
迟到的 HRViT | Facebook提出多尺度高分辨率ViT,这才是原汁原味的HRNet思想

ViT因其在计算机视觉任务中的优越性能而备受关注。为了解决单尺度低分辨率表示的局限性,之前的工作将ViT应用于使用分层结构生成金字塔特征的高分辨率密集预测任务。然而,由于ViT具有分级连续拓扑,其多尺度表示学习的研究尚不充分。
为了增强ViT学习语义丰富、空间精确的多尺度表示的能力,在本文中提出了一种将高分辨率多分支架构与Vision Transformer有效集成的方法,称为HRViT,该方法将密集预测任务推到了一个新的水平。
作者探索了异构分支设计,减少了线性层的冗余,并增加了模型的非线性,以平衡模型性能和硬件效率。本文所提出的HRViT在ADE20K上实现了50.20% mIoU,在Cityscapes上实现了83.16% mIoU,超过了最先进的MiT和CSWin,平均提高了1.78 mIoU,减少了28%的参数和21%的FLOPs。
1简介
密集预测视觉任务,如语义分割、目标检测,是现代智能计算平台(如AR/VR设备)的关键技术。卷积神经网络的发展非常迅速,在密集预测任务方面有了显著的改进。除了传统的CNN外,近期的ViTs也已经吸引了研究者广泛的兴趣,并在视觉任务中显示出竞争性的性能。
得益于self-attention,ViT特征信息交互距离较远。然而,ViT产生单一尺度和低分辨率的表示,这与密集的预测任务不兼容,因为这些任务需要高位置灵敏度和细粒度的图像细节。
近年来,为了适应密集的预测任务,人们提出了各种ViT Backbone。之前的ViT Backbone提出了各种有效的全局/局部自注意力来提取层次特征。
一种多尺度ViT(MViT)已经被提出,以学习一个层次结构,逐步扩大通道信息容量,同时降低空间分辨率。但是,它们仍然遵循类似于分类的网络拓扑结构,采用顺序或系列架构。考虑到复杂性,MViT逐渐对特征映射进行取样,以提取更高级别的低分辨率(LR)表示,并直接将每个阶段的输出提供给下游框架。这种顺序结构缺乏足够的跨尺度相互作用,因此不能生成高质量的高分辨率(HR)表示。
HRNet是为了加强跨分辨率的交互而提出的,它采用了一个多分支架构,在整个网络中维护所有的分辨率。并行提取多分辨率特征,并进行多次融合,生成具有丰富语义信息的高质量HR表示。这种设计理念在各种密集预测任务中取得了巨大的成功。
然而,它的表达能力受到较小的感受野和级联卷积运算的强归纳偏差的限制。随后,提出了一种精简的Lite-HRNet,该Lite-HRNet具有高效的Shuffle-block和通道加权算子。
HR-NAS在残块中插入一个Light-weight Transformer path提取全局信息,并应用神经结构搜索去除channel / head冗余。然而,这些改进的HRNet设计仍然主要基于卷积块构建,他们的微型模型的性能仍然远远落后于ViT的同类模型的SoTA结果。
将HRNet的成功移植到ViT设计并非易事。考虑到多分支的高度复杂性HR架构和Self-Attention操作,简单地用Transformer Block替换HRNet中的所有残差快,将遇到严重的可伸缩性问题。如果没有仔细的Architecture-block协同优化,继承的强大的可表示性将被高昂的硬件成本所淹没。
