
Flink 原理 | Flink 执行引擎:流批一体的融合之路
背景 流批一体的分层架构 流批一体DataStream 流批一体DAG Scheduler 流批一体的Shuffle架构 流批一体的容错策略 未来展望
一、背景


人力成本比较高。由于流和批是两套系统,相同的逻辑需要两个团队开发两遍。 数据链路冗余。在很多的场景下,流和批计算内容其实是一致,但是由于是两套系统,所以相同逻辑还是需要运行两遍,产生一定的资源浪费。 数据口径不一致。这个是用户遇到的最重要的问题。两套系统、两套算子,两套 UDF,一定会产生不同程度的误差,这些误差给业务方带来了非常大的困扰。这些误差不是简单依靠人力或者资源的投入就可以解决的。
二、流批一体的分层架构
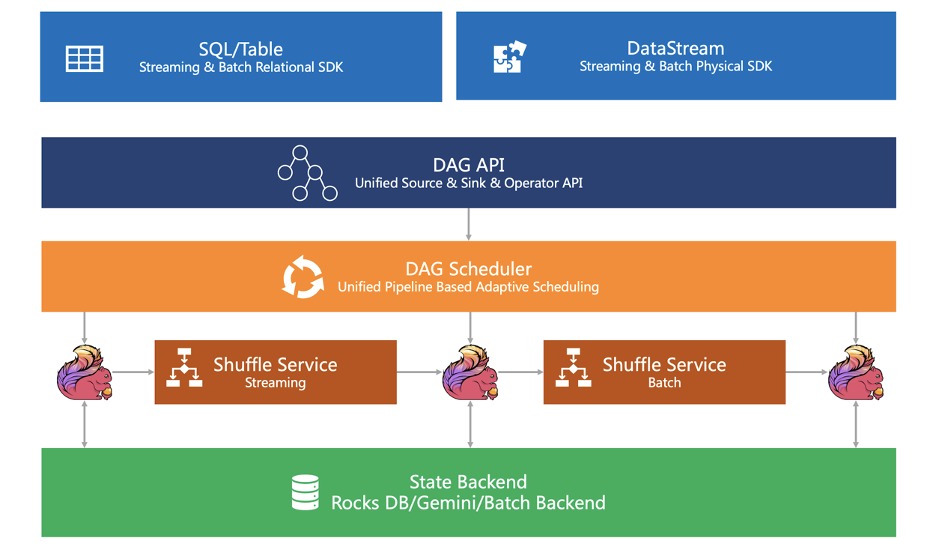
SDK 层。Flink 的 SDK 主要有两类,第一类是关系型 Relational SDK 也就是 SQL/Table,第二类是物理型 Physical SDK 也就是 DataStream。这两类 SDK 都是流批统一,即不管是 SQL 还是 DataStream,用户的业务逻辑只要开发一遍,就可以同时在流和批的两种场景下使用; 执行引擎层。执行引擎提供了统一的 DAG,用来描述数据处理流程 Data Processing Pipeline(Logical Plan)。不管是流任务还是批任务,用户的业务逻辑在执行前,都会先转化为此 DAG 图。执行引擎通过 Unified DAG Scheduler 把这个逻辑 DAG 转化成在分布式环境下执行的Task。Task 之间通过 Shuffle 传输数据,我们通过 Pluggable Unified Shuffle 架构,同时支持流批两种 Shuffle 方式; 状态存储。状态存储层负责存储算子的状态执行状态。针对流作业有开源 RocksdbStatebackend、MemoryStatebackend,也有商业化的版本的GemniStateBackend;针对批作业我们在社区版本引入了 BatchStateBackend。
流批一体的 DataStream 介绍了如何通过流批一体的 DataStream 来解决 Flink SDK 当前面临的挑战; 流批一体的 DAG Scheduler 介绍了如何通过统一的 Pipeline Region 机制充分挖掘流式引擎的性能优势;如何通过动态调整执行计划的方式来改善引擎的易用性,提高系统的资源利用率; 流批一体的 Shuffle 架构介绍如何通过一套统一的 Shuffle 架构既可以满足不同 Shuffle 在策略上的定制化需求,同时还能避免在共性需求上的重复开发; 流批一体的容错策略介绍了如何通过统一的容错策略既满足批场景下容错又可以提升流场景下的容错效果。
三、流批一体 DataStream
SDK 分析以及面临的挑战

Table/SQL 是一种 Relational 的高级 SDK,主要用在一些数据分析的场景中,既可以支持 Bounded 也可以支持 Unbounded 的输入。由于 Table/SQL 是 Declarative 的,所以系统可以帮助用户进行很多优化,例如根据用户提供的Schema,可以进行 Filter Push Down 谓词下推、按需反序列二进制数据等优化。目前 Table/SQL 可以支持 Batch 和 Streaming 两种执行模式。[1] DataStream 属于一种 Physical SDK。Relatinal SDK 功能虽然强大,但也存在一些局限:不支持对 State、Timer 的操作;由于 Optimizer 的升级,可能导致用相同的 SQL 在两个版本中出现物理执行计划不兼容的情况。