
(附代码)视频异常行为检测算法MPN,多个数据库上达到SOTA
点击左上方蓝字关注我们

作者:吕辉, 陈宸, 崔振, 许春燕, 李勇, 杨健
单位:南京理工大学;北卡夏洛特分校

摘要:
该工作提出了一个场景模式自适应的动态原型(prototype)学习框架,以实时的学习视频中的正常模式,来辅助视频帧的预测,然后通过衡量视频帧的预测误差和和学习到的正常模式原型向量与输入特征的差异程度来检测异常。提出的新算法在无监督异常检测的数据集上和新的少样本学习场景中,均达到了较好的成绩。
文章链接:https://arxiv.org/abs/2104.06689
代码链接:https://github.com/ktr-hubrt/MPN & http://vgg-ai.cn/pages/Resource/
拟解决的问题:
近来,基于自编码器的视频帧重建(或未来帧预测)方法成为视频异常检测的一个潮流范式。这些仅仅使用包含正常模式的数据训练得到的模型,在遇到没有见过的异常模式的数据时,往往会产生比较大的重构误差。但是由于深度神经网络极强的泛化能力,深度模型对一些异常的视频帧(部分区域)也会重建(或预测)的较好,这就导致了“过度泛化”的问题。在这份工作中,我们设计了一个动态原型学习的组件,来动态实时地建模和压缩视频中的正常模式为原型(prototype),以促进模型对正常视频帧的重建(或预测)和抑制对异常视频帧的重建(或预测)。并且,我们引入元学习理论,赋予动态原型学习组件场景模式自适应的能力,从而不需要设计手动的更新规则和阈值来使原型适应不同的测试场景,是的模型具有快速高效的场景自适应能力。
贡献:
1)我们设计了一个动态原型学习组件来学习和建模监控视频里的正常模式。其中,我们结合自注意力机制,隐式自主的压缩视频特征为表征正常模式的原型向量。整个框架是端到端的,可微的。
2)我们在动态原型学习组件中引入元学习理论,来赋予模型场景自适应的能力。通过学习一个好的初始化参数和参数对应的更新步长集合,仅仅用过少次的参数更新,算法模型就可以自动地适应到新的测试场景。
3)我们设计的算法在无监督异常检测和少样本异常检测的场景下均取得了较好的成绩。
模型设计:
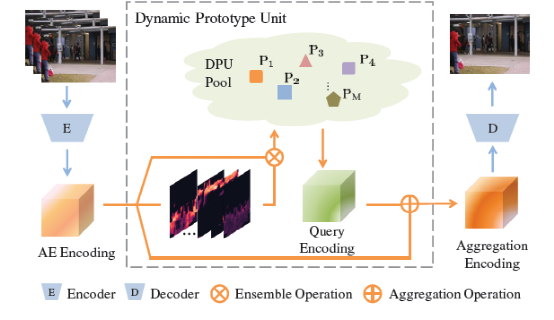
Dynamic Prototype Unit(DPU):
我们设计的DPU输入编码器(E)得到的编码特征,输出动态原型加强后的特征。通过结合自监督注意力机制,DPU首先得到多个对应输入编码特征每个元素位置的注意力图,然后分别得到对应的多个原型特征向量。通过对原型向量的查询和提取,就可以得到加强后的特征图。
a) 注意力过程:
