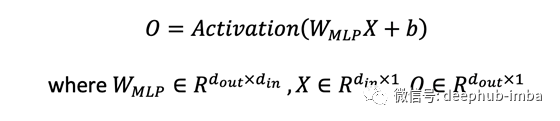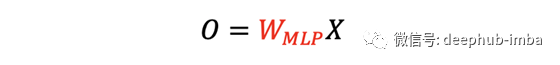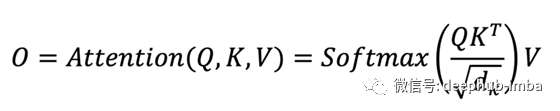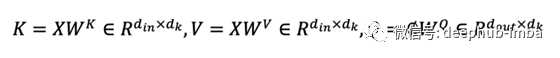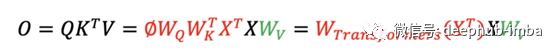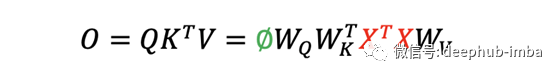本文约1800字,建议阅读5分钟
本文介绍在设计神经网络时如何解决张量整形的问题。
在设计神经网络时,我们经常遇到张量整形的问题。张量的空间形状必须通过改变某一层来适应下游的层。就像具有不同形状的顶面和底面的乐高积木一样,我们在神经网络中也需要一些适配器块。
改变张量形状的最常见方法是通过池化或跨步卷积(具有非单位步幅的卷积)。在计算机视觉中我们可以使用池化或跨步卷积将空间维度输入形状的 H x W 更改为 H/2 x W/2,甚至更改为不对称的 H/4 x W/8。要覆盖比简单缩放更复杂的变换,比如执行单应(homography),我们需要一些更灵活的东西。多层感知器(MLP)或Transformer是两个现成的解决方案。计算机视觉中使用的神经网络张量通常具有 NxHxWxC 的“形状”(批次、高度、宽度、通道)。这里我们将关注空间范围 H 和 W 中形状的变化,为简单起见忽略批次维度 N,保持特征通道维度 C 不变。我们将 HxW 粗略地称为张量的“形状”或“空间维度”。 在 pytorch 和许多其他深度学习库的标准术语中,“重塑”不会改变张量中元素的总数。在这里,我们在更广泛的意义上使用 重塑(reshape) 一词,其中张量中的元素数量可能会改变。
如何使用 MLP 和 Transformers 来重塑张量?
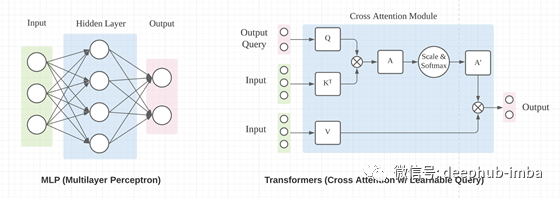
如果我们忽略内部处理的详细机制(MLP 中的隐藏层和 Transformers 中的交叉注意),MLP 和 Transformer 具有相似的输入和输出接口,如下图所示。使用 MLP 来改变输入张量的形状相对简单。对于只有一个全连接层的最简单形式的 MLP,从输入 X 到输出 O 的映射如下。
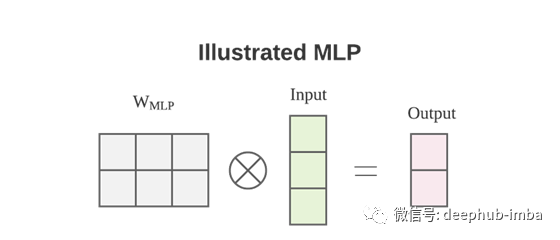
如果我们这里忽略激活函数和偏置b,本质是矩阵乘法,重塑过程完全被权重矩阵W捕获。张量重塑可以通过与W的左乘来实现。
我们在上面隐式假设特征通道维度C=1,张量格式为HWxC,忽略batch维度。这样我们就可以乘以 Input 左边的 W 矩阵来改变空间形状。
对于Transformers ,按照原始公式,我们有以下映射。
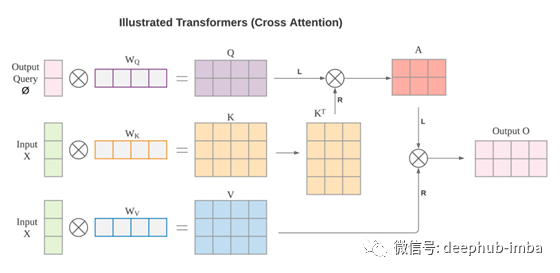
对于交叉注意力模块,在上面的等式中,K和V是线性投影的输入X,Q是线性投影的输出查询Ø。输出查询 Ø 与输出 O 具有相同的空间形状。Q、K 和 V 具有以下形状。
矩阵与投影矩阵W相乘的目的是将输入X和输出查询Ø提升到相同的特征维度。这里使用的是右乘法,这是与前面提到的MLP中的重塑操作不同的操作。如果我们忽略缩放因子和Softmax激活函数,我们有以下方程。
自注意力机制是 Transformers 原始论文中用于特征提取的亮点。但是,自注意力保持原始输入形状,因为输出查询也是自注意力模块中的输入 X。为了重塑输入张量,必须使用具有不同形状(所需输出形状)的输出查询。