为了增强ViT的可表征性,以生成语义丰富和位置精确的特征,在本工作中提出HRViT,一种专为高分辨率密集预测任务优化的高效多尺度高分辨率视觉Transformer Backbone。HRViT的目标是促进Vision Transformer的有效多尺度表示学习。
HRViT不同于以往的ViT的几个方面是:
通过并行提取多尺度特征以及跨分辨率融合,提高了ViT的多尺度可表征性;
增强的局部自注意力,消除了冗余的key和value,提高了效率,并通过额外的卷积路径、额外的非线性和辅助快捷键增强了特征的多样性,增强了表达能力;
采用混合尺度卷积前馈网络加强多尺度特征提取;
HR卷积stem和高效的patch embedding layer保持更多的低层次细粒度特征,降低了硬件成本。
同时,与HRNet-family不同的是,HRViT采用了独特的异构分支设计来平衡效率和性能,它不是简单的改进的HRNet,而是主要由自注意力算子构建的纯ViT拓扑结构。
主要贡献如下:
深入研究了ViT中的多尺度表示学习,并将高分辨率架构与Vision Transformer相结合,实现高性能密集预测视觉任务; 为了实现可扩展的HR-ViT集成,并实现更好的性能和效率权衡,利用了Transformer Block中的冗余,并通过异构分支设计对HRViT的关键部件进行联合优化; HRViT再语义分割任务的ADE20K达到50.20% mIoU,在Cityscapes上达到83.16% mIoU,超过了最先进的(SoTA)MiT和CSWin,同时参数减少28%,FLOPs降低21%。
2本文方法
与复杂的注意力算子创新的激增相比,ViT的多尺度表示学习的探索要少得多,这远远落后于它们的CNN同行最近的进展。新的拓扑设计创造了另一个维度,以更强的视觉表现力释放vit的潜力。有待解决的一个重要问题是HRNet的成功能否有效地迁移到ViT Backbone以巩固其在高分辨率密集预测任务中的领先地位。
2.1 Architecture overview
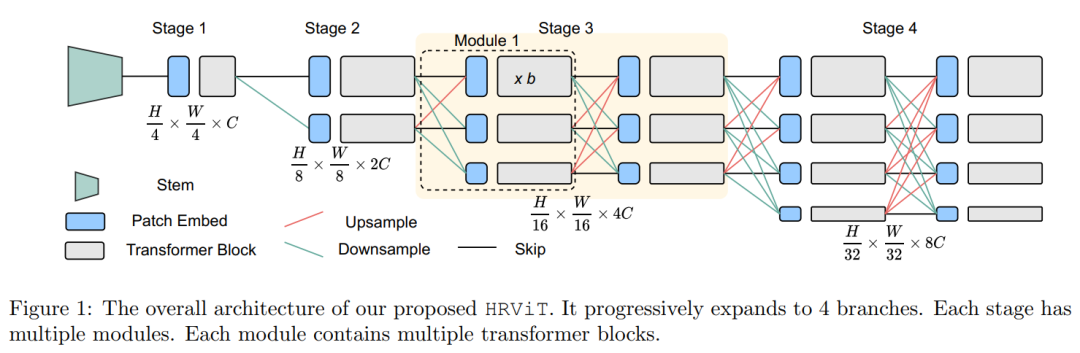
在图1中说明了HRViT的体系结构。它由卷积主干组成,在提取低层次特征的同时降低空间维数。然后构造了4个渐进式Transformer Stage,其中第n阶段包含了n个并行的多尺度Transformer branches。每个阶段可以有一个或多个模块。每个模块从一个轻量级的密集融合层开始,实现跨分辨率交互和一个高效的块嵌入局部特征提取,然后是重复增强的局部自注意力块(HRViTAttn)和混合尺度卷积前馈网络(MixCFN)。
不同于顺序的ViT主干逐步降低空间维度以生成金字塔特征,在整个网络中保持HR特征,通过交叉分辨率融合加强HR表示的质量。
2.2 高效的HR-ViT集成与异构分支设计
作者设计了一种异构多分支体系结构,用于硬件高效的多尺度高分辨率ViT。一个简单的选择是用self-attention代替HRNet中的所有卷积。然而,考虑到多分支HRNet和self-attention操作的高度复杂性,这种暴力组合将很快导致内存占用、参数大小和计算成本的激增。
如果想要利用HR架构的多尺度可表示性和Transformer的建模能力,必须克服巨大的复杂性,使其比两者更具有硬件效率。因此,架构和块协同设计对于可伸缩和高效的HR-ViT集成至关重要。
1、异构分支配置
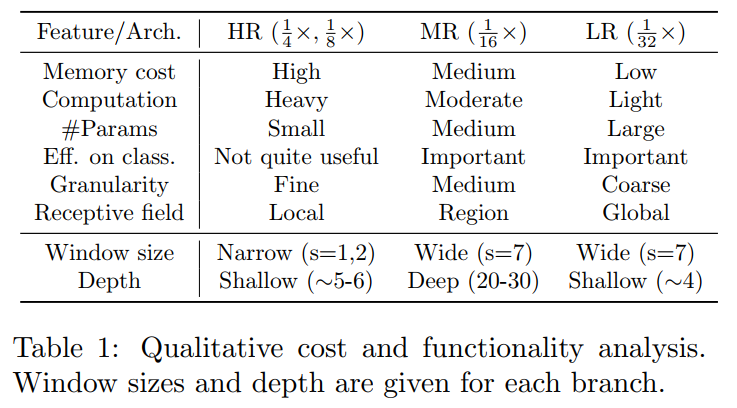
第一个问题是:如何配置每个可伸缩的分支HRViT设计?
