
【NLP】大模型训练之难,难于上青天?预训练易用、效率超群的「李白」模型库来了!
机器之心编辑部
LiBai(李白)模型库覆盖了 Hugging Face、Megatron-LM、DeepSpeed、FairSeq 这些所有主流 Transformer 库的优点,让大模型训练飞入寻常百姓家。
支持单卡代码平滑地扩展到分布式。LiBai 内置的模型与 PyTorch 保持一致风格,大大降低学习和使用成本,只需要简单配置,就可以便捷地扩展至任意规模的并行。这意味着,你可以在单卡上增加新功能,进行模型调试,跑通代码后再丝滑地迁移到分布式上进行训练。如果完全不想配置分布式训练,或是觉得手动配置的分布式训练太慢,那可以试用分布式托管特性,只需安装自动并行的包(https://libai.readthedocs.io/en/latest/tutorials/basics/Auto_Parallel.html),并在 LiBai 里配置一行 graph.auto_parallel=True,就可以专注于模型本身,在完全不用操心分布式的同时获得较快的训练速度。
兼容 Hugging Face。OneFlow 和 PyTorch 在 API 层次高度兼容,可以通过简单的代码修改就可以导入 Hugging Face 模型,只须 import oneflow as torch ,基于 LiBai 的数据并行、自动混合精度、Activation Checkpoint、ZeRO 等机制进行一个大规模模型的训练。如果把模型的个别层次替换为 LiBai 内置的 layers ,就可以使用 3D 并行来训练一个大模型。
模块化设计。在 LiBai 的实现中,不仅为模型构建提供可复用的基础计算模块,也针对数据加载、训练逻辑、指标计算等做了抽象和模块化处理,方便用户根据自己的需求重写,然后作为插件集成到 LiBai 的训练系统中进行训练。