而 DataStream SDK,既可以支持 State、Timer 维度 Low Level 的操作,同时由于 DataStream 是一种 Imperative SDK,所以对物理执行计划有很好的“掌控力”,从而也不存在版本升级导致的不兼容。DataStream 目前在社区仍有很大用户群,例如目前未 Closed 的 DataStream issue 依然有近 500 个左右。虽然 DataStream 即可以支持 Bounded 又可以支持 Unbounded Input 用 DataStream 写的 Application,但是在 Flink-1.12 之前只支持 Streaming 的执行模式。 DataSet 是一种仅支持 Bounded 输入的 Physical SDK,会根据 Bounded 的特性对某些算子进行做一定的优化,但是不支持 EventTime 和 State 等操作。虽然 DataSet 是 Flink 提供最早的一种 SDK,但是随着实时化和数据分析场景的不断发展,相比于 DataStream 和 SQL,DataSet 在社区的影响力在逐步下降。
利用已有 Physical SDK 无法写出一个真正生产可以用的流批一体的 Application。例如用户写一个程序用来处理 Kafka 中的实时数据,那么利用相同的程序来处理存储在 OSS/S3/HDFS 上的历史数据也是非常自然的事情。但是目前不管是 DataSet 还是 DataStream 都无法满足用户这个“简单”的诉求。大家可能觉得奇怪,DataStream 不是既支持 Bounded 的 Input 又支持 Unbounded 的 Input,为什么还会有问题呢?其实“魔鬼藏在细节中”,我会在 Unified DataStream 这一节中会做进一的阐述。 学习和理解的成本比较高。随着 Flink 不断壮大,越来越多的新用户加入 Flink 社区,但是对于这些新用户来说就要学习两种 Physical SDK。和其他引擎相比,用户入门的学习成本是相对比较高的;两种 SDK 在语义上有不同的地方,例如 DataStream 上有 Watermark、EventTime,而 DataSet 却没有,对于用户来说,理解两套机制的门槛也不小;由于这两 SDK 还不兼容,一个新用户一旦选择错误,将会面临很大的切换成本。
Unified Physical SDK

为什么选择 DataStream 作为 Unified Physical SDK?
Unified DataStream 比“老”的 DataStream 提供了哪些能力让用户可以写出一个真正生产可以用的流批一体 Application?
为什么不是 Unified DataSet
用户收益。在前边已经分析过,随着 Flink 社区的发展,目前 DataSet 在社区的影响力逐渐下降。如果选择使用 DataSet 作为 Unified Physical SDK,那么用户之前在 DataStream 大量“投资”就会作废。而选择 DataStream,可以让许多用户的已有 DataStream “投资”得到额外的回报; 开发成本。DataSet 过于古老,缺乏大量对于现代实时计算引擎基本概念的支持,例如 EventTime、Watermark、State、Unbounded Source 等。另外一个更深层的原因是现有 DataSet 算子的实现,在流的场景完全无法复用,例如 Join 等。而对于 DataStream 则不然,可以进行大量的复用。那么如何在流批两种场景下复用 DataStream 的算子呢?