简单地在每个模块上用相同的local self-attention window size分配相同数量的块,将会使其成本非常高。在表1中详细分析了每个分支的功能和成本,并在此基础上总结了一个简单的设计启发式。
给出HRViTAttn的参数计数和MixCFN块在第i个分支(i=1,2,3,4):
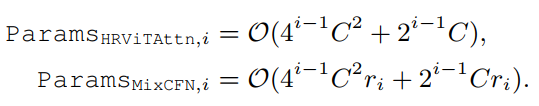
浮点运算(FLOPs)的数量是:
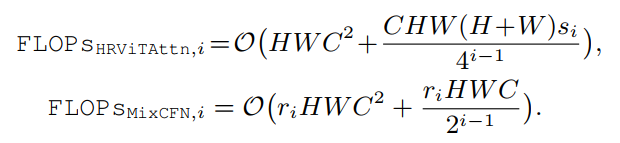
浅层语义:第1个和第2个HR分支(i=1,2)几乎不能生成有用的高级分类特征,但有很高的内存和计算成本。另一方面,它们是参数高效的,可以在分割任务中提供细粒度的细节标定。因此,使用一个小的self-attention window size s,并在2个HR path上使用最少数量的块。
中层语义:最重要的分支是具有中等分辨率(MR)的第3分支。鉴于其中等的硬件成本,可以在MR路径上使用一个大的self-attention window size深分支,以提供大的感受野和良好提取的高级特征的能力。
高层语义:最低分辨率(LR)分支包含了大多数参数,在提供高级特征作为粗分割图时非常有用。然而,它的小空间尺寸丢失了太多的图像细节。因此,只把几块大小较大的 window 放在上面在参数预算下改善高水平的特性质量。
2、Nearly-even Block Assignment
一旦确定了总分支深度,一个唯一的问题(在连续的ViT变体中不存在)就是如何将这些块分配给每个模块?
在HRViT中需要把20个Blocks分配给4个模块。为了最大程度地提高网络整体的平均深度,并帮助输入/梯度流通过深Transformer分支,作者倾向于使用几乎均匀的分区,例如6-6-6-2,而不是极端不平衡的分配,例如17-1-1-1。
2.3 高效HRViT组件设计
1、Augmented cross-shaped local self-attention
为了达到更高的效率和更高的性能,一个硬件高效的自注意力操作是必要的。HRViT采用一种有效的cross-shaped self-attention 作为baseline attention operator。
