
最快ViT | FaceBook提出LeViT,0.077ms的单图处理速度却拥有ResNet50的精度(文末附论文与源码)

吸取CNN优点!LeViT:快速推理的视觉Transformer,在速度/准确性的权衡方面LeViT明显优于现有的CNN和视觉Transformer,比如ViT、DeiT等,而且top-1精度为80%的情况下LeViT比CPU上的EfficientNet快3.3倍。
作者单位:Facebook
1 简介
本文的工作利用了基于注意力体系结构中的最新发现,该体系结构在高度并行处理硬件上具有竞争力。作者从卷积神经网络的大量文献中重新评估了原理,以将其应用于Transformer,尤其是分辨率降低的激活图。同时作者还介绍了Attention bias,一种将位置信息集成到视觉Transformer中的新方法。
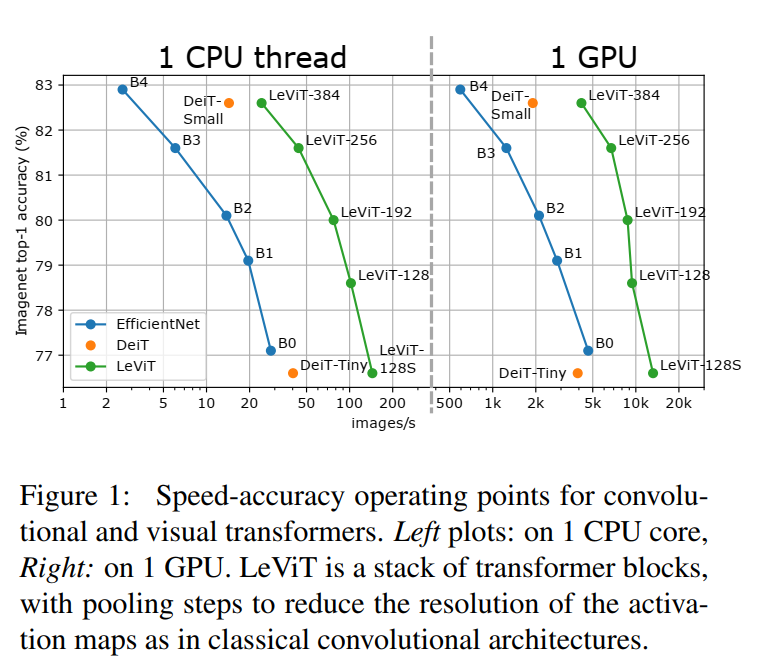
最终作者提出了LeVIT:一种用于快速推理的混合神经网络。考虑在不同的硬件平台上采用不同的效率衡量标准,以最好地反映各种应用场景。作者通过广泛的实验表明该方法适用于大多数体系结构。总体而言,在速度/准确性的权衡方面,LeViT明显优于现有的卷积网络和视觉Transformer。例如,在ImageNet Top-1精度为80%的情况下,LeViT比CPU上的EfficientNet快3.3倍。
相同计算复杂度的情况下Transformer为什么快?