开箱即用。大模型训练通常需要依赖一些技术,LiBai 提供了混合精度训练、梯度重计算、梯度累加、ZeRO 等特性,可以轻松与数据并行、模型并行、流水并行组合使用。
快速复现实验。OneFlow 团队参考了 Detectron2 LazyConfig(https://github.com/facebookresearch/detectron2/blob/main/docs/tutorials/lazyconfigs.md) 来构建 LiBai 的配置系统,相比于传统的 argparse 和 yacs-based 配置方式,LiBai 的配置系统更加灵活,使用 Python 语法完成整体构建,所以添加新的参数和模块非常方便,只需要 import 对应的模块即可完成新模块的添加。同时,训练配置还可以序列化成 yaml 文件进行保存,方便直接在文件中进行关键字搜索来查找配置项,如果用户想要复现之前的实验的结果,也直接传入保存的 config.yaml 作为训练配置,保留非常多脚本的文件既不利于查看有效修改,在复现实验的同时也容易弄混实验配置。
高效性能。通过和 Megatron-LM 进行严格的 kernel 对齐,实现了多种 kernel fusion 操作,同时得益于 OneFlow 静态图的设计,不管是单卡性能还是各种组合并行的效率,LiBai 都优于英伟达深度优化的 Megatron-LM 和微软的 DeepSpeed。