在此基础上,设计了augmented cross-shaped local self-attention HRViT-Attn。HRViT-Attn有以下优点:
细粒度注意:与全局下采样attention相比,HRViT-Attn具有保留详细信息的细粒度特征聚合; 近似全局视图:通过使用2个平行的正交局部注意力来收集全局信息; 可伸缩复杂度:window的一维是固定的,避免了图像尺寸的二次复杂度。
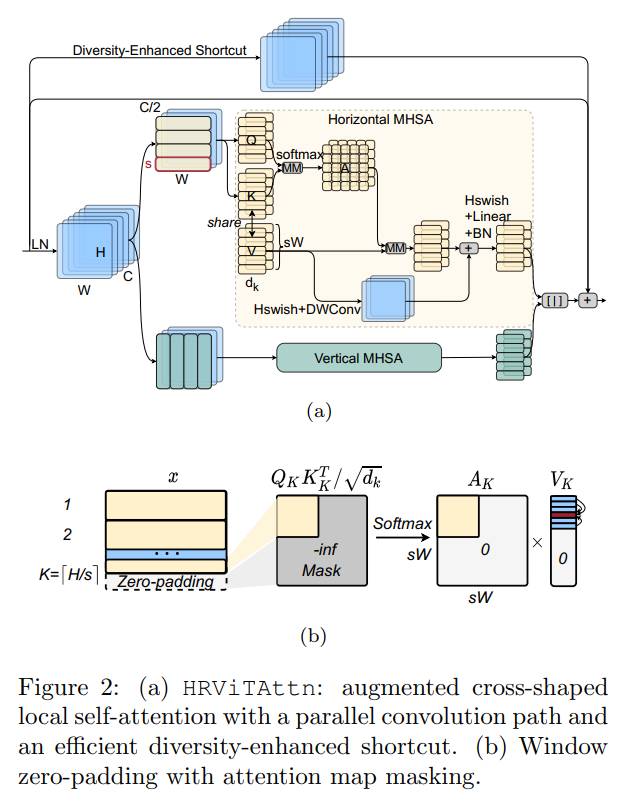
为了平衡性能和硬件效率,引入了扩展版本,表示为HRViT-Attn,有几个关键的优化。在图2(a)中,遵循CSWin中的cross-shaped window partitioning方法,将输入分割为2个部分。被分割成不相交的水平窗口,而另一半被分割成垂直窗口。窗口设置为s×W或H×s。在每个窗口内,patch被分块成K个维的Head,然后应用local self-attention,
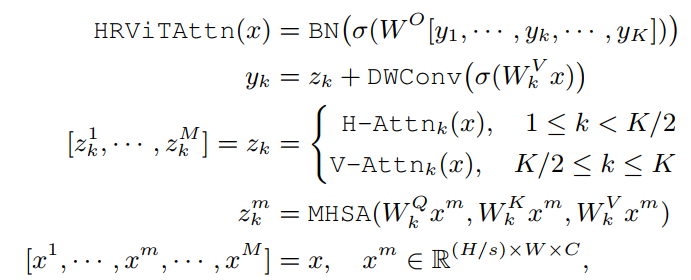
式中为生成第k个Head的query 、key 和value 张量的投影矩阵,为输出投影矩阵,σ为Hardswish激活函数。如果图像大小不是窗口大小的倍数,对输入x应用零填充,以允许一个完整的第k个窗口,如图2(b)所示。然后将Attention Map中的padding区域Mask为0,以避免语义不贯。
原有的QKV线性层在计算和参数上都非常昂贵。共享HRViT-Attn中key张量和value张量的线性投影,以节省计算和参数,如下所示:

此外,作者还引入了一个具有并行深度卷积的辅助路径来注入感应偏差以促进训练。与CSWin中的局部位置编码不同,HRViT的并行路径是非线性的,并应用于整个4-D特征图上,而不需要进行窗口划分。这条路径可以看作是一个反向残差模,与自注意力的线性投影层共享point-wise卷积。该共享路径可以有效地注入感应偏差,并在硬件开销较小的情况下加强局部特征聚合。
作为对上述key-value共享的性能补偿,作者引入了一个额外的Hardswish函数来改善非线性。同时还附加了一个BatchNorm(BN)层,该层被初始化为一个identity投影,以稳定分布获得更好的可训练性。
