
如何拥有一个兼具CNN的速度、Transformer精度的模型?字节甩出TRT-ViT教你

极市导读
字节设计了一系列面向TensorRT的Transformer(缩写为TRT-ViT),由具有ConvNets和Transformers的混合网络组成。>>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2205.09579
本文作者从实际应用的角度重新审视现有的Transformer。它们中的大多数甚至不如基本的ResNets系列高效,并且偏离了现实的部署场景。这可能是由于当前衡量计算效率的标准,例如FLOP或参数是片面的、次优的同时对硬件也不敏感的。
因此,本文直接将特定硬件上的TensorRT延迟作为效率指标,提供了更全面的计算能力、内存成本和带宽反馈。在一系列对照实验的基础上,本文得出了TensorRT的4个设计指南,例如Stage-level的Early CNN和Late Transformer,Block-level的Early Transformer和Late CNN。
据此,作者提出了一个面向TensorRT的Transformer家族,简称TRT-ViT。大量实验表明,TRT-ViT在各种视觉任务(例如图像分类、目标检测和语义分割)的延迟/准确性权衡方面明显优于现有的 ConvNet和视觉Transformer。
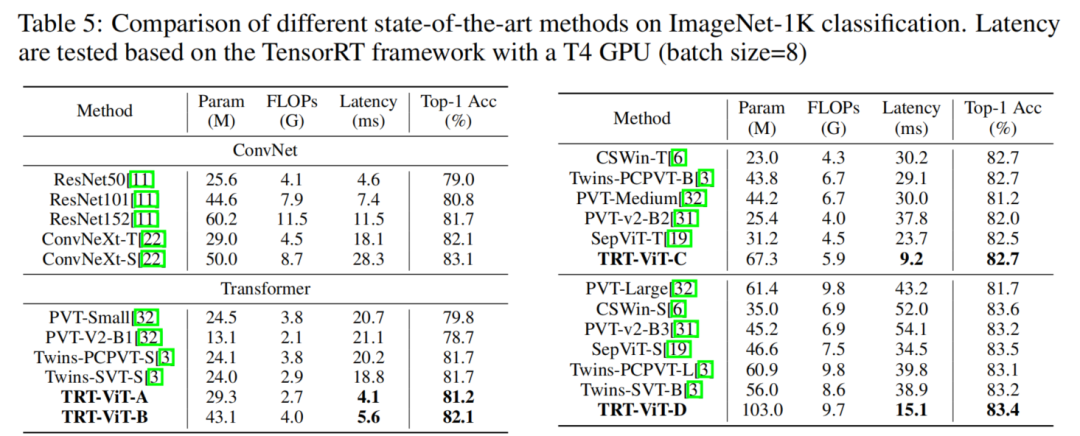
例如,在ImageNet-1k top-1 准确率为82.7% 时,TRT-ViT比CSWin快2.7倍,比Twins快2.0倍。在MS-COCO目标检测任务上,TRT-ViT实现了与Twins相当的性能,同时推理速度提高了2.8倍。
简介
最近,Vision Transformer在图像分类、语义分割和目标检测等各种计算机视觉任务中取得了显著的成功,并取得了明显优于CNN的性能提升。然而,从真实场景的角度来看,CNN仍然主导着视觉架构部署。
当深入挖掘背后的实质性性能改进时现有的Transformer,观察到这些收益是以大量资源开销为代价的。此外,当Transformer部署在资源受限的设备上时,它已成为一个障碍。为了减轻Transformer笨重的计算成本,一系列工作重点开发了高效的Vision Transformer,如Swin Transformer、PVT、Twins、CoAtNet和MobileViT。
尽管上述工作从不同的角度展示了ViT的效率,但关键设计主要由计算效率的间接标准指导,例如FLOP或参数。这种迂回的标准是片面的、次优的,并且偏离了真实场景的部署。事实上,该模型必须应对部署过程中的环境不确定性,这涉及到硬件感知特性,例如内存访问成本和I/O吞吐量。
具体来说,正如许多论文中所述,计算复杂度的间接度量在神经网络架构设计中被广泛使用,FLOPs和参数是近似的,但通常不能真实反映直接度量。真正关心的是速度或延迟。

在本文中,为了解决这种差异,作者提供了一种观点,将特定硬件上的TensorRT延迟视为直接的效率反馈。TensorRT在实际场景中已成为通用且易于部署的解决方案,有助于提供令人信服的面向硬件的解决方案指导。在这种直接准确的指导下,重新绘制了图1中几种现有竞争模型的准确性和效率权衡图。
如图1所示,Transformer具有性能良好的优势,而CNN则成功地实现了高效率。尽管ResNet在性能上不如竞争对手的Transformers令人印象深刻,但它仍然是准确率-延迟权衡下的最佳架构。
例如,ResNet使用 11.7毫秒(batch size = 8)来达到81.7%的准确率。虽然twins-pcpvt-s 在Imagenet-1k分类中达到了令人印象深刻的准确率,达到83.4%,但实现这一目标需要39.8毫秒。这些观察促使提出一个问题:如何设计一个性能与Transformer一样好、预测与ResNet一样快的模型?