Megatron-LM 固定 commit:https://github.com/NVIDIA/Megatron-LM/commit/e156d2fea7fc5c98e645f7742eb86b643956d840 LiBai commit: https://github.com/Oneflow-Inc/libai/commit/9fc504c457da4fd1e92d854c60b7271c89a55222 OneFlow commit: https://github.com/Oneflow-Inc/oneflow/commit/55b822e4d3c88757d11077d7546981309125c73f
注:以下每组参数的含义: DP 数据并行、MP 模型并行、PP 流水并行、2D 并行、3D 并行 fp16:打开混合精度训练 (amp) nl: num layers (当 Pipeline parallel size = 8 时,为了让每个 stage 有相对数量的 layer 进行计算,我们将 num layers 从 24 调整为 48)
ac: enable activation checkpointing mb: micro-batch size per gpu gb: global batch size total dxmxp,其中: d = 数据并行度(data-parallel-size) m = 模型并行度(tensor-model-parallel-size) p = 流水并行度(pipeline-model-parallel-size)
1n1g 表示单机单卡,1n8g 表示单机 8 卡, 2n8g 表示 2 机每机 8 卡共 16 卡, 4n8g 表示 4 机共 32 卡 grad_acc_num_step = global_batch_size / (micro_batch_size * data_parallel_size) 展示的结果为 Throughout
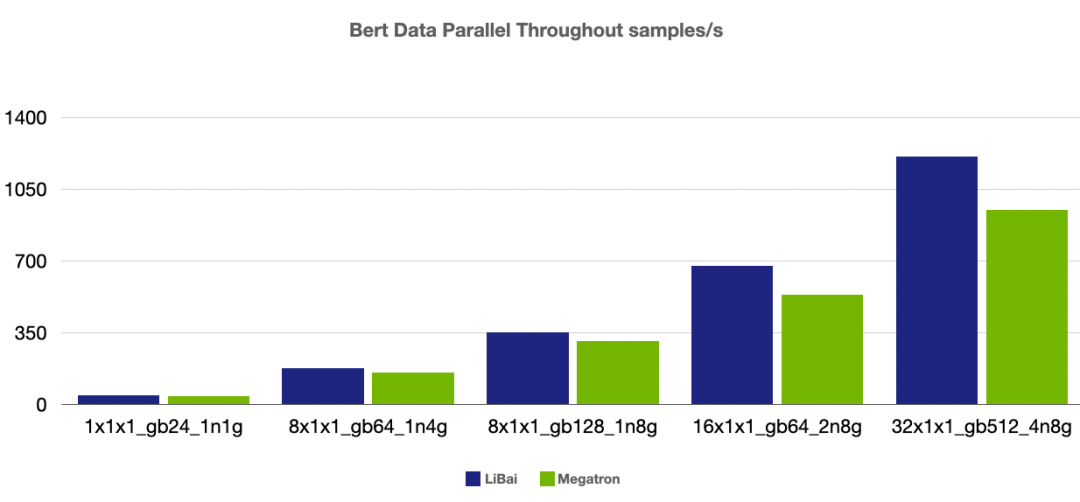