最近的研究表明,不同的Transformer layer往往具有非常相似的特性,其中Shortcut起着至关重要的作用。受augmented shortcut方式的启发,作者添加了一个通道式投影作为多样性增强shortcut方式(DES)。主要的区别是本文的Shortcut具有更高的非线性,并且不依赖于不友好的硬件傅里叶变换。
投影矩阵DES 近似为Kronecker分解,使参数代价最小,其中P最优设置为。然后将x折叠为,并将转换为以节省计算。进一步在B投影后插入Hardswish以增加非线性,

2、Mixed-scale Convolutional Feedforward Network
受MiT中MixFFN和HR-NAS中multibranch inverted residual blocks 的启发,作者通过在2个线性层之间插入2条多尺度深度卷积路径,设计了一种混合尺度卷积FFN(MixCFN)。
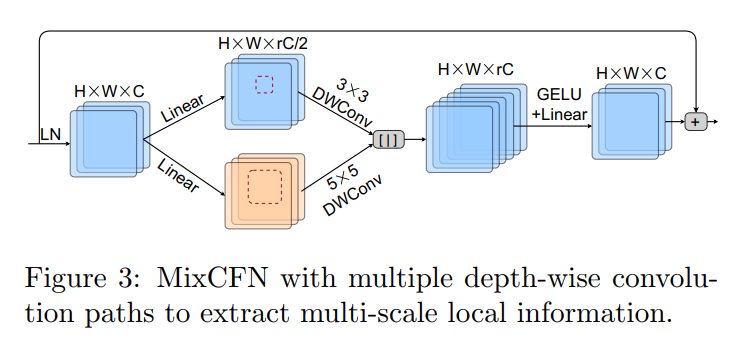
在LayerNorm之后,将通道以r的比例展开,然后将其分成2个分支。利用3×3和5×5深度卷积(DWConv)增强HRViT的多尺度局部信息提取。为了提高效率,作者利用通道冗余,将MixCFN扩展比r从4降低到2或3,但是,这么做在中型到大型模型上有边际性能损失。
3、Downsampling stem
在密集预测任务中,图像分辨率较高,例如1024×1024。Self-attention计算比较复杂,因为它们的复杂性是图像大小的平方。
为了解决处理大图像时的可伸缩性问题,作者在将输入输入到HRViT主体之前对输入进行4次采样。而没有在stem中使用attention操作,因为早期卷积比Self-attention更有效地提取低级特征。
另一方面,并没有像之前的ViTs那样简单地使用stride-4卷积,而是遵循HRNet中的设计,使用2个stride-2 convn-bn-relu块作为一个更强的下采样来提取c通道特征,并保留更多的信息。
4、Efficient patch embedding