Unified DataStream
效率
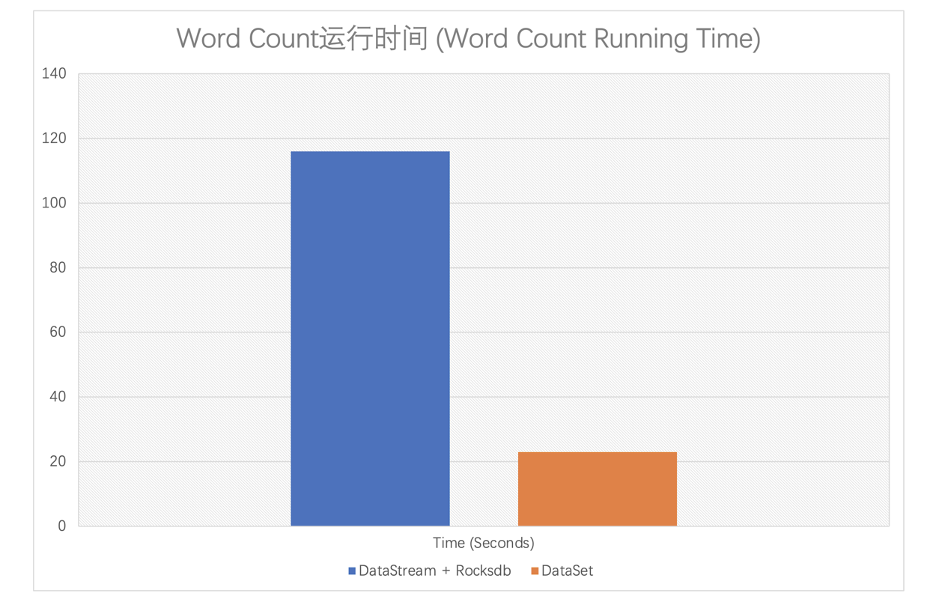
一致性
资源消耗大: 使用 Streaming 方式,需要同时拿到所有的资源。在某些情况下,用户可能没有这么多资源; 容错成本高: 在 Bounded 场景下,为了效率一些算子可能无法支持 Snapshot 操作,一旦出错可能需要重新执行整个作业。
What to commit? How to commit? Where to commit? When to commit?
四、流批一体 DAG Scheduler
Unified DAG Scheduler 要解决什么问题
一种是流的调度模式,在这种模式下,Scheduler 会申请到一个作业所需要的全部资源,然后同时调度这个作业的全部 Task,所有的 Task 之间采取 Pipeline 的方式进行通信。批作业也可以采取这种方式,并且在性能上也会有很大的提升。但是对于运行比较长的 Batch 作业来说来说,这种模式还是存在一定的问题:规模比较大的情况下,同时消耗的资源比较多,对于某些用户来说,他可能没有这么多的资源;容错代价比较高,例如一旦发生错误,整个作业都需要重新运行。 一种是批的调度模式。这种模式和传统的批引擎类似,所有 Task 都是可以独立申请资源,Task 之间都是通过 Batch Shuffle 进行通讯。这种方式的好处是容错代价比较小。但是这种运行方式也存在一些短板。例如,Task 之间的数据都是通过磁盘来进行交互,引发了大量的磁盘 IO。
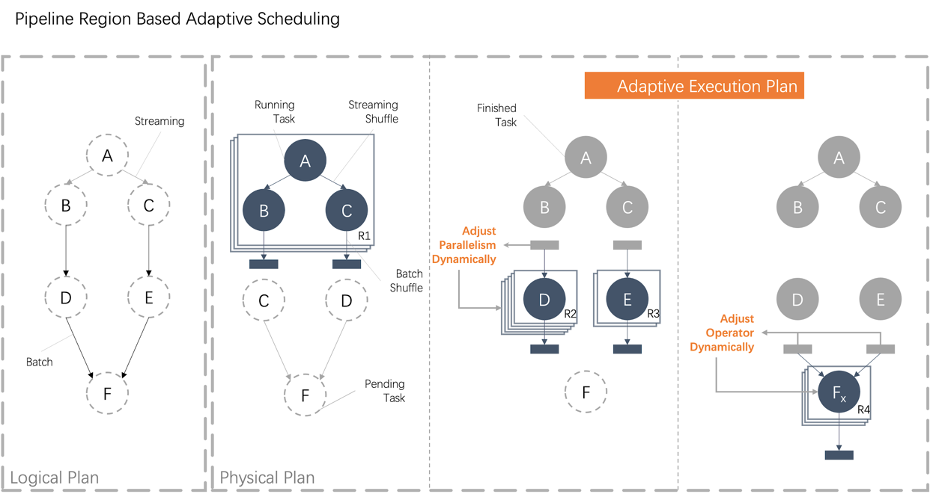