(注:本组 num layers = 24,开启 amp,1n1g micro-batch size = 24, 其余组 micro-batch size = 16)
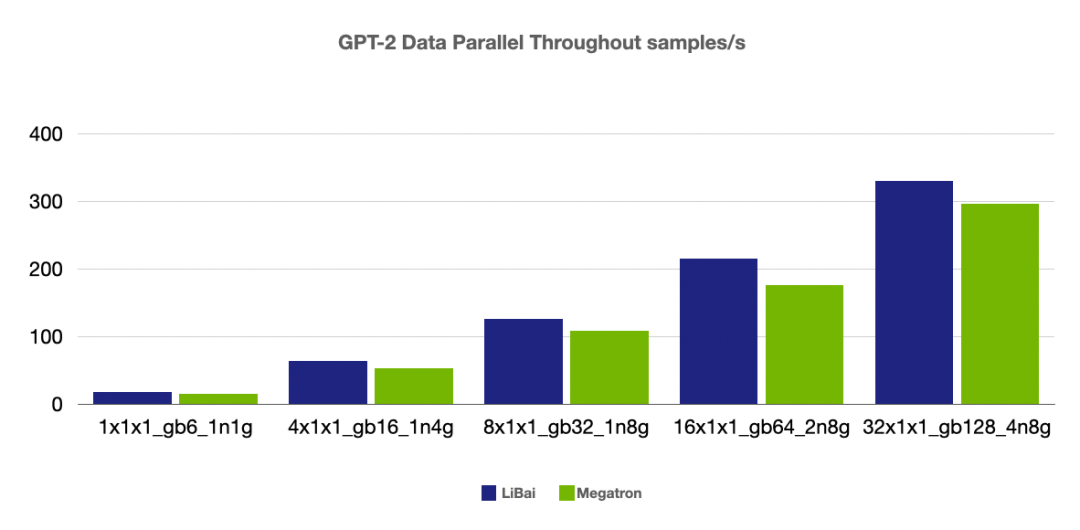
(注:本组 num layers = 24,开启 amp,1n1g micro-batch size = 6, 其余组 micro-batch size = 4)
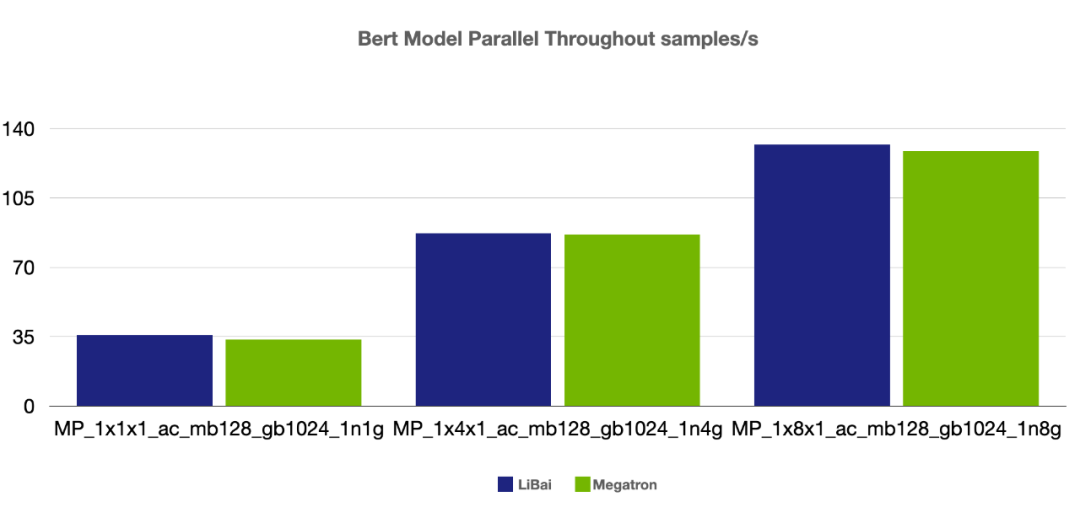
(注:本组 num layers = 24,开启 amp, 开启 activation checkpointing,
micro-batch size = 128, global batch size = 1024, grad acc step = 8)
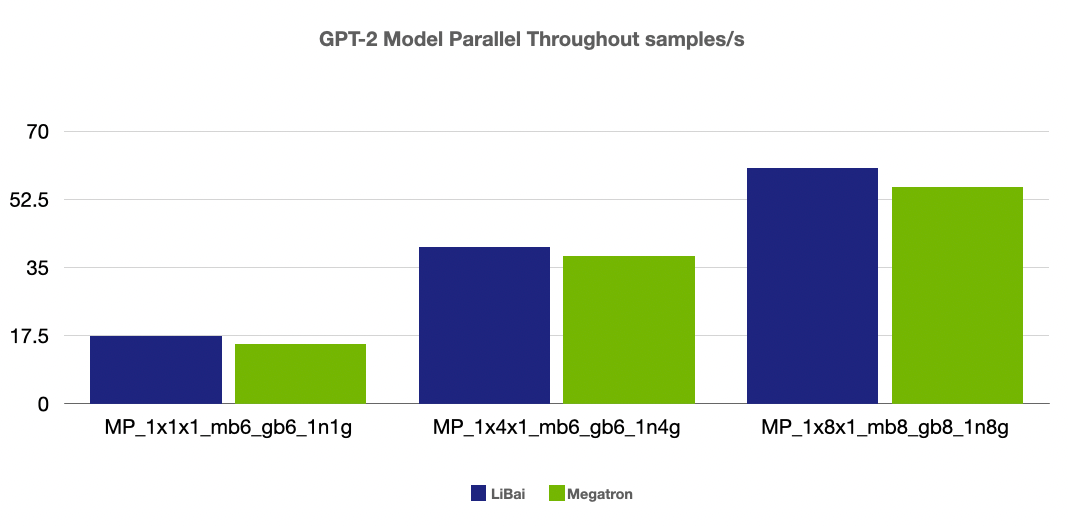
(注:本组 num layers = 24,开启 amp)
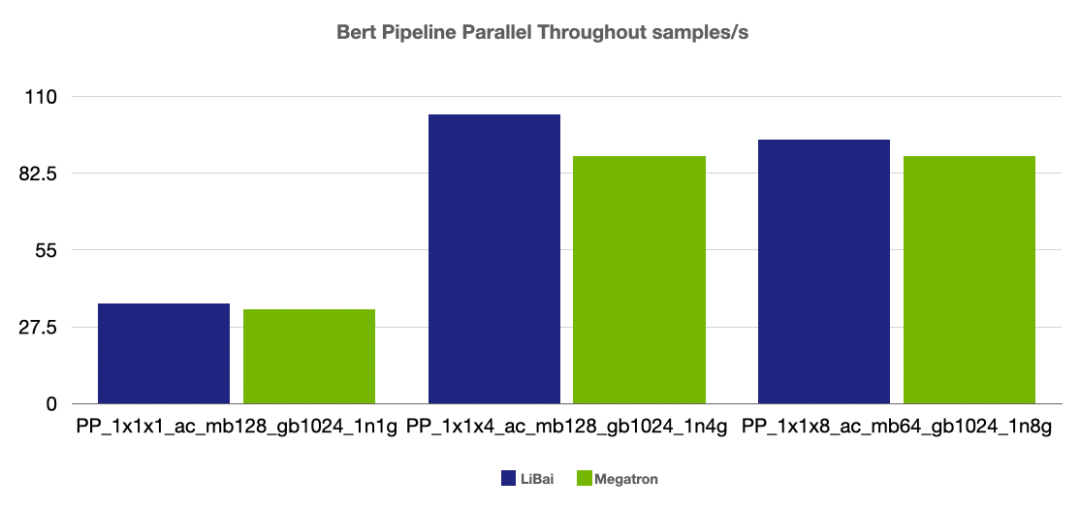
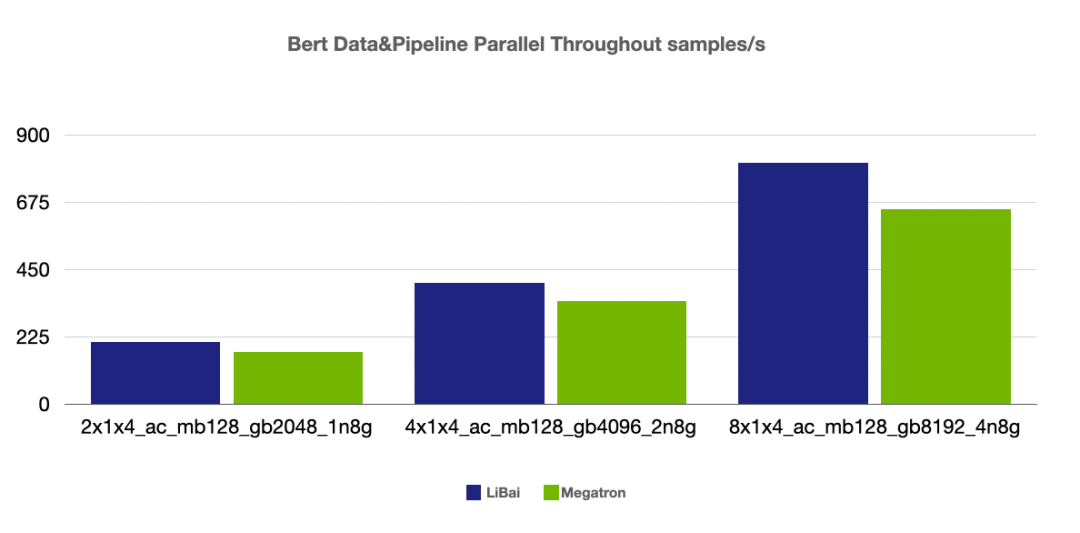
(注:前两组 num layers = 24,grad acc step = 8, 最后一组 num layers = 48, grad acc step = 16,均开启 amp,开启 activation checkpointing)
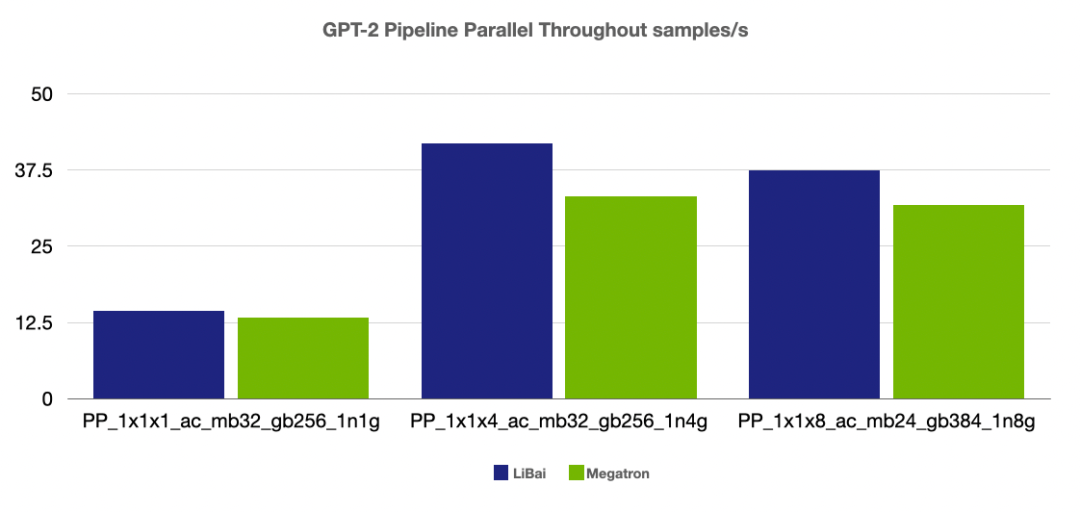
(注:前两组 num layers = 24,grad acc step = 8, 最后一组 num layers = 48, grad acc step = 16,均开启 amp,开启 activation checkpointing)
