
Flink 原理 | 深入解析 Flink 细粒度资源管理
摘要:本文整理自阿里巴巴高级开发工程师郭旸泽 (天凌) 在 Flink Forward Asia 2021 核心技术专场的演讲。主要内容包括:
细粒度资源管理与适用场景 Flink 资源调度框架 基于 SlotSharinGroup 的资源配置接口 动态资源切割机制 资源申请策略 总结与未来展望
一、细粒度资源管理与适用场景


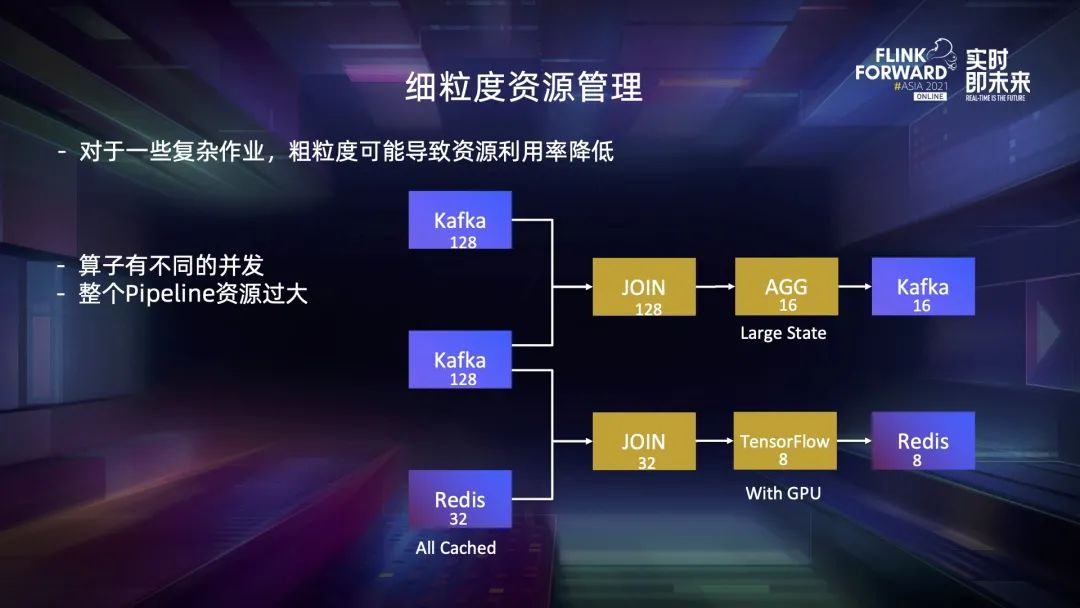