为了回答这个问题,作者系统地探索了CNN和Transformer的混合设计。遵循Stage到Block的分层路线图来研究面向TensorRT的架构。通过广泛的实验,总结了在TensorRT上设计高效网络的4个设计准则:
Stage-Level:在后期Stage使用 Transformer Block可以最大化效率和性能;Stage-Level:由浅入深的Stage模式可以提升性能; Block-Level: Transformer和BottleNeck混合Block比Transformer效率更高;Block-Level:先全局后局部的模式有助于弥补性能问题。
基于上述准则设计了一系列面向TensorRT的Transformer(缩写为TRT-ViT),由具有ConvNets和Transformers的混合网络组成。CNN和Transformer在TRT-ViT的Stage和Block位置互补。
此外,提出了各种TRT-ViT Block以将CNN和Transformer组合成一个串行方案,以解耦异构概念并提高信息流的效率。所提出的TRT-ViT在延迟准确度交易方面优于现有的ConvNets和Vision Transformer, 例如,在ImageNet-1k top-1 准确率为 82.7% 时,TRT-ViT比CSWin快2.7倍,比Twins快2.0倍。
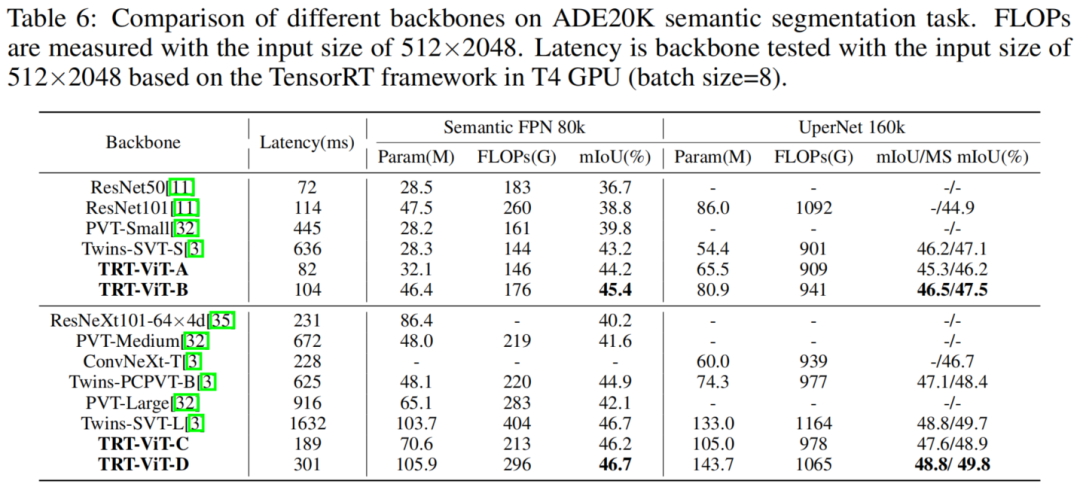
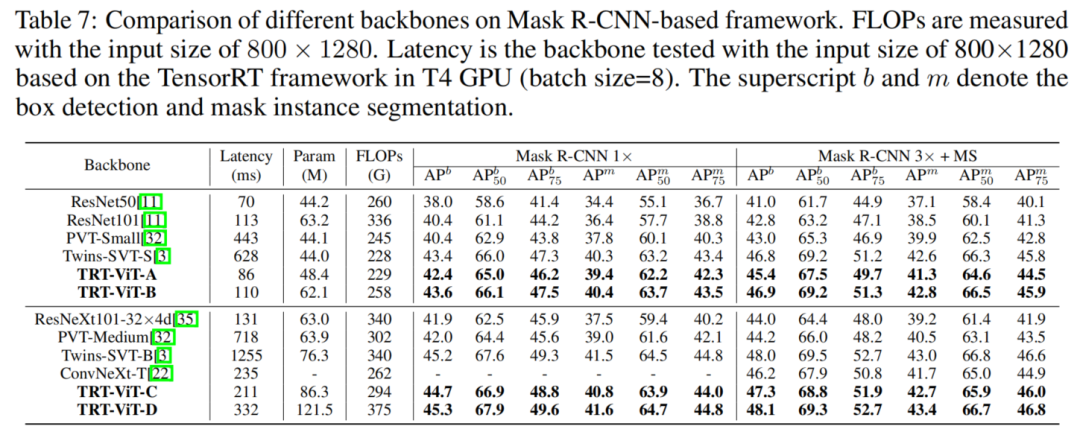
更重要的是,TRT-ViT在下游任务上表现出更显着的延迟/准确性权衡增益。如图1所示,TRT-ViT 实现了与Twins相当的性能,而推理速度在MS-COCO目标检测上提高了2.8倍,在ADE20K语义分割任务上提高了4.4倍。在相似的TensorRT延迟下,TRT-ViT在COCO检测上的性能比ResNet高3.2AP(40.4到43.6),在ADE20K分割上比ResNet高6.6%(38.86%到45.4%)。
TRT-ViT
2.1 基于TensorRT的设计指南
