
对抗性攻击的原理简介

来源:Deephub Imba 本文约2200字,建议阅读5分钟
本文介绍了对抗性攻击的原理。
由于机器学习算法的输入形式是一种数值型向量(numeric vectors),所以攻击者就会通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击。和其他攻击不同,对抗性攻击主要发生在构造对抗性数据的时候,该对抗性数据就如正常数据一样输入机器学习模型并得到欺骗的识别结果。
什么是对抗样本?


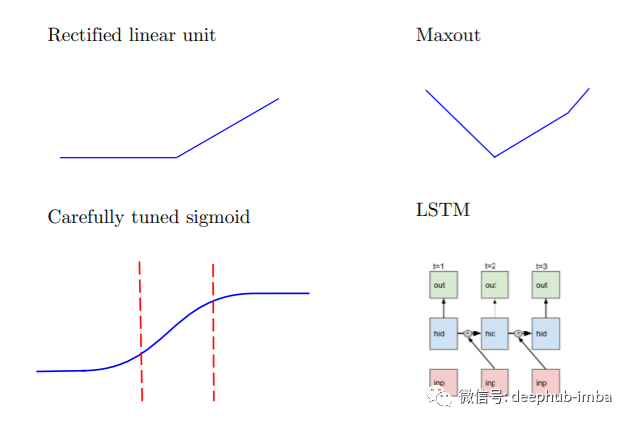
为什么会发生对抗性攻击?
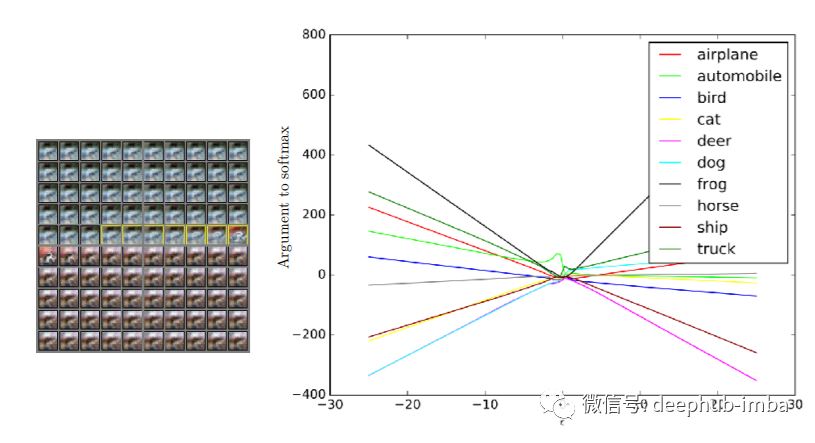
它们如何被用来破坏机器学习系统?
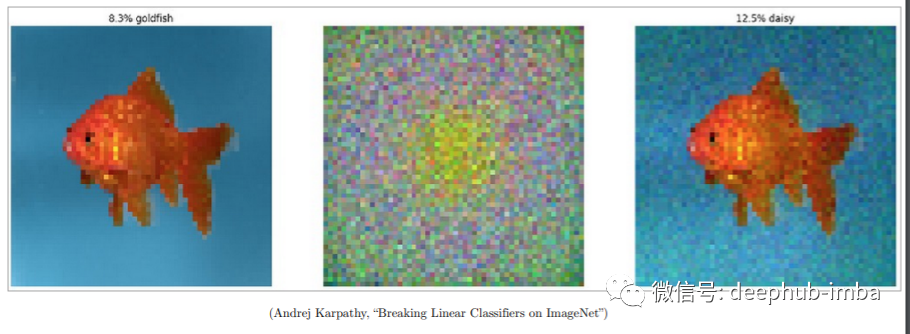
有哪些防御措施?
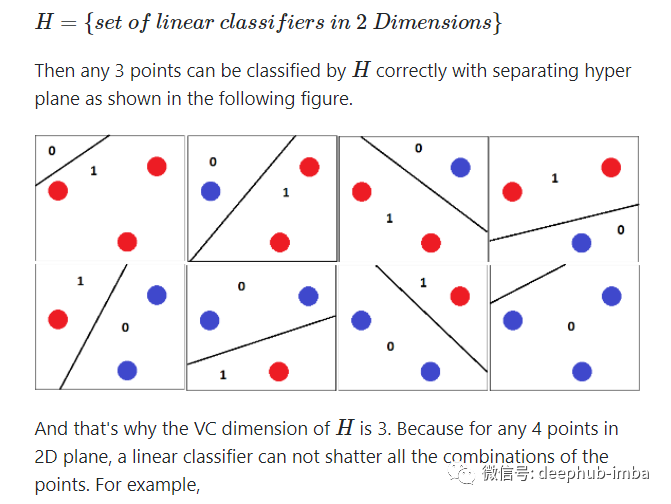

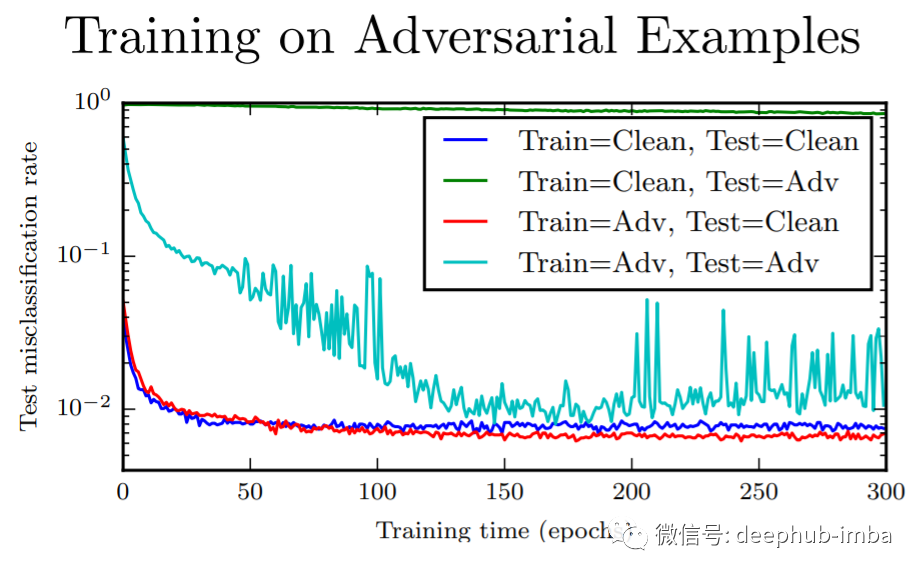

线性模型:支持向量机/线性回归不能学习阶跃函数,所以对抗训练的用处不大,作用非常类似于权值衰减 k-NN:对抗训练容易过度拟合。
结论
神经网络实际上可以变得比其他模型更安全。对抗性训练的神经网络在任何机器学习模型的对抗性示例上都具有最佳的经验成功率。 对抗训练提供正则化和半监督学习 进攻很简单 防守很困难
编辑:王菁
校对:林亦霖
评论