大多数硬件加速器(gpu,TPUs)被优化以用来执行大型矩阵乘法。在Transformer中,注意力机制和MLP块主要依靠这些操作。相比之下,卷积需要复杂的数据访问模式,因此它们的操作通常受io约束。这些考虑对于我们探索速度/精度的权衡是很重要的。
本文主要贡献:
采用注意力机制作为下采样机制的multi-stage transformer 结构;
一种计算效率高的patch descriptor,可以减少第一层特征的数量;
使用Translation-invariant attention bias取代ViT中的位置嵌入;
为了提高给定计算时间的网络容量,作者重新设计了Attention-MLP Block。
2 LeViT的设计
2.1 LeViT设计原则
LeViT以ViT的架构和DeiT的训练方法为基础,合并了对卷积架构有用的组件。第1步是获得Compatible Representation。如果不考虑classification embedding的作用,ViT就是一个处理激活映射的Layer的堆叠。
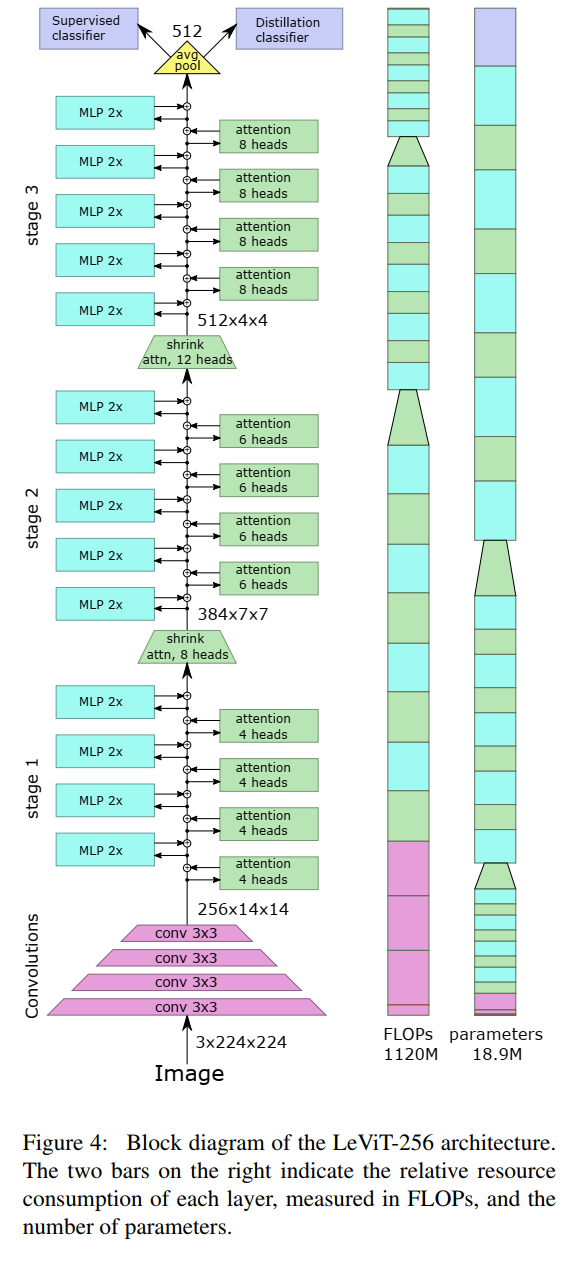
实际上,中间“Token”嵌入可以看作是FCN体系结构中传统的C×H×W激活映射(BCHW格式)。因此,适用于激活映射(池、卷积)的操作可以应用于DeiT的中间表征。
LeViT优化了计算体系结构,不一定是为了最小化参数的数量。ResNet系列比VGG更高效的设计原则之一是在其前2个阶段使用相对较小的计算预算应用strong resolution reductions。当激活映射到达ResNet的第3阶段时,其分辨率已经缩小到足以将卷积应用于小的激活映射,从而降低了计算成本。
2.2 LeViT组件
1、Patch embedding
初步分析表明,在transformer组的输入上应用一个小卷积可以提高精度。因此在LeViT中作者选择对输入应用4层3×3卷积(stride2)来降低分辨率。channel的数量是C=3,32,64,128,256。
以上操作减少了对transformer下层的激活映射的输入,同时不丢失重要信息。LeViT-256的patch extractor用184 MFLOPs将图像形状(3,224,224)转换为(256,14,14)。作为比较,ResNet-18的前10层使用1042 MFLOPs执行相同的dimensionality reduction。
为什么在transformer组的输入上应用一个小卷积可以提高精度?