为了研究分析了2个SOTA网络 ResNet 和 ViT 的运行性能。它们在 ImageNet1K 分类任务上都非常准确,并且在业界很流行。虽然只分析了这2个网络,但它们代表了目前的趋势。它们的核心是 BottleNeck Block 和 Transformer Block ,它们也是其他最先进网络的关键组件,例如 ConvNext 和 Swin。
为了更好地说明经验结果,遵循 RepLKNet,使用操作或块的计算密度(以每秒 Tera 浮点操作数,TeraFLOPS 衡量)来量化其在硬件上的效率,描述如下
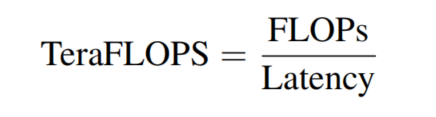
从图 1(a) 和表 1 可以看出,BottleNeck Block 更高效,具有更高的 TeraFLOPS,而 Transformer Block更强大,在 ImageNet 上具有更好的精度。
在本文中,目标是设计一个实现类似 ResNet 的效率和类似 Transformer 的性能的网络。设计一个混合了 BottleNeck 和 Transformer Block的网络很简单,例如 MobileViT。然而,这些论文要么专注于优化 FLOP,这是衡量效率的间接标准,要么将大量精力放在移动设备上。

将 Transformer 简单地应用于 CNN 通常会导致性能和速度下降。因此,总结了在 TensorRT 上有效设计高效网络的4个实用准则。
准则1:Transformer Block在后期使用可以最大限度地提高效率和性能之间的平衡
人们认为Transformer块比卷积块更强大但效率更低,因为Transformer旨在建立特征之间的全局连接。相比之下,卷积只捕获局部信息。在这里,提供了配备TensorRT的详细分析。如图1所示,堆叠Transformer块(PVT-Medium)在ImageNet1K分类任务上的 Top-1 准确率为 81.2%,而BottleNeck块(ResNet50)的相应准确率仅为 79.0%。然而,如表1所示,在效率方面,BottleNeck模块在各种输入分辨率下的TeraFLOPS始终优于Transformer模块。
