
【深度学习】基础知识 | 超详细逐步图解 Transformer
作者 | Chilia
整理 | NewBeeNLP
1. 引言
读完先修知识中的文章之后,你会发现:RNN由于其顺序结构训练速度常常受到限制,既然Attention模型本身可以看到全局的信息, 那么一个自然的疑问是我们能不能去掉RNN结构,仅仅依赖于Attention模型,这样我们可以使训练并行化,同时拥有全局信息?
你可能听说过不同的著名Transformer模型,如 BERT、GPT 和 GPT2。在这篇文章中,我们将精读谷歌的这篇 Attention is All you need[1] 论文来回顾一下仅依赖于Attention机制的Transformer架构。
在开始之前,先让我们看一个好玩的例子。Transformer可以根据你写的一句开头,写出一段科幻小说!
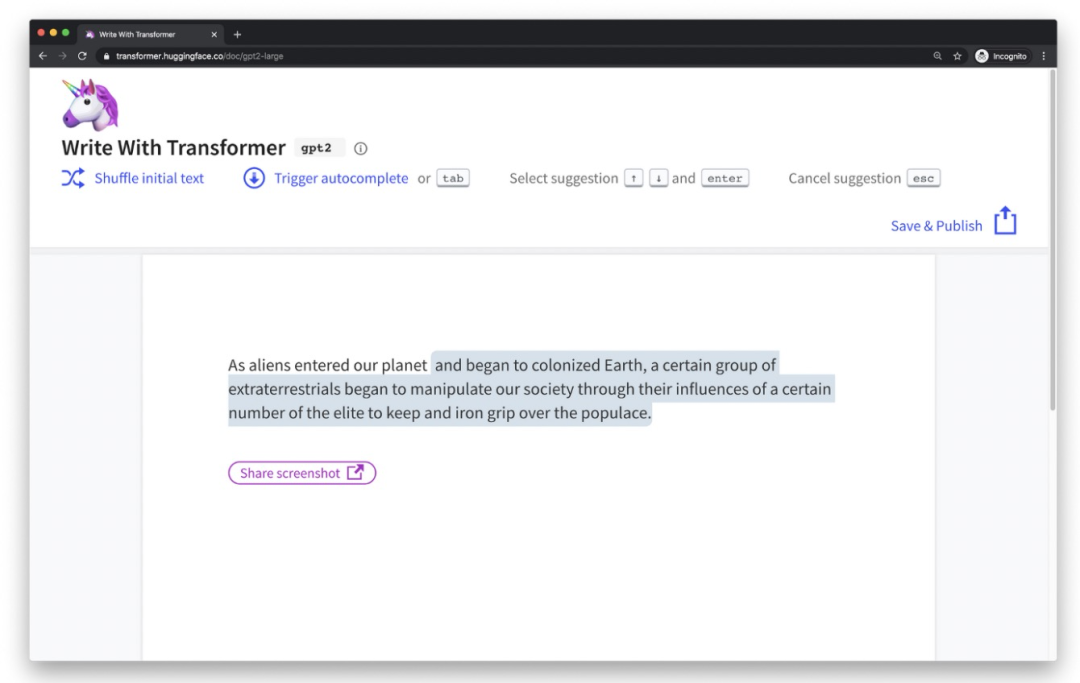
「输入:」 “As Aliens entered our planet”.
「Transformer输出:」 “and began to colonized Earth, a certain group of extraterrestrials began to manipulate our society through their influences of a certain number of the elite to keep and iron grip over the populace.”
这真是一个黑暗的故事...但有趣的是研究模型是如何生成这个黑暗故事的。当模型逐字生成文本时,它可以“关注”与生成的单词相关的单词(「attention」)。知道要关注哪些单词的能力也是在训练过程中通过反向传播学到的。

Transformer的优势在于,它可以不受梯度消失的影响,能够保留任意长的长期记忆。而RNN的记忆窗口很短;LSTM和GRU虽然解决了一部分梯度消失的问题,但是它们的记忆窗口也是有限的。
Recurrent neural networks (RNN) are also capable of looking at previous inputs too. But the power of the attention mechanism is that it doesn't suffer from short term memory. RNNs have a shorter window to reference from, so when the story gets longer, RNNs can't access words generated earlier in the sequence. This is still true for Gated Recurrent Units (GRU) and Long-short Term Memory (LSTM) networks, although they do a bigger capacity to achieve longer-term memory, therefore, having a longer window to reference from. The attention mechanism, in theory, and given enough compute resources, have an 「infinite」 window to reference from, therefore being capable of using the entire context of the story while generating the text.