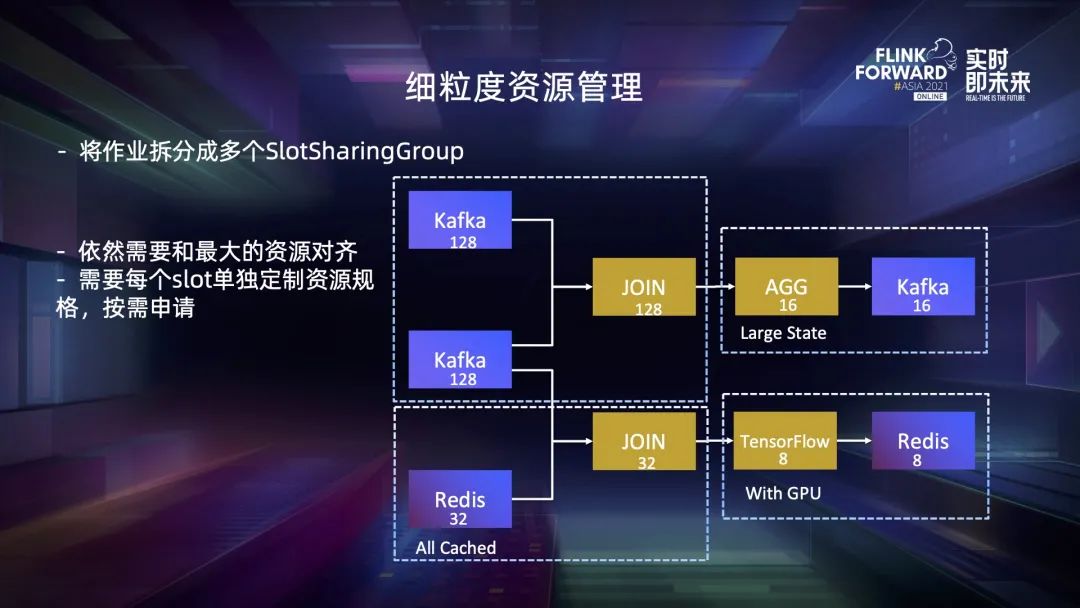

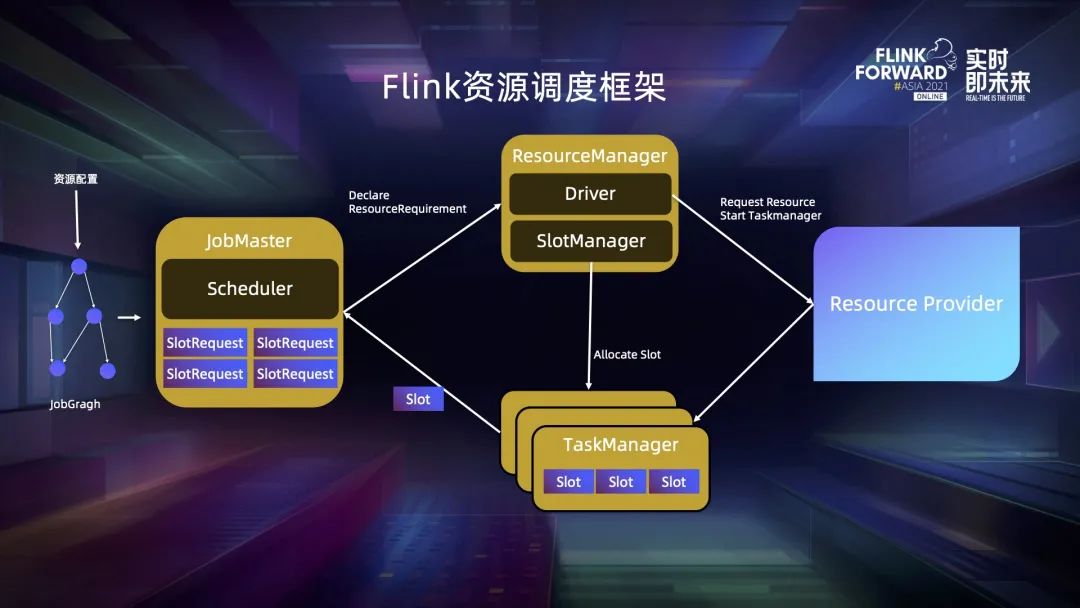
二、Flink 资源调度框架
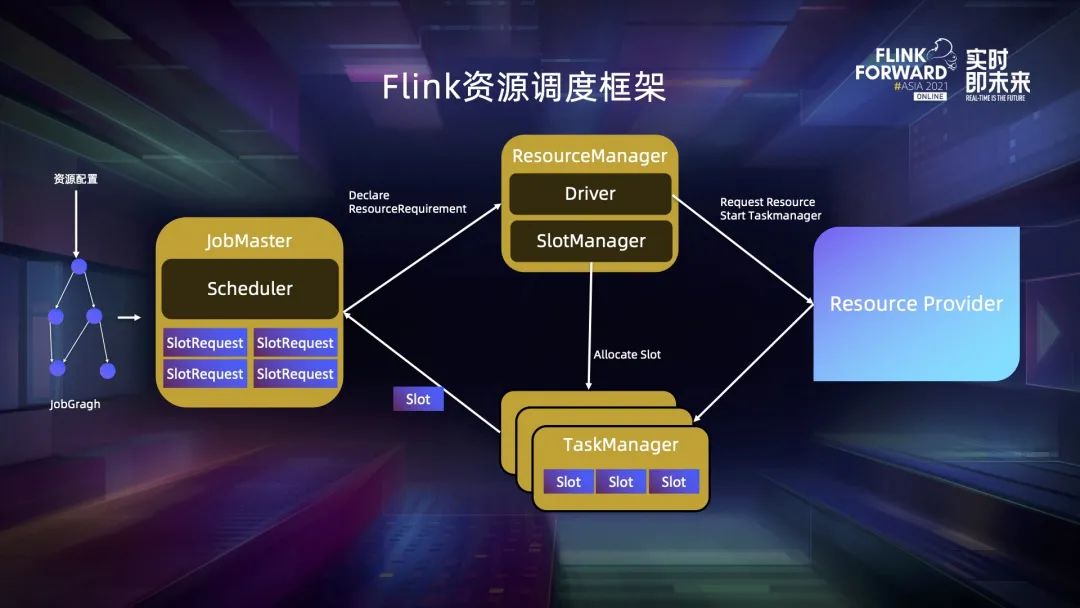
三、基于 SlotSharingGroup 的
资源配置接口