此外,当输入分辨率降低时,Transformer和BottleNeck之间的效率差距会缩小。具体来说,当输入分辨率为56×56时,Transformer的TeraFLOPS 值只有81,不到BottleNeck的TeraFLOPS值378的4分之1。但是,当分辨率降低到7×7时,Transformer的TeraFLOPS值几乎等于BottleNeck,分别为599和670。这一观察促使在TensorRT上设计高效网络时将Transformer模块置于后期阶段以平衡性能和效率。CoATNet也遵循类似的规则并提出混合了Transformer和CNN 模块的网络。
遵循准则1,原生解决方案是在后期将BottleNeck块替换为Transformer块,在表 1 中称为 MixNetV(MixNet Valilla)。可以看到MixNetV比ViT更快,比ResNet更准确。
准则2:从浅到深的Stage模式可以提高性能
作者研究了各种 SOTA 网络(例如 RestNet 和 ViT)中 TeraParams 的属性,并在表 1 中展示了发现。BottleNeck 的 TeraParams 在后期变得更加突出,这表明在后期堆叠更多的 BottleNeck 块将与早期相比,模型容量更大。
在 ViT 的 Transformer 块中也可以找到类似的趋势。这一观察启发使早期阶段更浅,晚期阶段更深。假设这种由浅入深的阶段模式将带来更多参数,提高模型容量并在不降低效率的情况下获得更好的性能。
为了验证这一点,对ResNet50进行了相应的修改,并提供了表2中的经验结果。将第1阶段和第2阶段的Stage深度分别从3、4减少到2、3,同时增加最后阶段的Stage深度从3到5。从表2中可以看到Refined-ResNet50在ImageNet1K上的Top-1准确率比ResNet50高0.3%,同时在TensorRT上稍快。此外,将这种由浅入深的阶段模式应用到PvT-Small上,得到Refined-PvT-Small,更好更快。最后,在MixNetV上也可以得出类似的结论,这并不奇怪。
准则3:BottleNeck Block和Transformer Block混合使用比Transformer更有效
虽然按照准则 1 和 2 取得了显着的改进,但Refined-MixNetV在效率上无法达到ResNet的效率。为此,设计一个利用Transformer和BottleNeck两者的优点的混合模块。