2、No classification token
为了使用BCHW张量形式,LeViT删除了classification token。类似于卷积网络,在最后一个激活映射上使用GAP来代替,这将产生一个用于分类器的embedding。在训练中进行蒸馏,作者分别训练分类和蒸馏的Head。在测试时,平均2个Head的输出。在实践中,LeViT可以使用BNC或BCHW张量格式。
3、Normalization layers and activations
ViT架构中的FC层相当于1x1卷积。ViT在每个注意点和MLP单元之前使用层归一化。对于LeViT,每次卷积之后都要进行BN操作。然后与residual connection连接起来的每个BN权重参数初始化为零。BN可以与之前的卷积合并来进行推理,这比层归一化有运行优势(例如,在EfficientNet B0上,这种融合将GPU的推理速度提高了2倍)。而DeiT使用GELU函数,而LeViT的非线性激活都是Hardswish。
class Linear_BN(torch.nn.Sequential):
def __init__(self, a, b, bn_weight_init=1, resolution=-100000):
super().__init__()
self.add_module('c', torch.nn.Linear(a, b, bias=False))
bn = torch.nn.BatchNorm1d(b)
torch.nn.init.constant_(bn.weight, bn_weight_init)
torch.nn.init.constant_(bn.bias, 0)
self.add_module('bn', bn)
global FLOPS_COUNTER
output_points = resolution**2
FLOPS_COUNTER += a * b * output_points
@torch.no_grad()
def fuse(self):
l, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = l.weight * w[:, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps)**0.5
m = torch.nn.Linear(w.size(1), w.size(0))
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
def forward(self, x):
l, bn = self._modules.values()
x = l(x)
return bn(x.flatten(0, 1)).reshape_as(x)
4、Multi-resolution pyramid
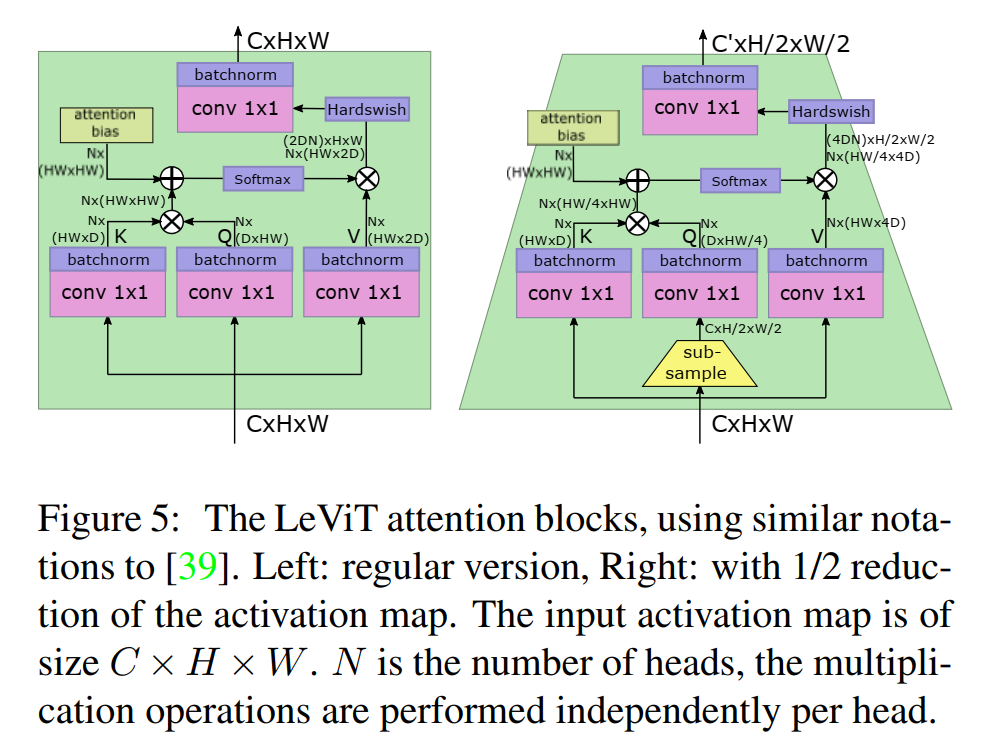
LeViT在transformer架构中集成了ResNet stage。在各个stage中,该体系结构类似于一个visual transformer:一个带有交替MLP和激活块的残差模块。下面是注意块的修改。
class Attention(torch.nn.Module):
def __init__(self, dim, key_dim, num_heads=8,