在每个模块的transformer blocks之前在每个分支上放置一个patch embedding块(convert-layernorm)。它用于通道匹配和提取patch信息,增强了patch间的通信。与只有4个embedding层的顺序体系结构不同,作者发现在HR体系结构中,patch embedding层的硬件成本并不低,因为阶段n的每个模块都有n个embedding块。作者选择用一个blueprint卷积来简化它,即,point-wise CONV,然后是depth-wise CONV:
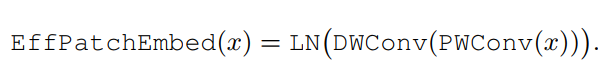
5、Cross-resolution fusion layer
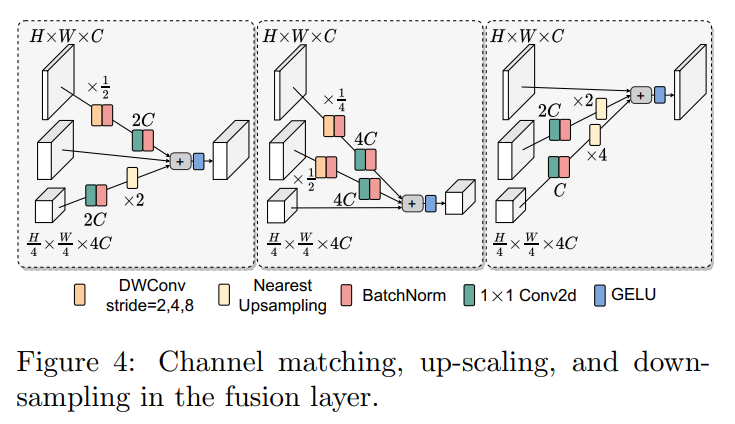
跨分辨率融合层是HRViT高质量学习的关键HR表示,如图4所示。为了增加更多的跨分辨率交互,作者借鉴了HRNet的思想,在每个模块的开始处插入重复的跨分辨率融合层。
为了帮助LR特征保持更多的图像细节和精确的位置信息,作者将其与下采样的HR特征合并。使用直接的下采样路径来最小化硬件开销,而不是使用基于渐进卷积的下采样路径来匹配张量形状。
在第i个输入和第j个输出(j>i)之间的下采样路径中,采用步长为的深度可分离卷积来缩小空间维数并匹配输出通道。DWConv中使用的kernel-size是来创建patch overlaps。这些HR路径将更多的图像信息注入LR路径,以减少信息的丢失,并加强反向传播过程中的梯度流,以方便LR Transformer block的训练。
另一方面,当最小化HR路径上的窗口大小和分支深度时,感受野通常被限制在HR块中。因此,将LR表示合并到HR路径中,以帮助它们获得具有更大感受野的高级别特征。
具体来说,在向上缩放路径(j>i)中,首先通过1×1卷积增加通道数量,并通过速率为的最近邻插值来向上缩放空间维数。当i=j时,直接将特征作为skip connection传递给输出。
注意,在HR-NAS中,密集融合被稀疏融合模块简化,其中只合并相邻的分辨率。在HRViT中不考虑这项技术,因为它节省了少量的硬件成本,但导致了显著的精度下降。
2.3 HRViT变体
不同的HRViT变体在网络深度和宽度上都有所不同。表2总结了3个变体的详细分支设计。
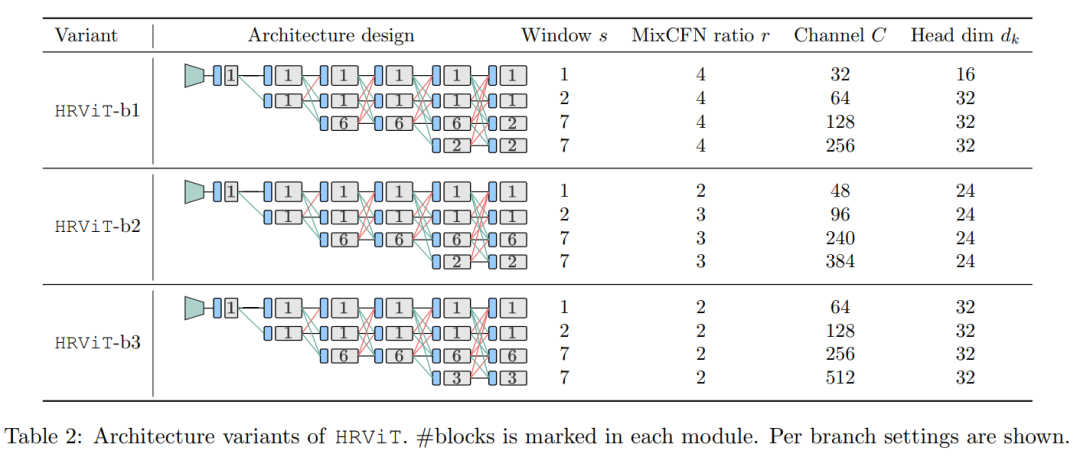
按照上述设计指导,HR分支设置1块,MR分支设置20-24块,LR分支设置4-6块。窗口大小设置为1,2,7,7为4个分支。