架构不一致、维护成本高。调度的本质就是进行资源的分配,换句话说就是要解决 When to deploy which tasks to where 的问题。原有两种调度模式,在资源分配的时机和粒度上都有一定的差异,最终导致了调度架构上无法完全统一,需要开发人员维护两套逻辑。例如,流的调度模式,资源分配的粒度是整个物理执行计划的全部 Task;批的调度模式,资源分配的粒度是单个任务,当 Scheduler 拿到一个资源的时候,就需要根据作业类型走两套不同的处理逻辑; 性能。传统的批调度方式,虽然容错代价比较小,但是引入大量的磁盘 I/O,并且性能也不是最佳,无法发挥出 Flink 流式引擎的优势。实际上在资源相对充足的场景下,可以采取“流”的调度方式来运行 Batch 作业,从而避免额外的磁盘 I/O,提高作业的执行效率。尤其是在夜间,流作业可以释放出一定资源,这就为批作业按照“Streaming”的方式运行提供了可能。 自适应。目前两种调度方式的物理执行计划是静态的,静态生成物理执行计划存在调优人力成本高、资源利用率低等问题。
基于 Pipeline Region 的统一调度
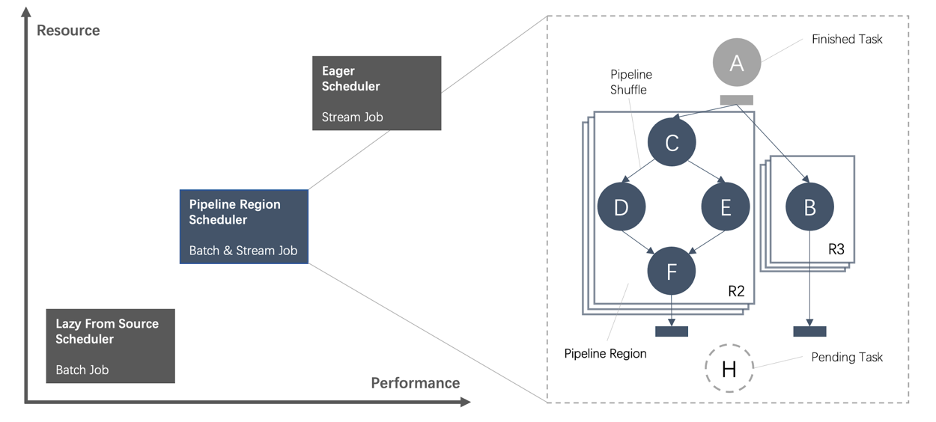
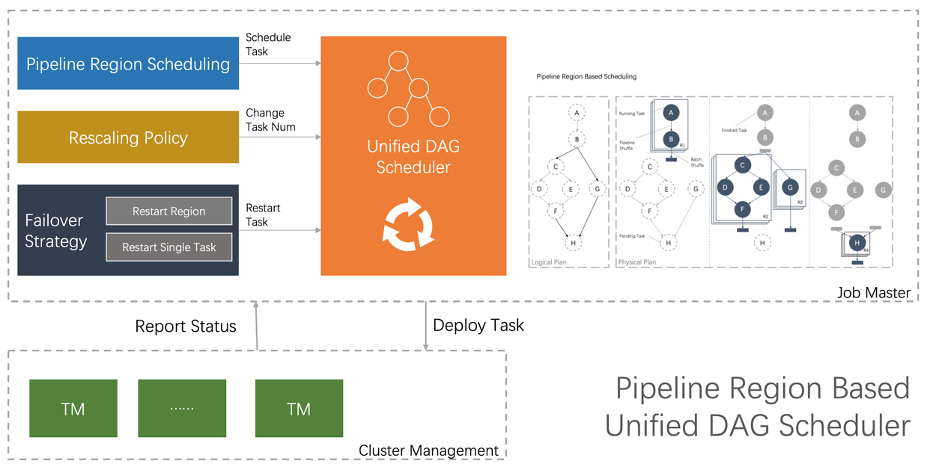

自适应调度
配置人力成本高。对于批作业来说,虽然理论上可以根据统计信息推断出物理执行计划中每个阶段的并发度,但是由于存在大量的 UDF 或者统计信息的缺失等问题,导致静态决策结果可能会出现严重不准确的情况;为了保障业务作业的 SLA,在大促期间,业务的同学需要根据大促的流量估计,手动调整高优批作业的并发度,由于业务变化快,一旦业务逻辑发生变化,又要不断的重复这个过程。