第一,使用户的配置更灵活。我们将配置粒度的选择权交给用户,既可以配置算子的资源,也可以配置 task 资源,甚至配置子图的资源,只需要将子图放到一个 SSG 里然后配置它的资源即可。
第二,可以较为简单地支持粗细粒度混合配置。所有配置的粒度都是 slot,不用担心同一个 slot 中既包含粗粒度又包含细粒度的 task。对于粗粒度的 slot,可以简单地按照 TM 默认的规格计算它的资源大小,这个特性也使得细粒度资源管理的分配逻辑可以兼容粗粒度调度的,我们可以把粗粒度看作是细粒度的一种特例。
第三,它使得用户可以利用不同算子之间的削峰填谷效应,有效减少偏差产生的影响。

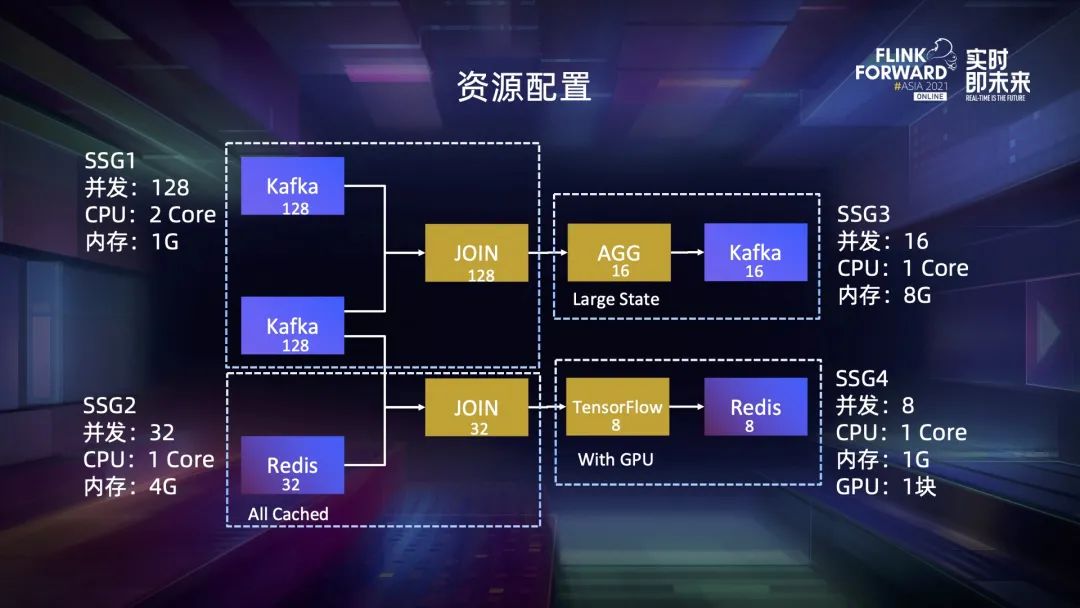
四、动态资源切割机制
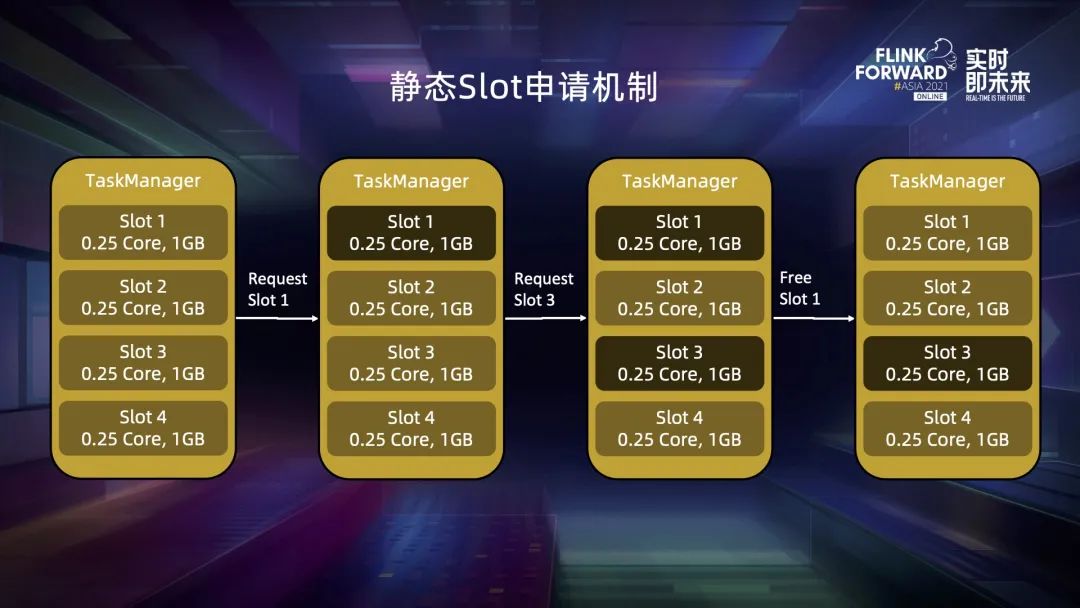
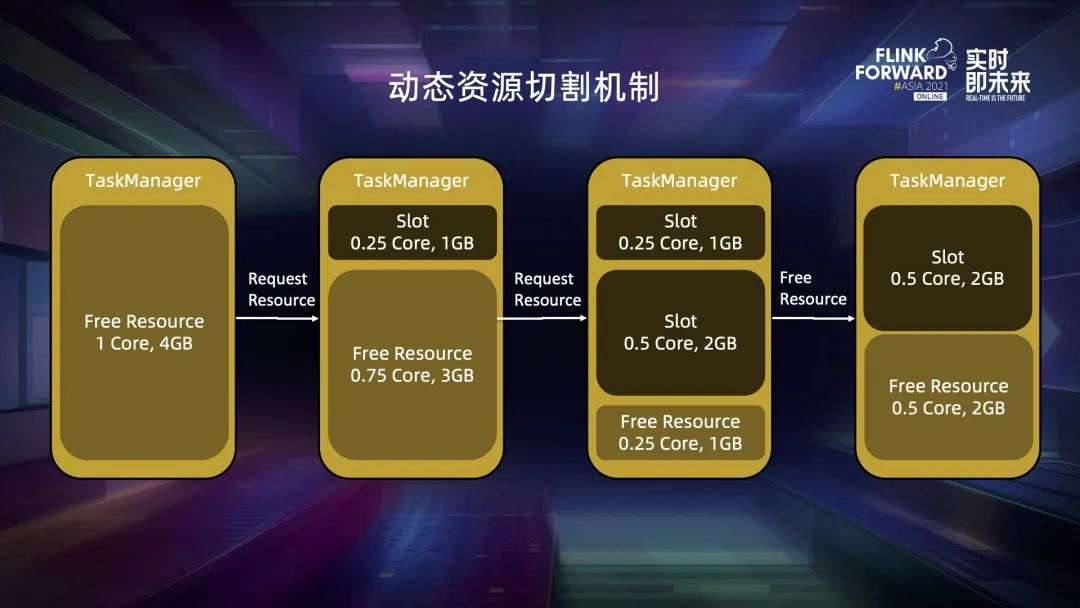
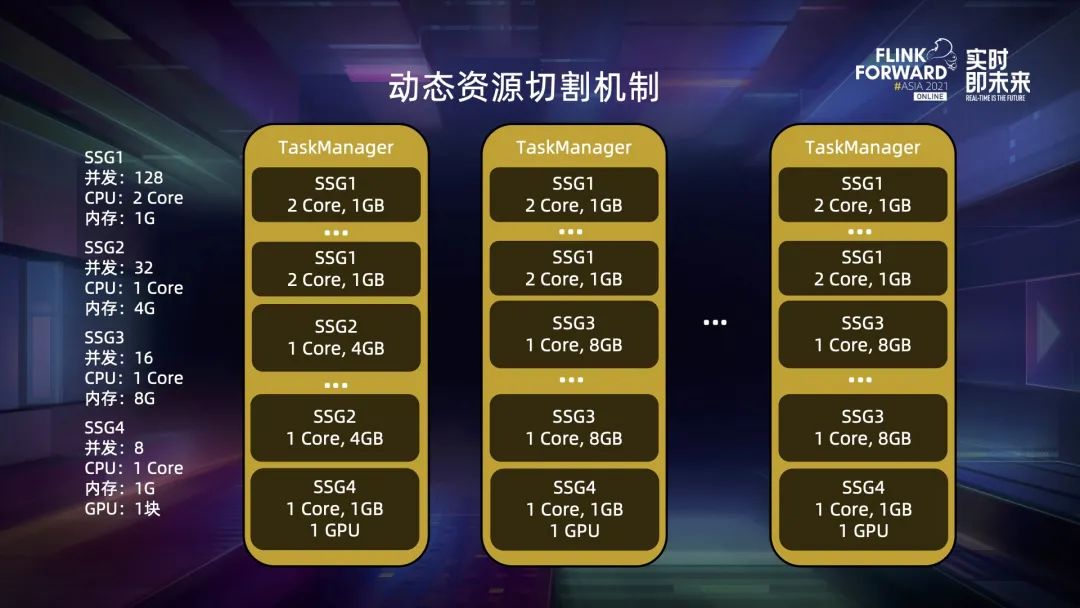