attn_ratio=4,
activation=None,
resolution=14):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.qkv = Linear_BN(dim, h, resolution=resolution)
self.proj = torch.nn.Sequential(activation(), Linear_BN(
self.dh, dim, bn_weight_init=0, resolution=resolution))
points = list(itertools.product(range(resolution), range(resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
global FLOPS_COUNTER
#queries * keys
FLOPS_COUNTER += num_heads * (resolution**4) * key_dim
# softmax
FLOPS_COUNTER += num_heads * (resolution**4)
#attention * v
FLOPS_COUNTER += num_heads * self.d * (resolution**4)
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, N, C = x.shape
qkv = self.qkv(x)
q, k, v = qkv.view(B, N, self.num_heads, -
1).split([self.key_dim, self.key_dim, self.d], dim=3)
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn = (
(q @ k.transpose(-2, -1)) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
x = self.proj(x)
return x
5、Downsampling
在LeViT stage之间,一个缩小的注意块减少了激活映射的大小:在Q转换之前应用一个subsampling,然后传播到soft activation的输出。这将一个大小为的输入张量映射到一个大小为的输出张量。由于尺度的变化这个注意块的使用没有残差连接。同时为了防止信息丢失,这里将注意力头的数量设为。
class Subsample(torch.nn.Module):
def __init__(self, stride, resolution):
super().__init__()
self.stride = stride
self.resolution = resolution
def forward(self, x):
B, N, C = x.shape
x = x.view(B, self.resolution, self.resolution, C)[
:, ::self.stride, ::self.stride].reshape(B, -1, C)
return x
6、Attention bias instead of a positional embedding