首先,我们通过多个映射函数分别得到m个注意力图,这边我们成为normalcy map,分别代表每个空间位置的特征向量对于生成对应的原型向量的比重。
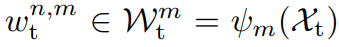
公式中,x自编码器输出的编码特征。
b) 合奏过程:
得到normalcy map之后,我们使用带权和的形式,整合空间特征向量来生成对应的原型向量:
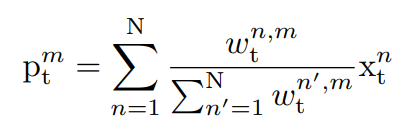
c) 检索过程:
得到代表场景正常元素的原型向量之后,我们需要利用这些原型表征的信息来辅助未来视频帧的预测。我们首先使用原始自编码器输出的特征来检索获取的原型向量,以得到加强后的特征,然后就可以解码新得到的特征来预测未来帧:
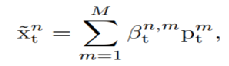
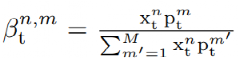
通过衡量每个空间位置的特征向量(来自于自编码器输出的特征)和原型向量的相似度,对于每个空间位置,我们可以得到最接近这个像素位置的原型向量(软权重的形式),进而得到完成的特征。
损失函数的设置:
为了训练完整的异常检测框架,我们分别设置了未来帧预测损失,特征检索损失来实现预测未来帧和学习动态原型向量的目的。
a) 未来帧预测损失:
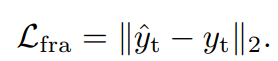
b) 特征重建损失:
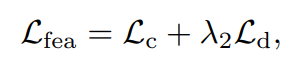
特征重建损失包括两个部分,一个是紧致度量,一个是差异度量。前者使原型向量建模视频中的正常元素信息,后者促使学习到的原型向量建模不同的信息。
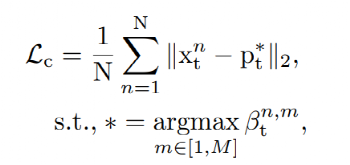
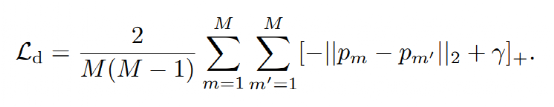
c) 完整损失:
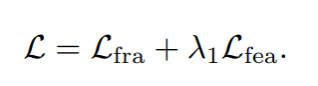
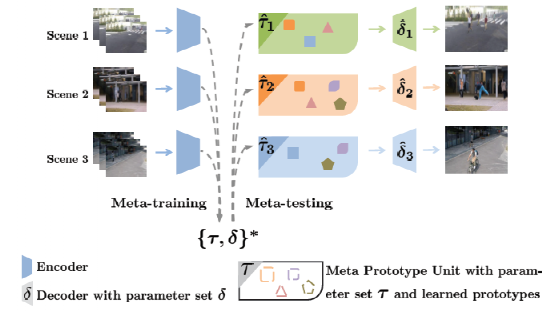
Meta Prototype Unit(MPU):
结合元学习理论,我们把DPU组件进化为元学习原型组件。利用训练集的不同场景,我们学习一组最优的初始化参数集合和对应的更新步长,在测试时,更新对应的参数,我们就可以得到场景模式自适应的异常检测器。
首先我们把动态原型组件和后端的解码函数囊括进元学习组件中:
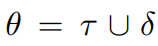
对应于完整的异常检测框架,其中代表自编码器参数集合,代表后端解码函数参数集合,代表动态原型组件的参数集合:
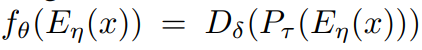