在小的变型中使用相对较大的MixCFN扩展比以提高性能,而在大的变型中则将其降低为2以提高效率。遵循CSWin的缩放规则,将最高分辨率分支的基本通道C从32增加到64。#Blocks和#channels可以针对第3/第4分支灵活调整,以匹配特定的硬件成本。
3实验
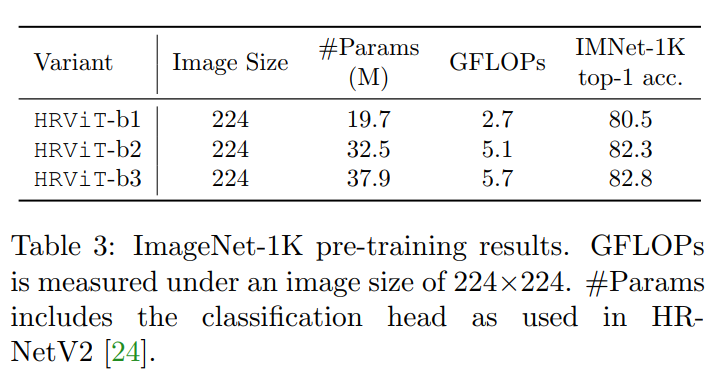
3.1 ImageNet分类
3.2 语义分割实验
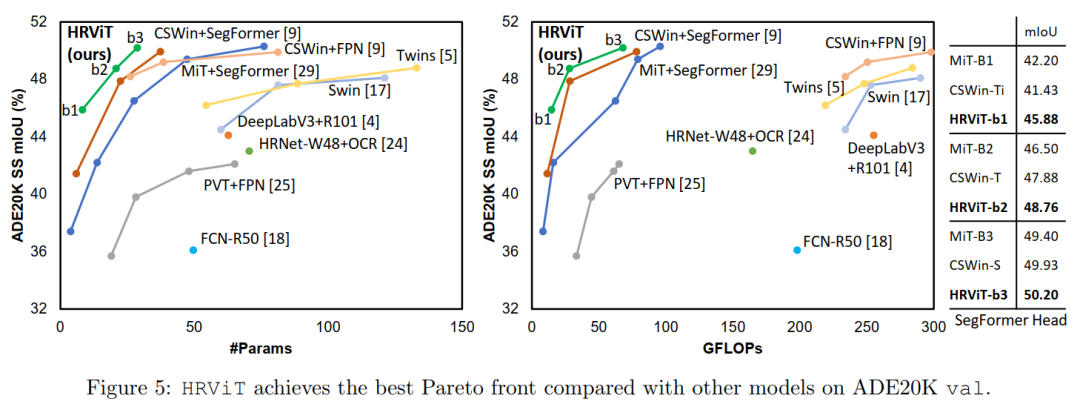
在ADE20K上,HRViT优于其他ViT,具有更好的性能和效率权衡。例如,使用SegFormer头,HRViT-b1比MiT-B1的mIoU高3.68%,参数减少40%,计算量减少8%。HRViT-b3比最好的CSWin-S实现了更高的mIoU,但节省了23%的参数和13%的FLOPs。与卷积HRNetV2+OCR相比,HRViT具有明显的性能优势,硬件效率显著提高。
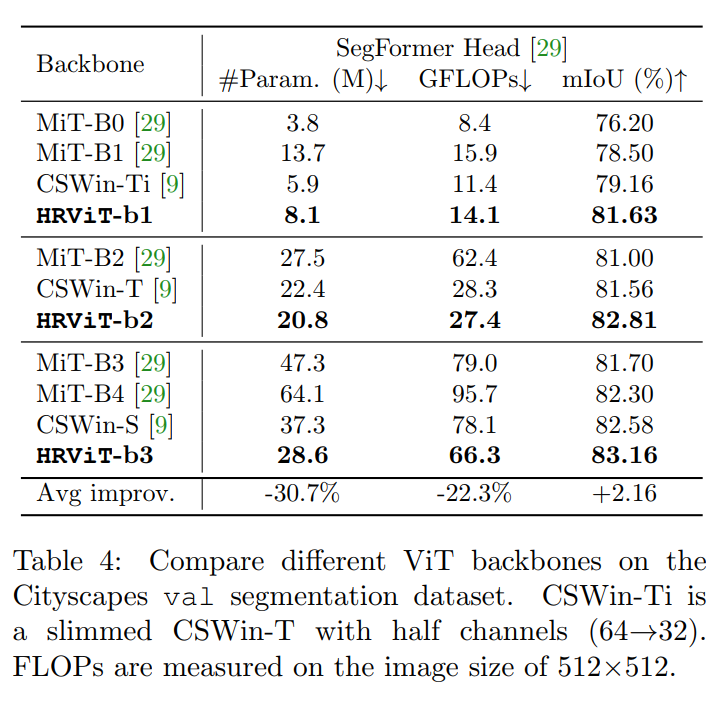
在表4中,HRViT-b1比MiT-B1和CSWin-Ti高出+3.13和+2.47个mIoU,这表明更大的HR架构有效宽度在小网络上尤其有效。
当HRViT-b3在Cityscapes上训练时,将多分支窗口设置为1-2-3-9。HRViTb3表现优于MiT-b4, mIoU比MiT-b4高0.86,参数减少55.4%,FLOPs降低30.7%。与MiT和CSWin两个SoTA ViT Backbone相比,HRViT的mIoU平均提高了+2.16,参数减少了30.7%,计算量减少了22.3%。
3.3 消融实验
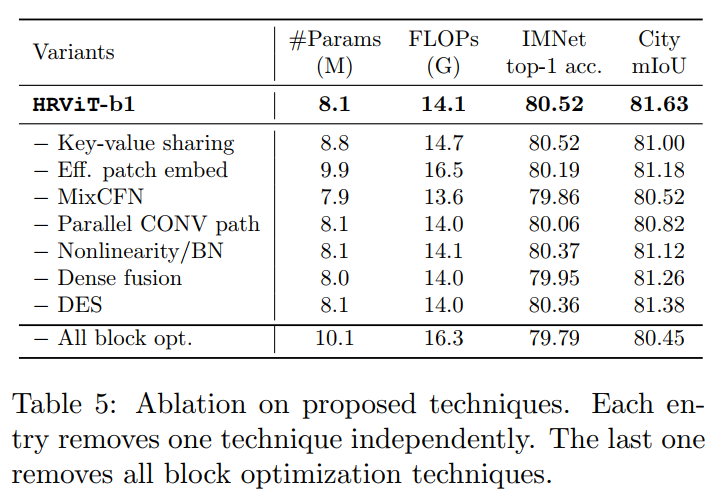
Sharing key-value
当去除Sharing key-value,即使用独立的key和Value时,HRViT-b1显示了相同的ImageNet-1K精度,但代价是较低的Cityscape分割mIoU,多9%的参数,多4%的计算。
Patch embedding
将有效的Patch embedding转换为基于卷积的overlap patch embedding。观察到多出了22%的参数和17%的FLOPs,同时并没有准确性和mIoU的提升。