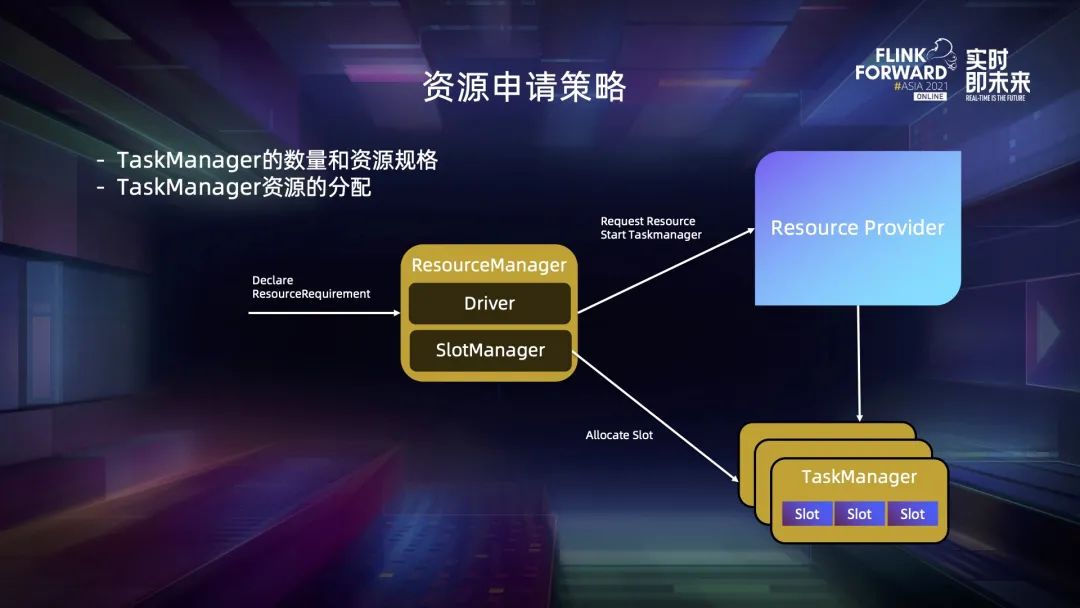
五、资源申请策略


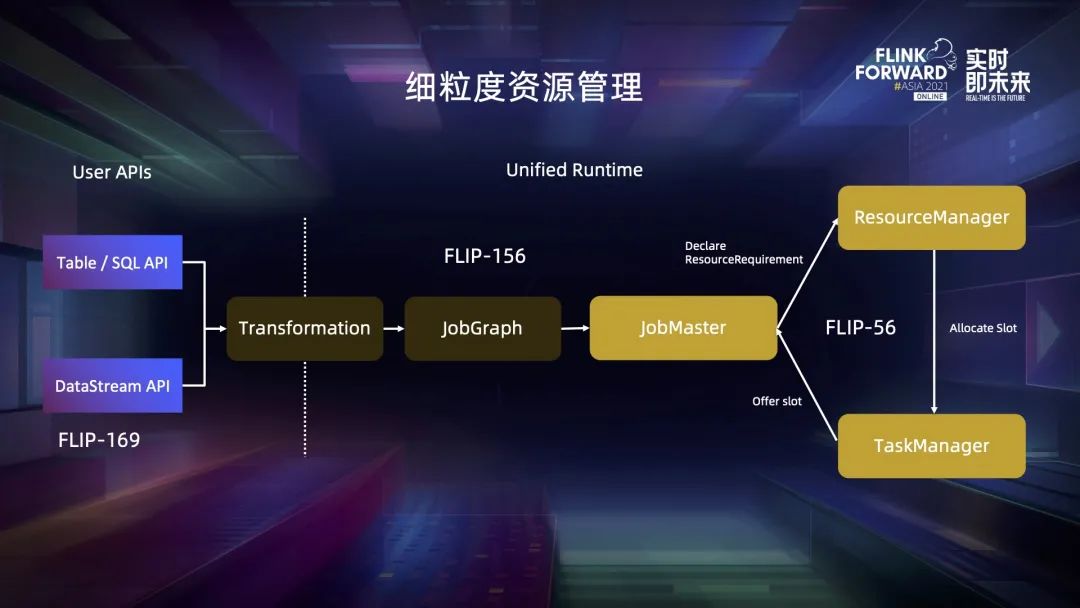
六、总结与未来展望

未来,我们的发展方向主要是以下几个方面:
第一,定制更多的资源管理策略来满足不同场景,比如 session 和 OLAP 等; 第二,目前我们是把扩展资源看作一个 TM 级别的资源,TM 上的每个 slot 都可以看到它的信息,之后我们会对它的 scope 进行进一步限制; 第三,目前细粒度资源管理可以支持粗细粒度混合配置,但是存在一些资源效率上的问题,比如粗粒度的 slot 请求可以被任意大小的 slot 满足,未来我们会进一步优化匹配逻辑,更好地支持混合配置; 第四,我们会考虑适配社区新提出的 Reactive Mode; 最后,对 WebUI 进行优化,能够展示 slot 的切分信息等。
往期精选




 戳我,查看原文视频&演讲PDF~
戳我,查看原文视频&演讲PDF~
评论