然后,我们定义更新函数为:
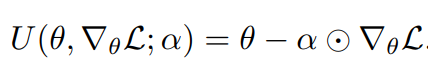
通过一步更新,我们可以得到对应的参数集合:
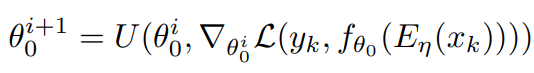
利用梯度的梯度算法,我们可以得到一组姣好的初始化参数集合和更新步长集合:
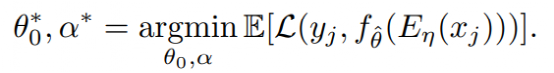
实现细节:
在测试过程中,我们使用带权重的未来帧预测误差和特征紧致度量来衡量视频帧的异常程度:
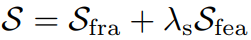
我们把算法模型的度量评优分为两个场景,分别是无监督异常检测和少样本异常检测。对于前者,在训练过程中,我们在无监督异常检测数据集上训练和测试算法模型。对于后者,我们首先在公开的大型异常检测数据集(仅利用正常视频)上训练算法模型,以学习初始参数集合和更新步长集合,然后在其他的异常检测数据集上,使用极少次数(本文中1次)的参数更新,来试验模型的场景适应,然后再通过模型的测试,来衡量模型的性能。
实验结果:
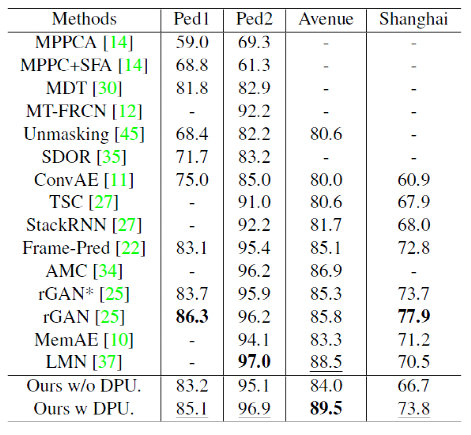
DPU在无监督的异常检测数据集上进行了试验,均得到最优或次优的结果。值得一提的是,我们设计的模型中建模的动态原型,可以视为一种隐藏向量,从而不需要像之前基于memory机制的算法模型一样,建模整个训练集的正常元素模式,并且存储下来,占据额外的存储空间。同时减少的这部分数据I/O操作也使得我们设计的算法模型具有更快地速度。
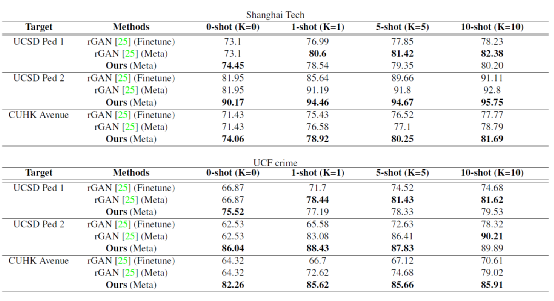
MPU在元学习few-shot场景下,也取得了不错的结果。
我们展示了原型学习过程中产生的自注意力图(第一列是未来帧,第二列是检测得到的异常图,第三列是多组自注意力图之和,后面三列均是单个注意力图):

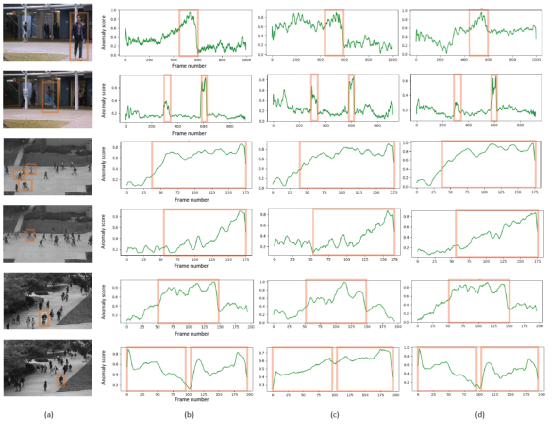
我们还展示了算法模型在一些测试视频上的预测结果:
我们还分析了多个SOTA模型的运行效率:
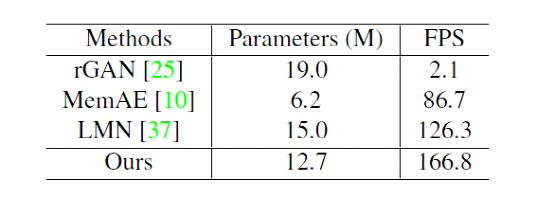
数据均在4核CPU(E5-2650),单块GPURTX-2080Ti机器上实验得出。
更多的细节分析请见原文,代码已经开源,敬请关注加星,谢谢大家。
文章链接:https://arxiv.org/abs/2104.06689
代码链接:https://github.com/ktr-hubrt/MPN
课题组网站:http://vgg-ai.cn
END
整理不易,点赞三连↓