整个调优过程都需要业务的同学手动操作,人力成本比较高,即便这样也可能会出现误判的情况导致无法满足用户 SLA; 资源利用率低。由于人工配置并发度成本比较高,所以不可能对所有的作业都手动配置并发度。对于中低优先级的作业,业务同学会选取一些默认值作为并发度,但是在大多数情况下这些默认值都偏大,造成资源的浪费;而且虽然高优先级的作业可以进行手工并发配置,由于配置方式比较繁琐,所以大促过后,虽然流量已经下降但是业务方仍然会使用大促期间的配置,也造成大量的资源浪费现象; 稳定性差。资源浪费的情况最终导致资源的超额申请现象。目前大多数批作业都是采取和流作业集群混跑的方式,具体来说申请的资源都是非保障资源,一旦资源紧张或者出现机器热点,这些非保障资源都是优先被调整的对象。
五、流批一体的 Shuffle 架构
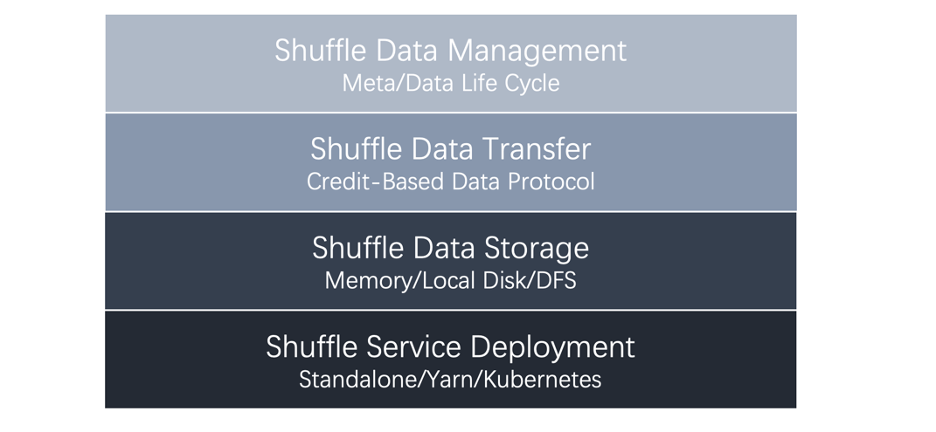
流批 Shuffle 之间的差异
Shuffle 数据的生命周期。流作业的 Shuffle 数据和 Task 的生命周期基本是一致的;而批作业的 Shuffle 数据和 Task 生命周期是解耦的; Shuffle 数据的存储介质。因为流作业的 Shuffle 数据生命周期比较短,所以可以把流作业的 Shuffle 数据存储在内存中;而批作业的 Shuffle 数据生命周期有一定的不确定性,所以需要把批作业的 Shuffle 数据存储在磁盘中; Shuffle 部署方式[7]。把 Shuffle 服务和计算节点部署在一起,对流作业来说这种部署方式是有优势的,因为这样会减少不必要网络开销,从而减少 Latency。但对于批作业来说,这种部署方式在资源利用率、性能、稳定性上都存在一定的问题。[8]
流批 Shuffle 之间的共性