在transformer架构中的位置嵌入是一个位置依赖可训练的向量,在将token嵌入输入到transformer块之前,将其添加到token嵌入。如果没有它,转换器输出将独立于输入标记的排列。位置嵌入的Ablations会导致分类精度的急剧下降。
然而,位置嵌入只包含在注意块序列的输入上。因此,由于位置编码对higher layer也很重要,所以它很可能仍然处于中间表示中。
因此,LeViT在每个注意块中提供位置信息,并在注意机制中明确地注入相对位置信息:只是在注意力图中添加了注意偏向。对于每个head ,每2个像素和之间的标量值计算方式为:
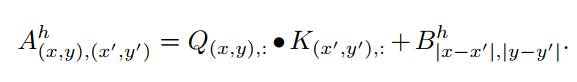
第一项是经典的注意力。第二个是translation-invariant attention bias。每个Head有H×W参数对应不同的像素偏移量。对称差异和鼓励用 flip invariance进行训练。
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
7、Smaller keys
由于translation-invariant attention bias偏置项减少了key对位置信息编码的压力,因此LeViT减少了key矩阵相对于V矩阵的大小。如果key大小为, V则有2D通道。key的大小可以减少计算key product 所需的时间。
对于没有残差连接的下采样层,将V的维数设置为4D,以防止信息丢失。
8、Attention activation
在使用常规线性投影组合不同Heads的输出之前,对product 应用Hardswish激活。这类似于ResNet bottleneck residual block,V是一个1×1卷积的输出,对应一个spatial卷积,projection是另一个1×1卷积。
9、Reducing the MLP blocks
在ViT中,MLP residual块是一个线性层,它将嵌入维数增加了4倍,然后用一个非线性将其减小到原来的嵌入维数。但是对于视觉架构,MLP通常在运行时间和参数方面比注意Block更昂贵。
对于LeViT, MLP是1x1卷积,然后是通常的BN。为了减少计算开销,将卷积的展开因子从4降低到2。一个设计目标是注意力和MLP块消耗大约相同数量的FLOPs。
2.3 LeViT家族
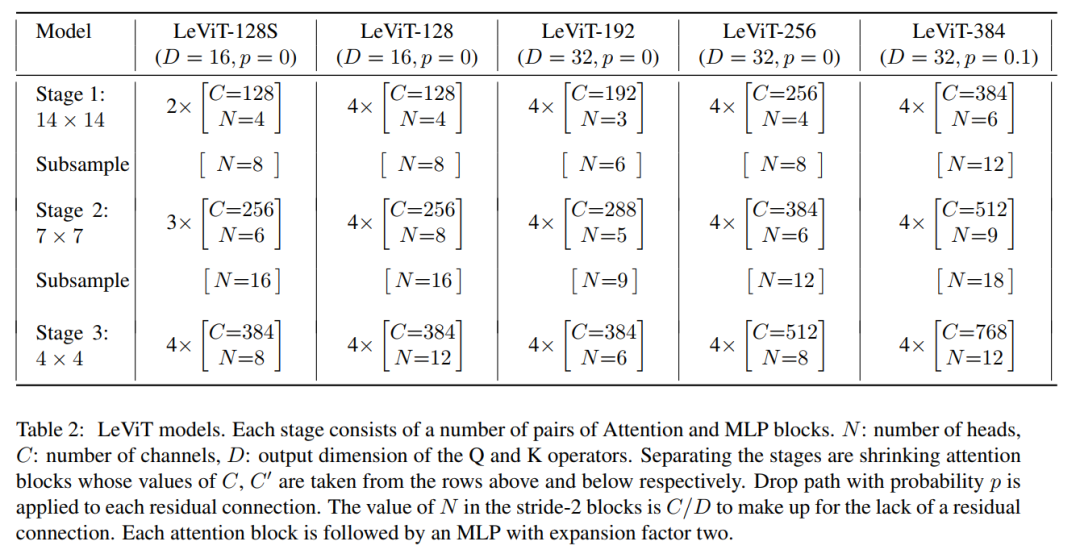
3 实验
3.1 速度对比
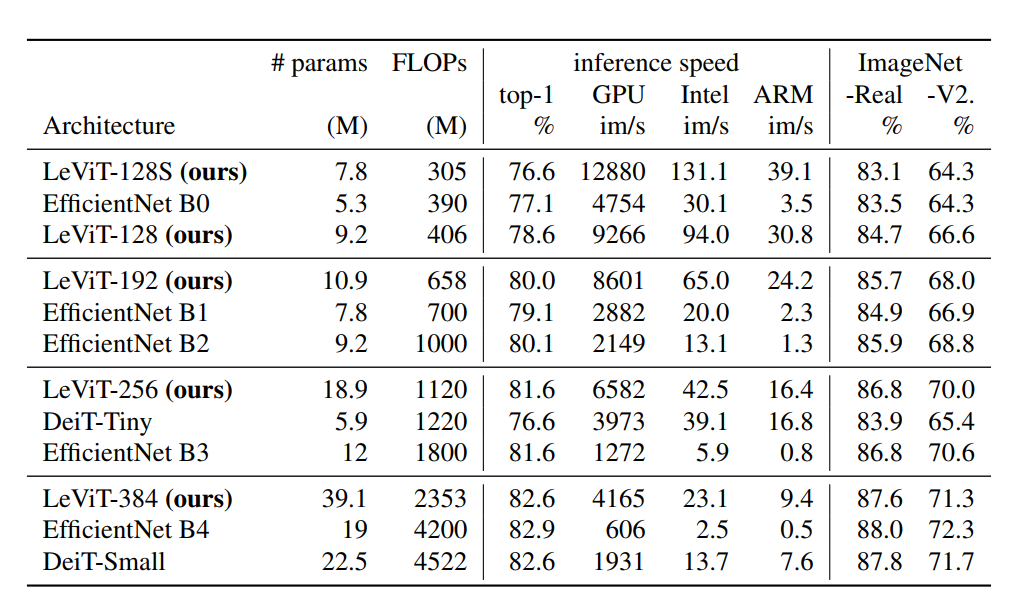
ResNet50的精度,但是是起飞的速度。
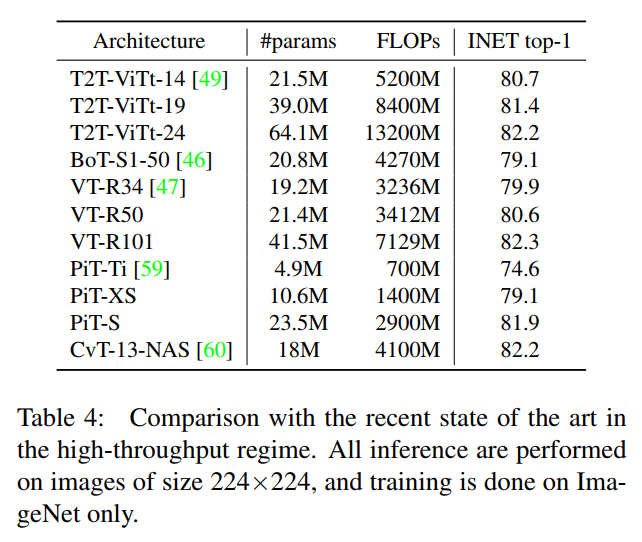
3.2 SOTA对比
4 参考
[1].LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
[2].https://github.com/facebookresearch/LeViT
本文论文原文获取方式,扫描下方二维码
回复【LeViT】即可获取论文与源码
长按扫描下方二维码加入交流群
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【AI人工智能初学者】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!!!
点“在看”给我一朵小黄花呗![]()