2.Attention Is All You Need — Step by Step Walkthrough
2.1 总体结构
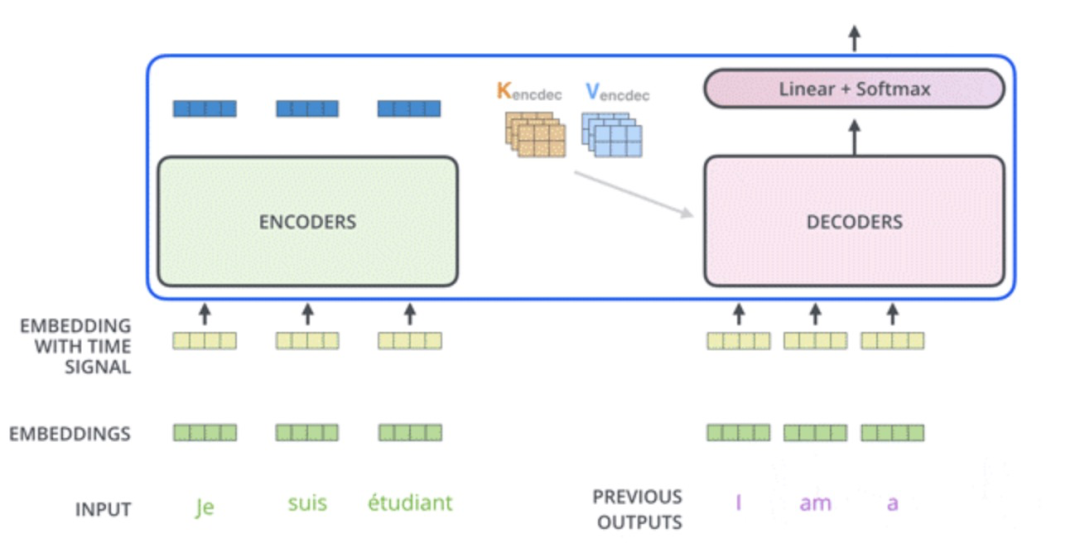
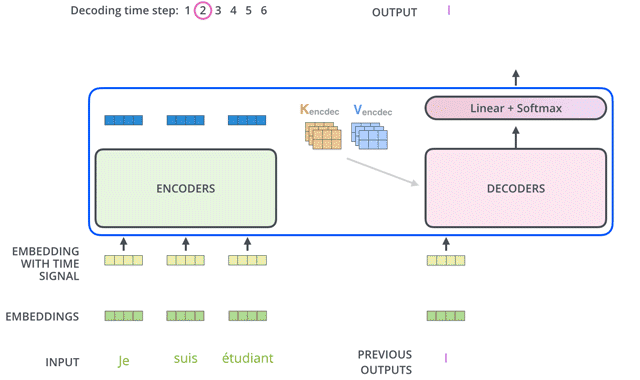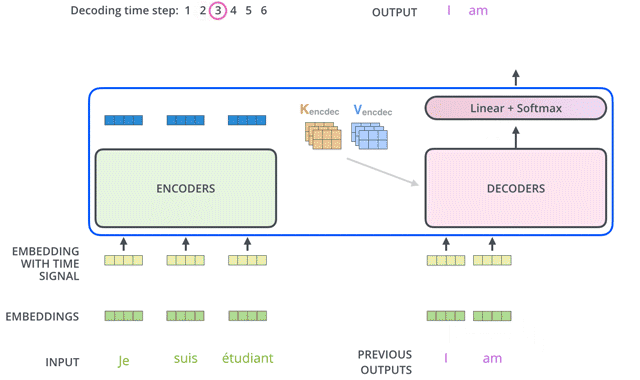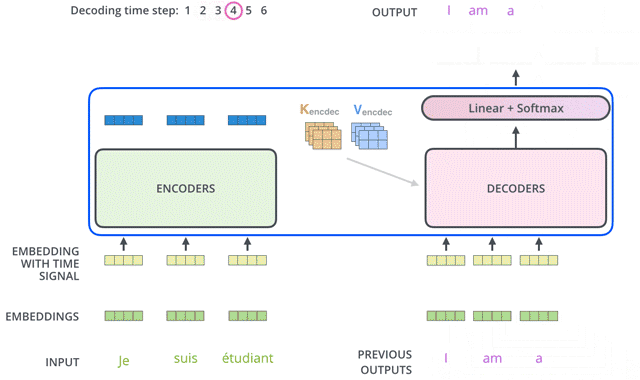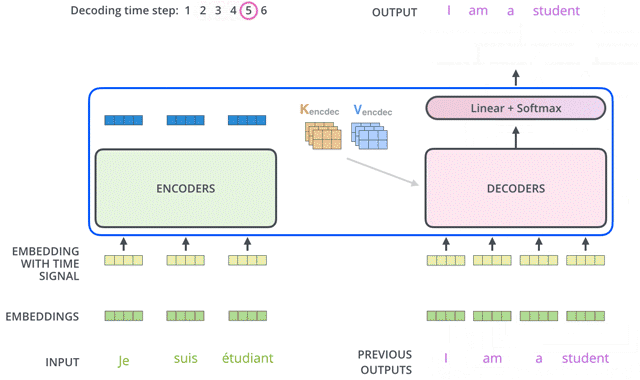
Transformer的结构也采用了 Encoder-Decoder 架构。但其结构更加复杂,论文中Encoder层由6个Encoder堆叠在一起,Decoder层也一样。
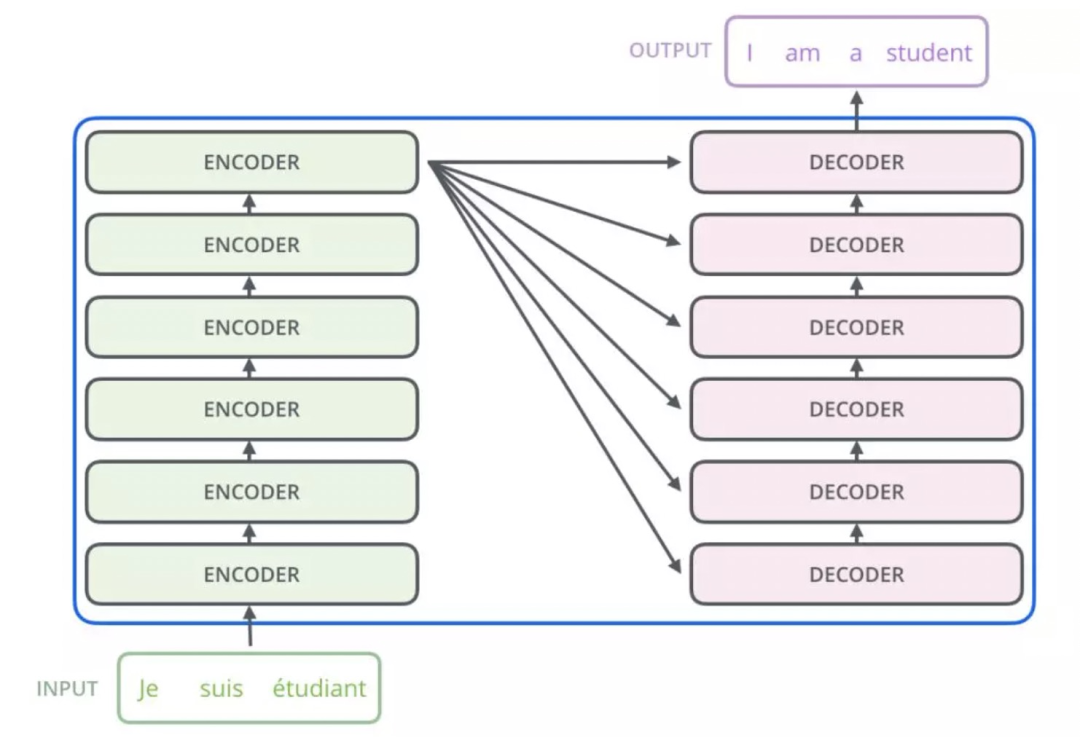