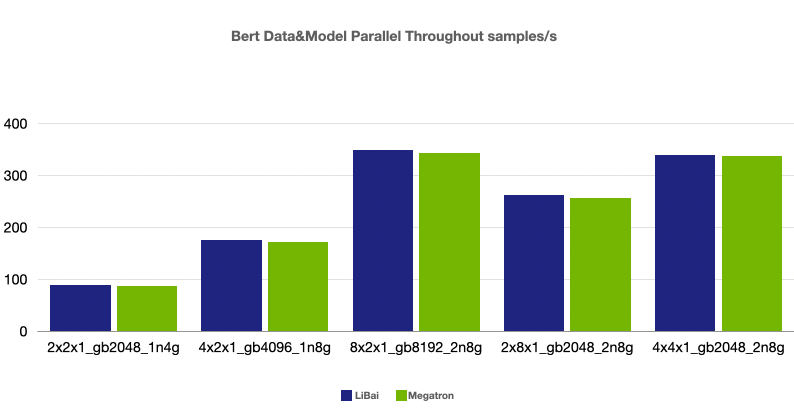
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing, micro-batch size = 128,grad acc step = 8)
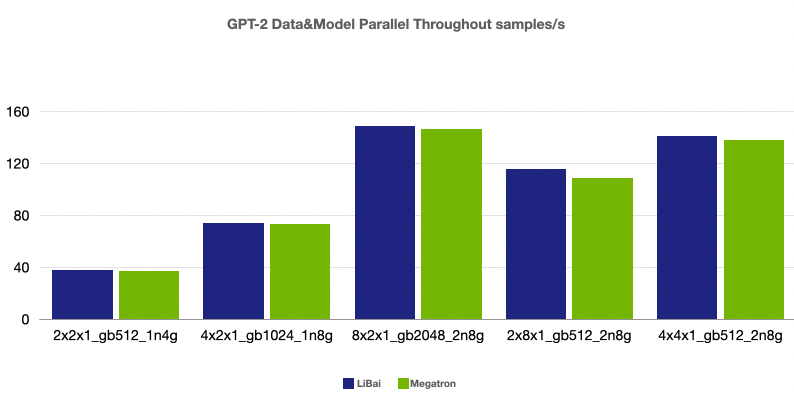
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing, micro-batch size = 32,grad acc step = 8)
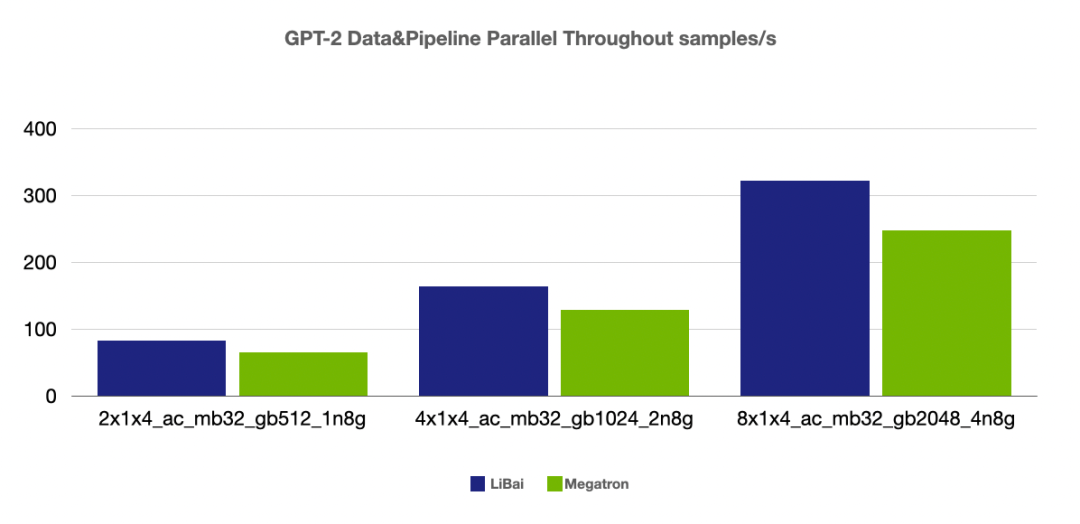
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing, micro-batch size = 128,grad acc step = 8)
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing, micro-batch size = 32,grad acc step = 8)
 (注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing,grad acc step = 8)
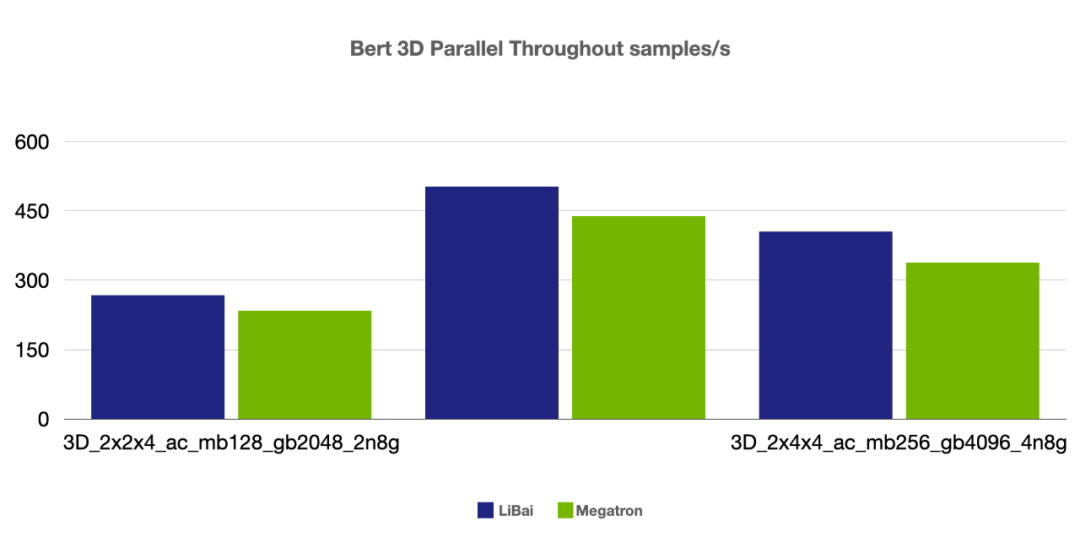
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing,grad acc step = 8)
