy()/notFollowedBy()。上述SASE+语言描述的pattern使用的就是这个策略;skip till any match(可变宽松连续):在skip till next match的基础上,还允许忽略一些符合条件的事件,以尽量延长匹配序列的长度,对应Flink CEP API中的
Pattern.followedByAny()。
以skip till next match策略为例,给出如下的示例数据,可以产生3个匹配序列R1、R2、R3,如图所示。
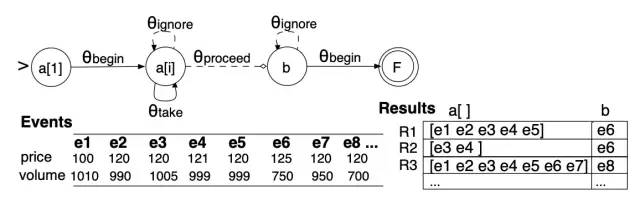
共享版本匹配缓存
仍然考虑上一节的图,回顾一下a[i]状态的take和proceed转移逻辑:

可见,在e6到达NFA时,可以同时满足a[i]_take和a[i]_proceed的转移(这里正好体现出了NFA的不确定性),所以原本的一个序列会在此分裂成两个:其中一个(R1)终止匹配,另一个(R3)继续匹配。同理,当e3到达NFA时,同时满足a[1]_begin和a[i]_take的转移,所以又会出现一个序列R2。
由上可知,这些序列之间的重合是比较大的,如果都按原样存储在匹配缓存中,会造成比较大的膨胀。为了避免这个问题,论文中设计了一种科学的缓存结构,称为shared versioned match buffer,即“共享版本匹配缓存”,如下图所示。
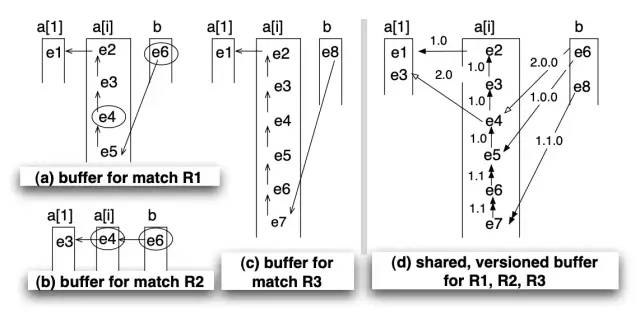
其中图a、b、c是原始的R1、R2、R3缓存,图d则是整合在一起的共享版本缓存。它会将所有序列的前向指针附加上一个版本号(采用杜威十进制法,点号分隔),并且遵循以下两个规则:
迁移到下一个状态时,版本号增加一位,如a[1]状态的版本号是1(为了符合习惯写作1.0),a[i]状态的版本号是1.0、1.1,b状态的版本号是1.0.0、1.1.0……以此类推;
当序列发生分裂时,处于当前状态的版本号位加1。例如e3事件产生了2.0版本,e6事件产生了1.1版本。
依照这种规则,就可以根据前向指针上版本号的递增规律和前缀来回溯出正确的序列了。Flink CEP中将此缓存设计为SharedBuffer类,但是版本的设计有些不同,之后再提。
计算状态
对于每一个序列,NFAb自动机还需要维护一些最基础的状态数据,以方便执行状态转移和匹配逻辑,论文中将其称为computation state,即计算状态。基础的计算状态结构如下图所示,包含以下数据项:
当前的版本号;
当前的状态;
指向匹配缓存中最近一个事件的指针;
整个序列的起始时间;
其他必要的上下文数据存储。以股票趋势数据为例,会维护正闭包内的事件数、价格之和以及交易量等。

Flink CEP框架用ComputationState类来维护计算状态,大体思路与论文相同。


版权声明:
文章不错?点个【在看】吧! ?