与 MLP 相比,我们有非常相似的公式,都将输入与学习的加权矩阵 W 左乘以实现形状变化。但是,有两个不同之处。
- 输出 O 通过了一个额外的线性投影,将特征通道从 1 的输入提升到 d_k 的输出。
- Transformers 中的 W 矩阵取决于输入 X。
第一个区别相对微不足道,我们可以将 MLP 与一个额外的线性投影相匹配来改变特征通道。第二个有重大影响。我们将深入探讨 MLP 和 Transformer 的两种加权矩阵 W 之间的差异。区别1:数据依赖
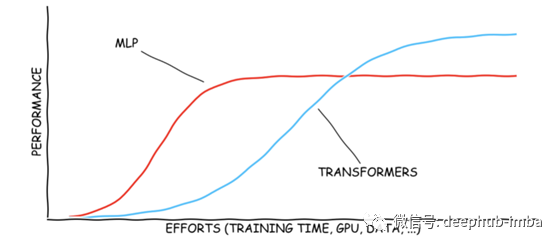
MLP 学习的 W 矩阵不依赖于输入数据,而 Transformers 则依赖于输入数据。MLP 的加权矩阵在训练期间学习推理期间是固定的。对于 Transformer 来说,权重矩阵的数据依赖可以看作是一种动态权重,它可以适应不同的输入。这可以使 Transformer 更具表现力,但也使 Transformer 比 MLP 更难训练。具体来说,对于固定的视图变换例如逆透视映射(IPM)或其他类型的单应性 ,MLP本质上只是学习输入和输出之间的固定映射。对于Transformer ,额外的输入数据可能会阻碍模型的初始收敛。需要在 GPU、数据和训练时间上做出重大努力,才能获得良好的性能。
区别2:输入顺序
对于 MLP,输入和输出的顺序被编码在矩阵 W 中。每一行和每一列对应于输入和输出形状的权重。MLP 不需要位置编码来帮助索引输入和输出。对于Transformers 就比较复杂了,对于输入的顺序是一个不变量(invariant ),先看看交叉注意力的方程如果X沿空间形状维进行某种排列,红色部分X^T X将保持不变,因此输出也保持不变。从另一个角度看,K和V是字典的键-值对,字典中的顺序无所谓,只要键值映射不变就行。交叉注意机制是建立在查询和关键字之间的相似性上,而不是建立在位置上。
对于自注意力(self-attention),其中输出查询Ø=X,那么O的顺序也经历了与输入X相同的排列。从数学上讲,自注意是排列等变(permutation equivariant)的,而交叉注意是排列不变(permutation invariant)的。注意机制不对位置信息进行编码的也正是位置编码 (PE) 需要为顺序重要的应用程序输入索引的原因。具体来说,在 NLP 应用中,“猫追狗”和“狗追猫”会导致词对之间的注意力完全相同,这显然是有问题的。上述交叉注意机制也常用于图神经网络(GNN)。它允许网络在训练期间从所有输入实例中捕获共同特征,因为查询独立于输入并且由所有输入实例共享。这是 GNN 的先驱之一 Thomas Kipf 的推文,他评论了自注意力模块的排列等效性。
总结
- MLP 和 Transformers(交叉注意力)都可以用于张量重塑。
- MLP 的重塑机制不依赖于数据,而 Transformers 则依赖于数据。这种数据依赖性使 Transformer 更难训练,但可能具有更高的上限。
- 注意力不编码位置信息。自注意力是排列等变的,交叉注意力是排列不变的。MLP 对排列高度敏感,随机排列可能会完全破坏 MLP 结果。
引用
- Attention is All you Need, NeurIPS 2017
- Mathematical properties of Attention in Transformers, Professor Shuiwang Ji’s class notes, TAMU