数据的 Meta 管理。所谓 Shuffle Meta 是指逻辑数据划分到数据物理位置的映射。不管是流还是批的场景,在正常情况下都需要从 Meta 中找出自己的读取或者写入数据的物理位置;在异常情况下,为了减少容错代价,通常也会对 Shuffle Meta 数据进行持久化; 数据传输。从逻辑上讲,流作业和批作业的 Shuffle 都是为了对数据进行重新划分(re-partition/re-distribution)。在分布式系统中,对数据的重新划分都涉及到跨线程、进程、机器的数据传输。
流批一体的 Shuffle 架构
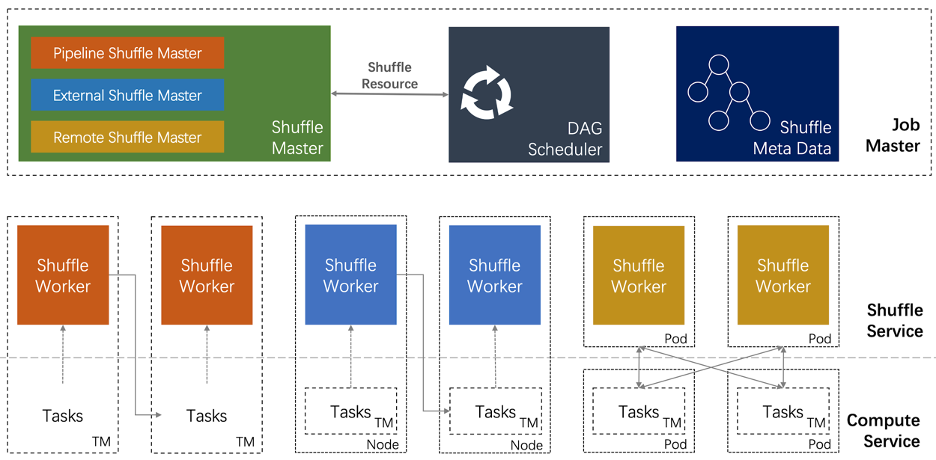
Shuffle Master 资源申请和资源释放。也就是说插件需要通知框架 How to request/release resource。而由 Flink 来决定 When to call it; Shuffle Writer 上游的算子利用 Writer 把数据写入 Shuffle Service——Streaming Shuffle 会把数据写入内存;External/Remote Batch Shuffle 可以把数据写入到外部存储中; Shuffle Reader 下游的算子可以通过 Reader 读取 Shuffle 数据;
六、流批一体的容错策略
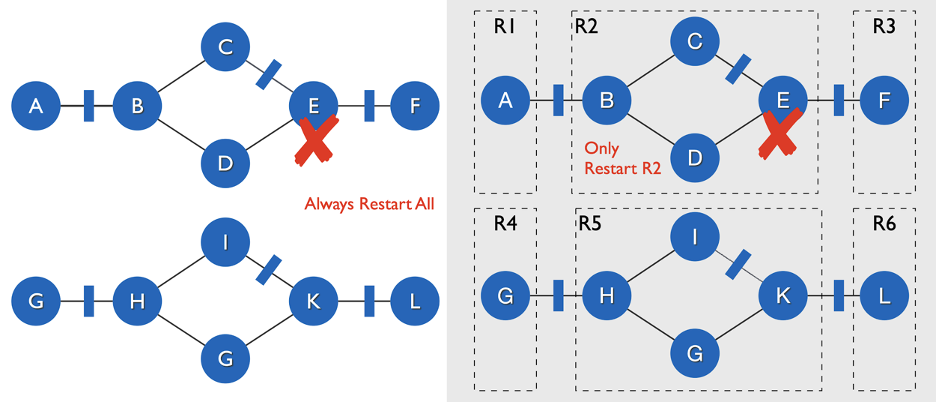
Pipeline Region Failover
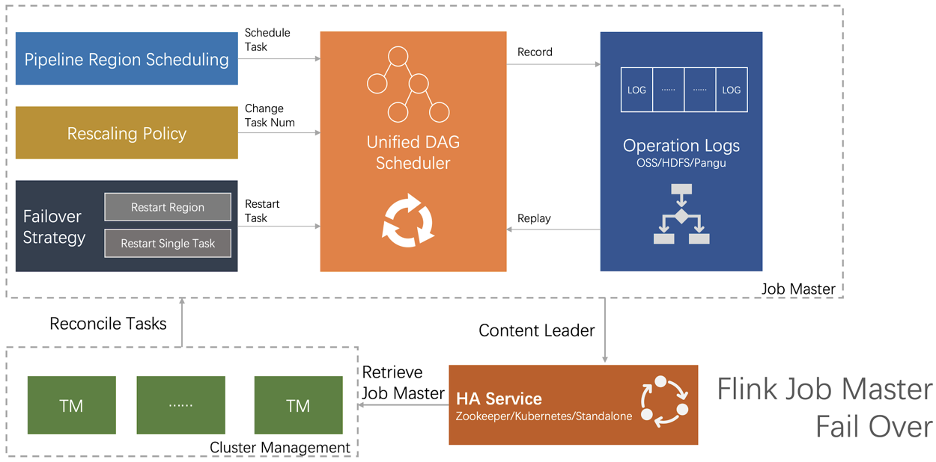
JM Failover
七、未来展望
 戳我,查看更多技术干货!
戳我,查看更多技术干货!评论