从整体来看,encoder将输入序列做了一个复杂的、使用了高阶信息的embedding;然后解码器采用该embedding,同时还根据之前的输出,一步一步地产生输出。
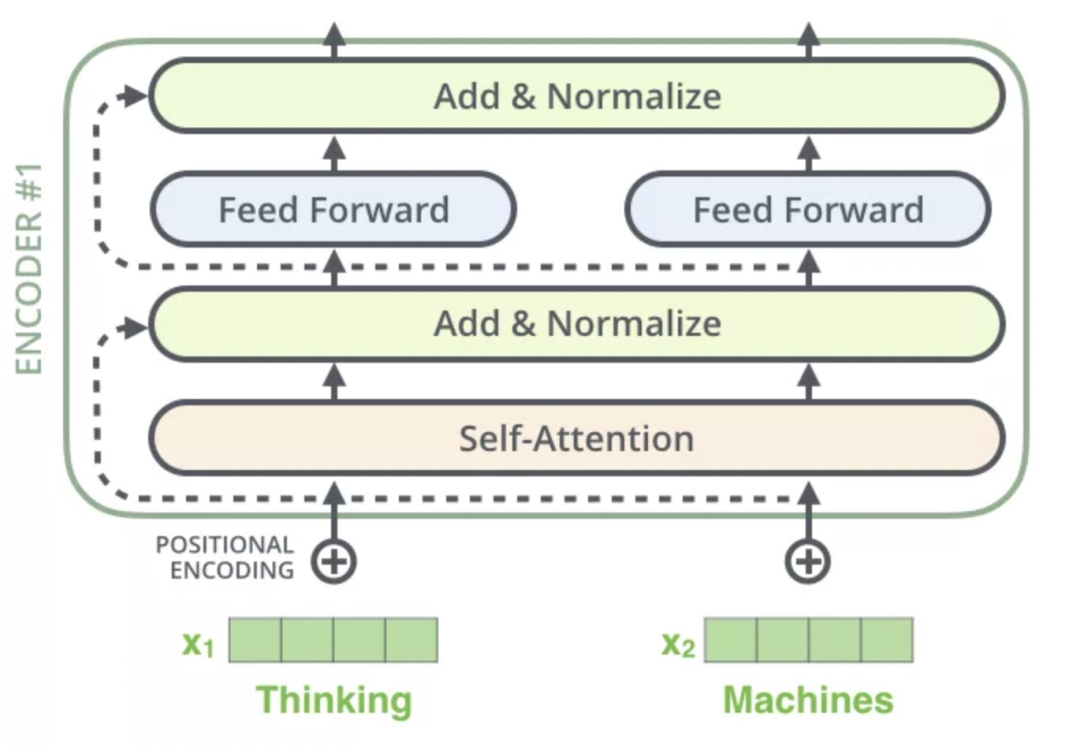
每一个Encoder和Decoder的内部结构如下图:
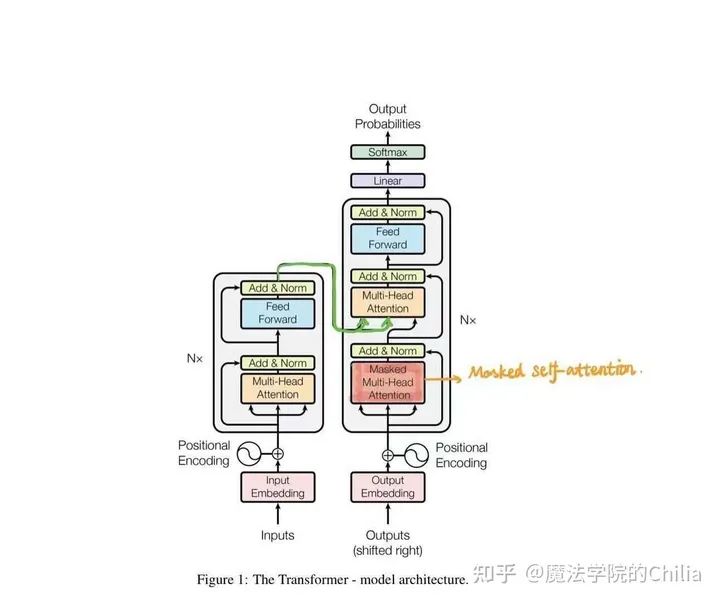
Encoder包含两层,一个Self-attention层(「Multi-Head Attention」)和一个前馈神经网络层(「feed forward」),Self-attention层能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。
Decoder也包含Encoder提到的两层网络,但是在这两层中间还有一层Attention层,帮助当前节点获取到当前需要关注的重点内容。