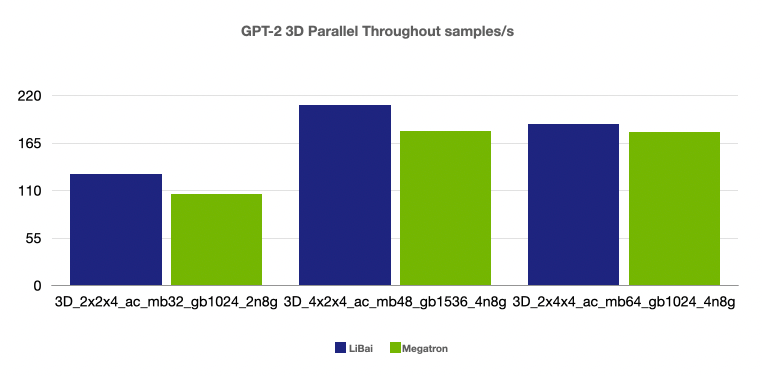
(注:本组均为 num layers = 24,均开启 amp,开启 activation checkpointing,grad acc step = 8)
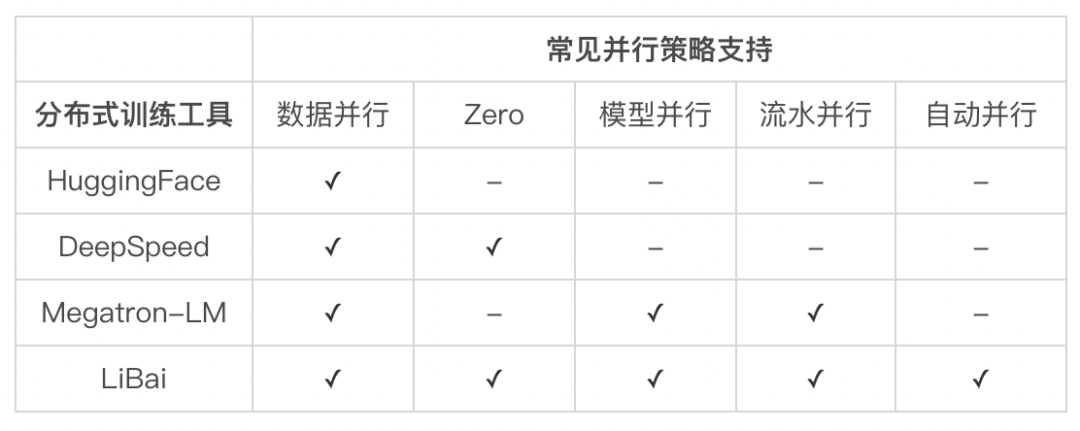
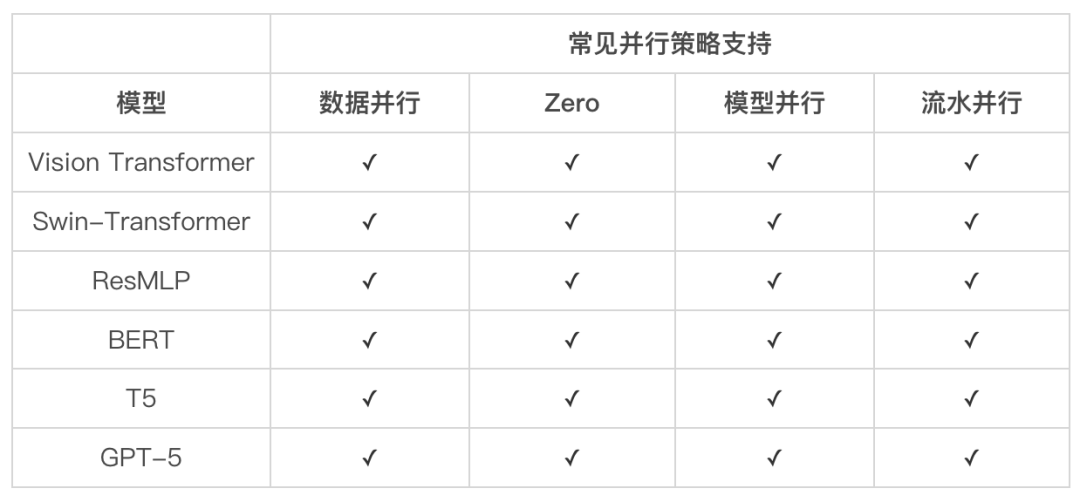
兼容性。可以有效和目前基于 PyTorch 实现的 SOTA 模型兼容,方便用户快速迁移模型。 高效性。无论是单卡还是多卡,用户使用 LiBai 都可以提高训练效率。 易用性。LiBai 具有优秀的扩展性,可以很方便地根据需求修改模型,增加新功能,更快地完成原型功能的开发。以几乎无感知、零学习成本的方式帮助用户大幅降低分布式深度学习训练的门槛,用户在使用 LiBai 开发新模型和新功能时,只要会单张 GPU 编程就能自动扩展到大规模 GPU 的集群,无须为分布式训练重写代码,从而提高开发的效率。
# configs/common/train.py# Distributed argumentsdist=dict(data_parallel_size=1,tensor_parallel_size=1,pipeline_parallel_size=1,)
纯数据并行
# your config.pyfrom libai.config import get_configtrain = get_config("common/train.py").traintrain.dist.data_parallel_size = 8
纯模型并行
# your config.pyfrom libai.config import get_configtrain = get_config("common/train.py").traintrain.dist.tensor_parallel_size = 8
# your config.pyfrom libai.config import get_configtrain = get_config("common/train.py").traintrain.dist.data_parallel_size = 2train.dist.tensor_parallel_size = 4
from libai.layers import Linearself.head = Linear(hidden_size, num_classes)
from libai.layers import Linearimport libai.utils.distributed as distself.head = Linear(hidden_size, num_classes).to_global(placement=dist.get_layer_placement(-1))
from libai.layers import Linearself.head = Linear(hidden_size, num_classes, layer_idx=-1)
class MyModule(nn.Module):def __init__(self, ... *, layer_idx):...self.layer_idx = layer_idx...def forward(self, input_data):input_data = input_data.to_global(placement=dist.get_layer_placement(self.layer_idx))...