MixCFN
去除MixCFN直接导致ImageNet精度下降0.66%,Cityscape mIoU损失0.11%,效率提高幅度很小。可以看到,MixCFN块是保证性能的一项重要技术。
Parallel CONV path
The embedded inverted residual path in the attention block非常轻量,但提高了0.46%的ImageNet精度和0.81%的mIoU。
Additional nonlinearity/BN
额外的Hardswish和BN引入了微不足道的开销,但提高了表达能力和可训练性,提高了0.15% ImageNet-1K精度和0.51%的mIoU。
Dense vs. sparse fusion layers
稀疏融合在HRViT中并不有效,因为它节省了微小的硬件成本(<1%),但导致了0.57%的精度下降和0.37%的mIoU损失。
Diversity-enhanced shortcut
非线性shortcut(DES)有助于提高特征的多样性,有效地将多任务的性能提升到更高的水平。由于基于Kronecker分解的投影仪的高效率,引入了可忽略的硬件成本。
Naive HRNet-ViT vs. HRViT
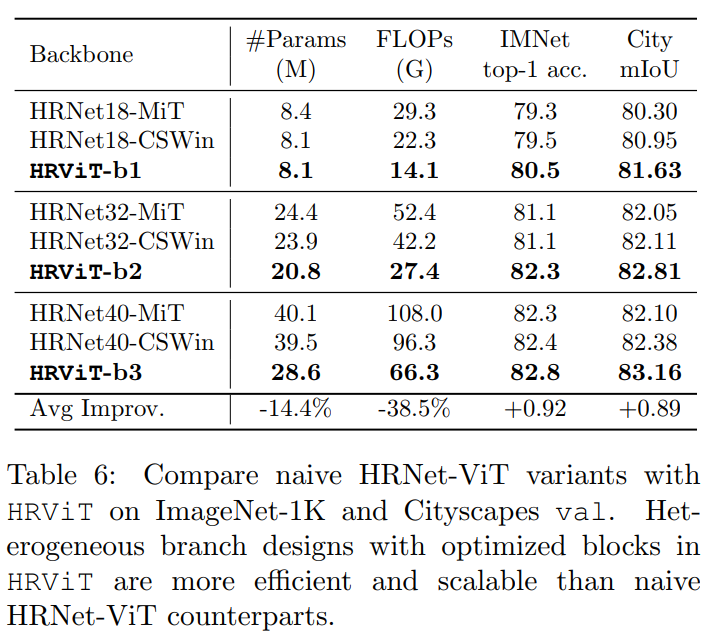
在表6中,直接用transformer blocks替换HRNetV2中的残差块作为简单的Baseline。当将HRNet-MiT与顺序MiT进行比较时,注意到HR变体在显著节省硬件成本的同时具有可比的mIoUs。这表明多分支体系结构确实有助于提高多尺度的可表示性。
然而,HRNet-ViT忽略了Transformer的昂贵的计算成本。因此,它是不可扩展的,因为硬件成本很快超过了它的性能增益。相比之下,异构分支和优化组件实现了硬件成本的良好控制,增强了模型的可表征性,并保持了良好的可扩展性。
4参考
[1].HRViT: Multi-Scale High-Resolution Vision Transformer
推荐阅读
PyTorch1.10发布:ZeroRedundancyOptimizer和Join
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