2.2 Encoder层详细说明
首先,模型需要对输入的数据进行一个embedding操作,并输入到Encoder层,Self-attention处理完数据后把数据送给前馈神经网络,前馈神经网络的计算可以「并行」,得到的输出会输入到下一个Encoder。大致结构如下:
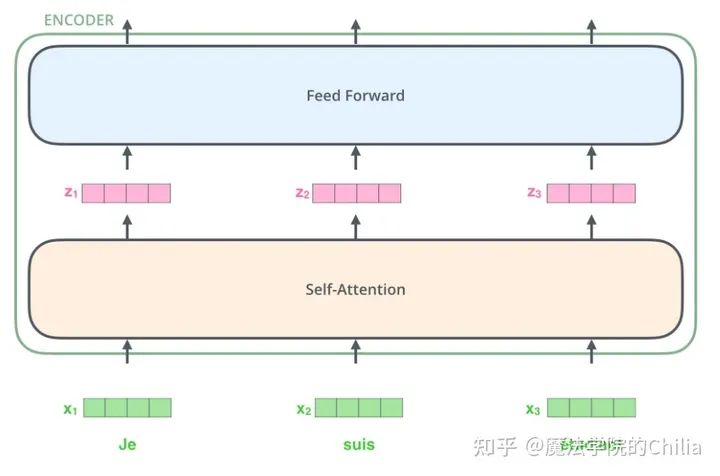
就是embedding, 是经过self-attention之后的输出, 是经过feed forward网络之后的输出,它们会被输入到下一层encoder中去。
2.2.1 Embedding层
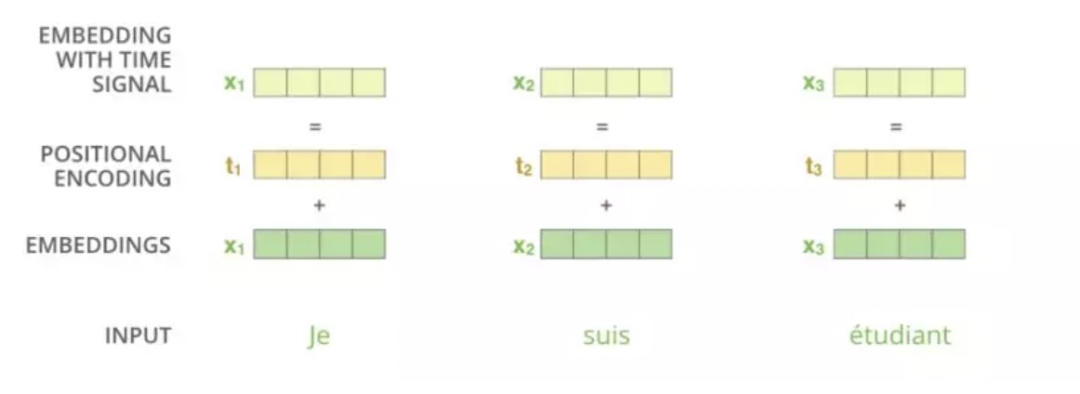
Transformer模型中缺少一种解释输入序列中单词「顺序」的方法,它跟序列模型还不一样。为了处理这个问题,Transformer给Encoder层和Decoder层的输入添加了一个额外的向量「Positional Encoding」,维度和embedding的维度一样。这个位置向量的具体计算方法有很多种,论文中的计算方法如下:
其中 pos 是指当前词在句子中的位置, 是指向量中每个值的 index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
所以,最终一个词的embedding,就是它的语义信息embedding(预训练模型查表)+序列信息embedding (positional encoding):
2.2.2 Self-attention层
让我们从宏观视角看自注意力机制,精炼一下它的工作原理。
例如,下列句子是我们想要翻译的输入句子:
The animal didn't cross the street because 「it」 was too tired.