在图3(a)和(b)中提供了2个混合块,其中首先使用1×1 Conv层来投影输入通道的数量,最后使用Concat层来合并全局和局部特征。引入收缩率R来控制Transformer块在混合块中的比例,定义为Transformer块的输出通道除以混合块的输出通道。如图3(a)所示,在MixBlockA中,创建了2个分支,一个用于Transformer,另一个用于BottleNeck。
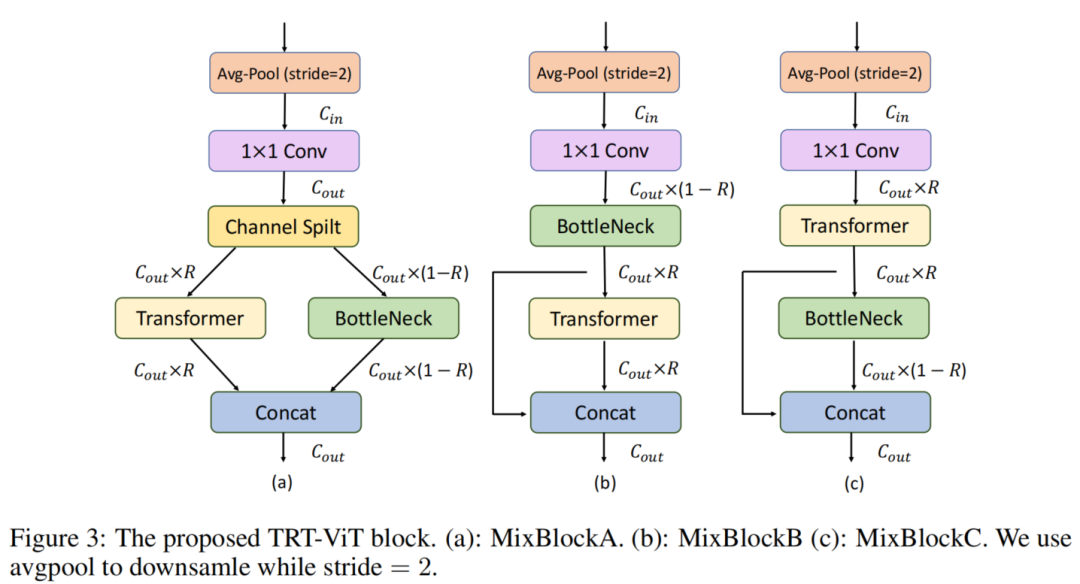
此外,通道拆分层用于进一步提高效率,其中Transformer块的输出通道为,而对应的通道为。在MixBlockB中,Transformer块和BottleNeck块是顺序堆叠的,Transformer块和BottleNeck块的输出通道相等,即此处R=0.5。从表1可以看出,与Transformer块相比,2个混合块的TeraFLOPS都显着增加,这表明混合块比Transformer块更有效。而且,它们对应的TeraParams也更好,这表明它们具有实现更好性能的潜力。
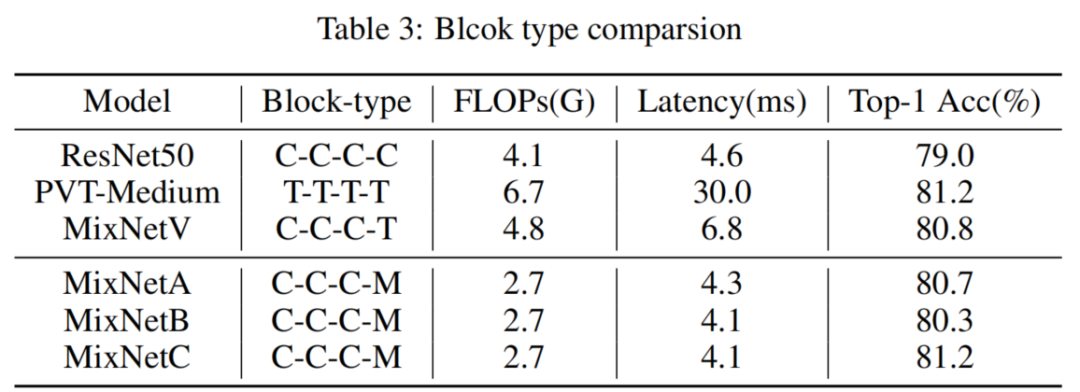
用MixBlockA和MixBlockB替换MixNetV中的Transformer块,构建了MixNetA和MixNetB。如表3所示,其中C、T和M分别表示Convolution、Transformer和MixBlock,可以看到MixNetA和MixNetB都优于ResNet50。但是,在准确性方面,它们都无法击败MixNetV。此外,PVT-Medium和2种混合网络之间的性能差距也不容忽视。
准则4:Global-then-Local Block有助于弥补性能问题
正如许多论文中所描述的,感受野通常很大的Transformer从输入特征中提取全局信息,并在每个条目内实现信息交换。相比之下,卷积的小感受野只挖掘局部信息。首先获取全局信息并在局部进行提炼,而不是先提取局部信息并在全局范围内提炼更有意义。此外,MixBlockB中的收缩率R必须为0.5,失去了进一步调整的灵活性。global-then-local块模式解决了这个问题,其中R可以是0到1之间的任何值。