set the number of pipeline stages to be 2train.dist.pipeline_parallel_size = 2# set model layers for pipelinetrain.dist.pipeline_num_layers = hidden_layers
# your config.pyfrom libai.config import get_configtrain = get_config("common/train.py").traintrain.dist.data_parallel_size = 2train.dist.tensor_parallel_size = 2train.dist.pipeline_parallel_size = 2hidden_layers = 8 #网络的层数train.dist.pipeline_num_layers = hidden_layers
[ |X00 gpu0 | X01 gpu1--------------------------X10 gpu2 | X11 gpu3| ]
LiBai 中封装 dist.get_nd_sbp()是为了兼容 1D parallel 的需求,同时 dist.get_layer_placement()是为了方便配置 pipeline parallel。大多数情况下,用户可以直接参照以下代码:
# test.pyimport oneflow as flowfrom omegaconf import DictConfigfrom oneflow import nnfrom libai.utils import distributed as distcfg = DictConfig(dict(data_parallel_size=2, tensor_parallel_size=2, pipeline_parallel_size=1))dist.setup_dist_util(cfg)class Noise(nn.Module):def __init__(self):super().__init__()self.noise_tensor = flow.randn(16, 8,sbp=dist.get_nd_sbp([flow.sbp.split(0), flow.sbp.split(1)]),placement=dist.get_layer_placement(layer_idx=0))# 也可以换成以下的写法# self.noise_tensor = flow.randn(# 16, 8,# sbp=(flow.sbp.split(0), flow.sbp.split(1)),# placement=flow.placement("cuda", ranks=[[0, 1],[2, 3]])# )def forward(self, x):return x + self.noise_tensorNoise = Noise()x = flow.zeros(16, 8,sbp=(flow.sbp.split(0), flow.sbp.split(1)),placement=flow.placement("cuda", ranks=[[0, 1],[2, 3]]))y = Noise(x)print(f"rank: {flow.env.get_rank()}, global tensor: shape {y.shape} sbp {y.sbp} placement {y.placement}, local tensor shape: {y.to_local().shape}")
python3 -m oneflow.distributed.launch --nproc_per_node 4 test.pyrank: 2, global tensor: shape oneflow.Size([16, 8]) sbp (oneflow.sbp.split(axis=0), oneflow.sbp.split(axis=1)) placement oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]), local tensor shape: oneflow.Size([8, 4])rank: 3, global tensor: shape oneflow.Size([16, 8]) sbp (oneflow.sbp.split(axis=0), oneflow.sbp.split(axis=1)) placement oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]), local tensor shape: oneflow.Size([8, 4])rank: 1, global tensor: shape oneflow.Size([16, 8]) sbp (oneflow.sbp.split(axis=0), oneflow.sbp.split(axis=1)) placement oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]), local tensor shape: oneflow.Size([8, 4])rank: 0, global tensor: shape oneflow.Size([16, 8]) sbp (oneflow.sbp.split(axis=0), oneflow.sbp.split(axis=1)) placement oneflow.placement(type="cuda", ranks=[[0, 1], [2, 3]]), local tensor shape: oneflow.Size([8, 4])
LiBai 模型库地址:https://github.com/Oneflow-Inc/libai LiBai 文档地址:https://libai.readthedocs.io/en/latest OneFlow 项目地址:https://github.com/Oneflow-Inc/oneflow
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码