这个“it”在这个句子是指什么呢?它指的是street还是这个animal呢?这对于人类来说是一个简单的问题,但是对于算法则不是。
当模型处理这个单词“it”的时候,自注意力机制会允许“it”与“animal”建立联系。
随着模型处理输入序列的每个单词,自注意力会「关注整个输入序列的所有单词」,帮助模型对本单词「更好地进行编码(embedding)」。

如上图所示,当我们在编码器#5(栈中最上层编码器)中编码“it”这个单词的时,注意力机制的部分会去关注“The Animal”,将它的表示的一部分编入“it”的编码中。接下来我们看一下Self-Attention详细的处理过程。
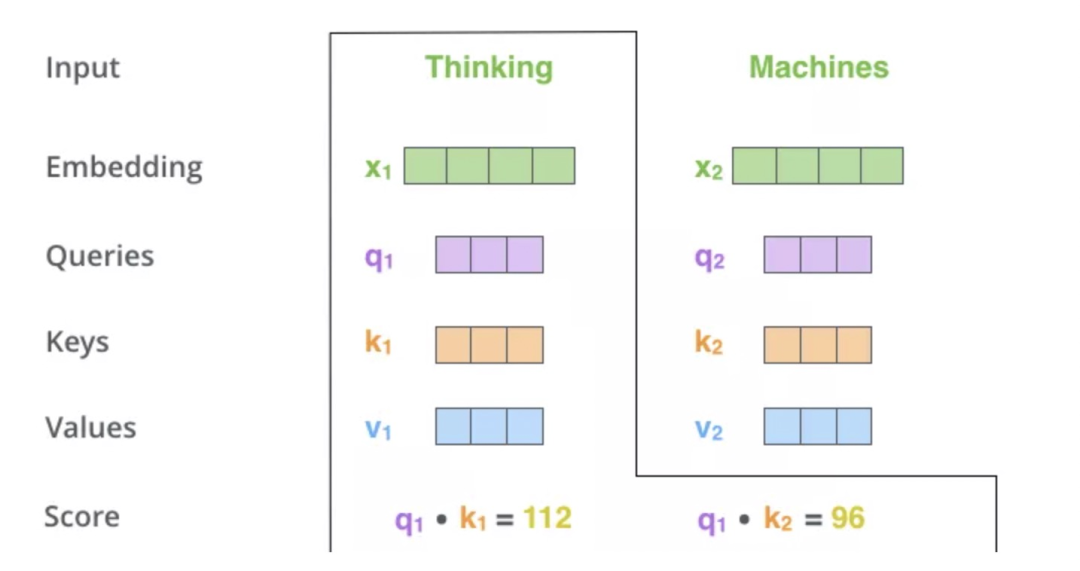
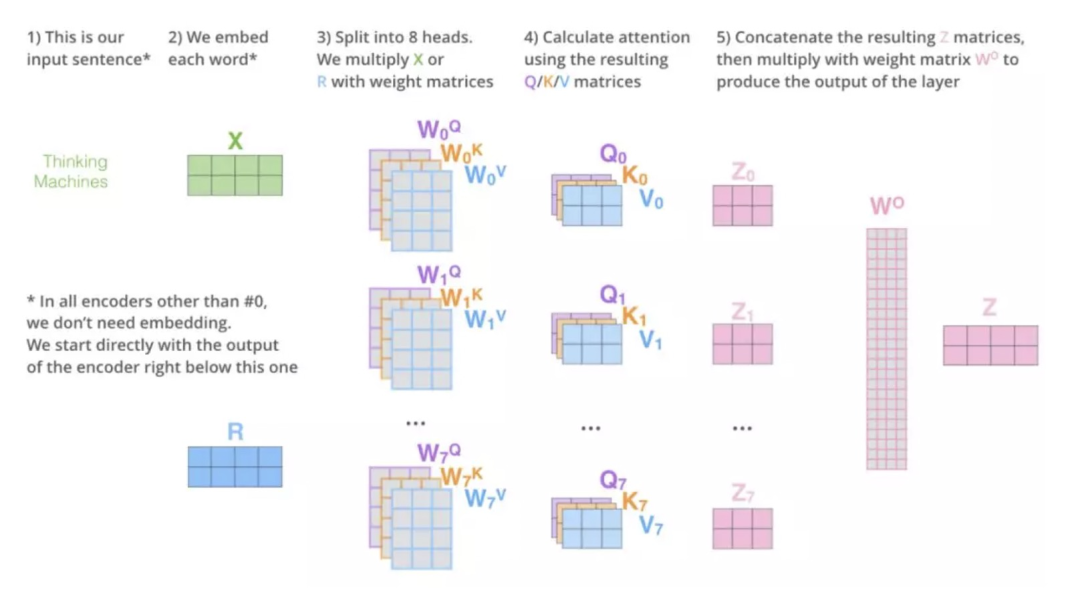
「step1:」 首先,对于输入序列的每个单词,它都有三个向量编码,分别为:Query、Key、Value。这三个向量是用embedding向量与三个矩阵( )相乘得到的结果。这三个矩阵的值在BP的过程中会一直进行更新。