按照这个准则,在MixBlockB中转换Transformer操作和Convolution操作的顺序,得到MixBlockC,如图3(c)所示。MixBlockC的TeraFLOPS分数与MixBlockB相当。然后,用MixBlockC代替MixBlockB,得到MixNetC。与直觉一致,如表3所示,MixNetC的性能优于MixNetB,而不会牺牲任何效率。此外,MixNetC在准确性和TRT延迟方面都超过了MixNetV。
此外,MixNetC和PVT-Medium之间的差距得到了弥补,MixNetC实现了类似ResNet的效率和类似Transformer的性能。
2.2 TRT-ViT: An Efficient Network on TensorRT
按照ResNet的基本配置构建了TRT-ViT 架构,其中采用特征金字塔结构,特征图的分辨率随着网络深度而降低,而通道数增加。
接下来,应用提出的设计准则来构建TRT-ViT。整个架构分为5个阶段,后期Stage只使用MixBlockC,而卷积层用于早期Stage。此外,使用了由浅入深的Stage模式,与ResNet中的Stage模式相比,早期Stage更浅,后期Stage更深。
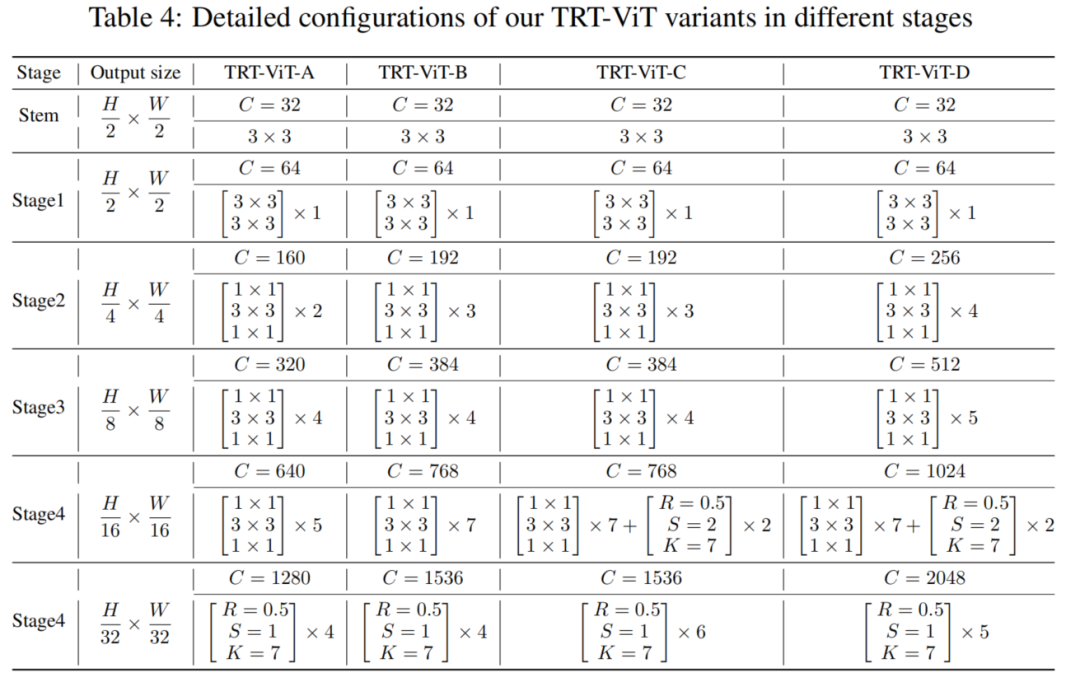
为了与其他SOTA网络进行公平比较,提出了4种变体,TRT-ViT-A/B/C/D,其配置列于表4。3×3表示卷积核大小=3,C表示一个阶段的输出通道。R、S、K是所提出的MixBlockC中的内部参数,其中S代表Transformer Block中的空间缩减率,K表示MixBlockC中BottleNeck的kernel-size大小,R 表示收缩率。
为简单起见,设置R=0.5。TRT-ViT-A/B/C/D的Stage深度分别为2-4-5-4、3-4-7-4、3-4-9-6、4-5-9-5。对于所有变体,在最后阶段使用MixBlockC,即stage5。
对于更大的型号,TRT-ViT-C/D,另外在stage4使用2个MixBlcokC。另外,每个MLP层的扩展率设置为3,Transformer中的head dim设置为32。对于标准化和激活函数,BottleNeck块使用BatchNorm和ReLU,Transformer块使用LayerNorm和GeLU。
实验
3.1 ImageNet-1K
3.2 语义分割
3.3 目标检测与实例分割
公众号后台回复“CVPR 2022”获取论文合集打包下载~