「step2:」 第二步计算Self-Attention的分数值,该分数值决定了当我们在某个位置encode一个词时,对输入句子的其他部分的关注程度。这个分数值的计算方法是用该词语的Q与句子中其他词语的Key做点乘。以下图为例,假设我们在为这个例子中的第一个词“Thinking”计算自注意力向量,我们需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中重视句子其它部分的程度。
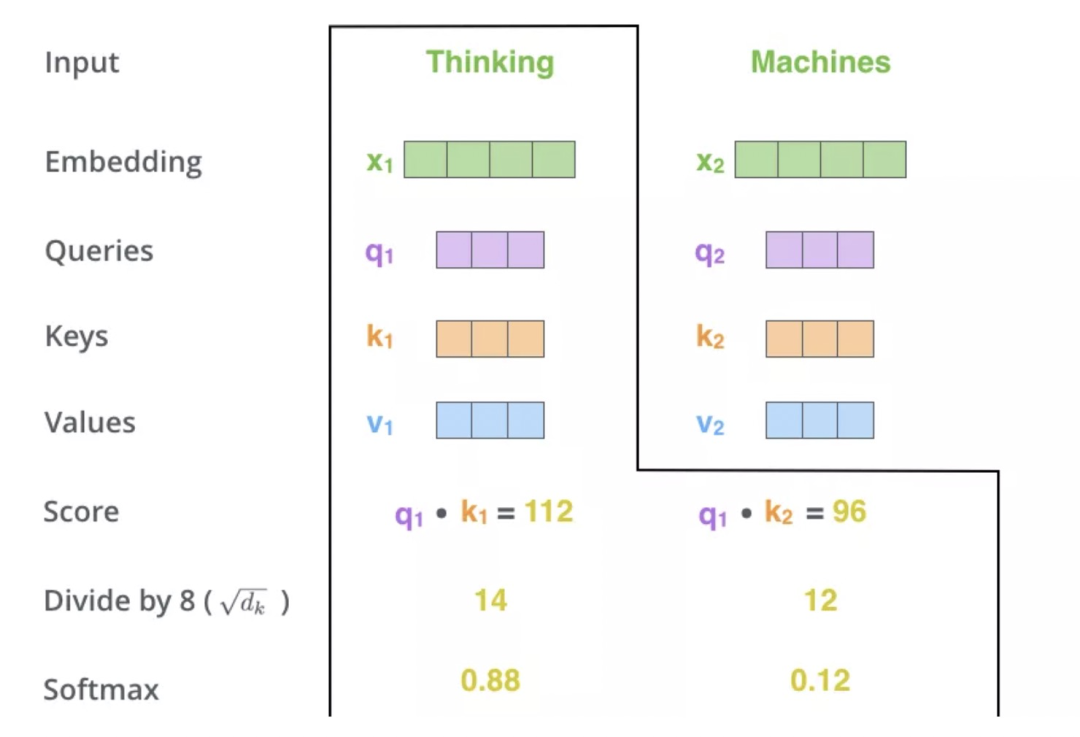
「step3:」 再对每个分数除以 (d是维度),之后做softmax。
「step4:」 把每个Value向量和softmax得到的值进行相乘,然后对相乘的值进行相加,得到的结果即是一个词语的self-attention embedding值。
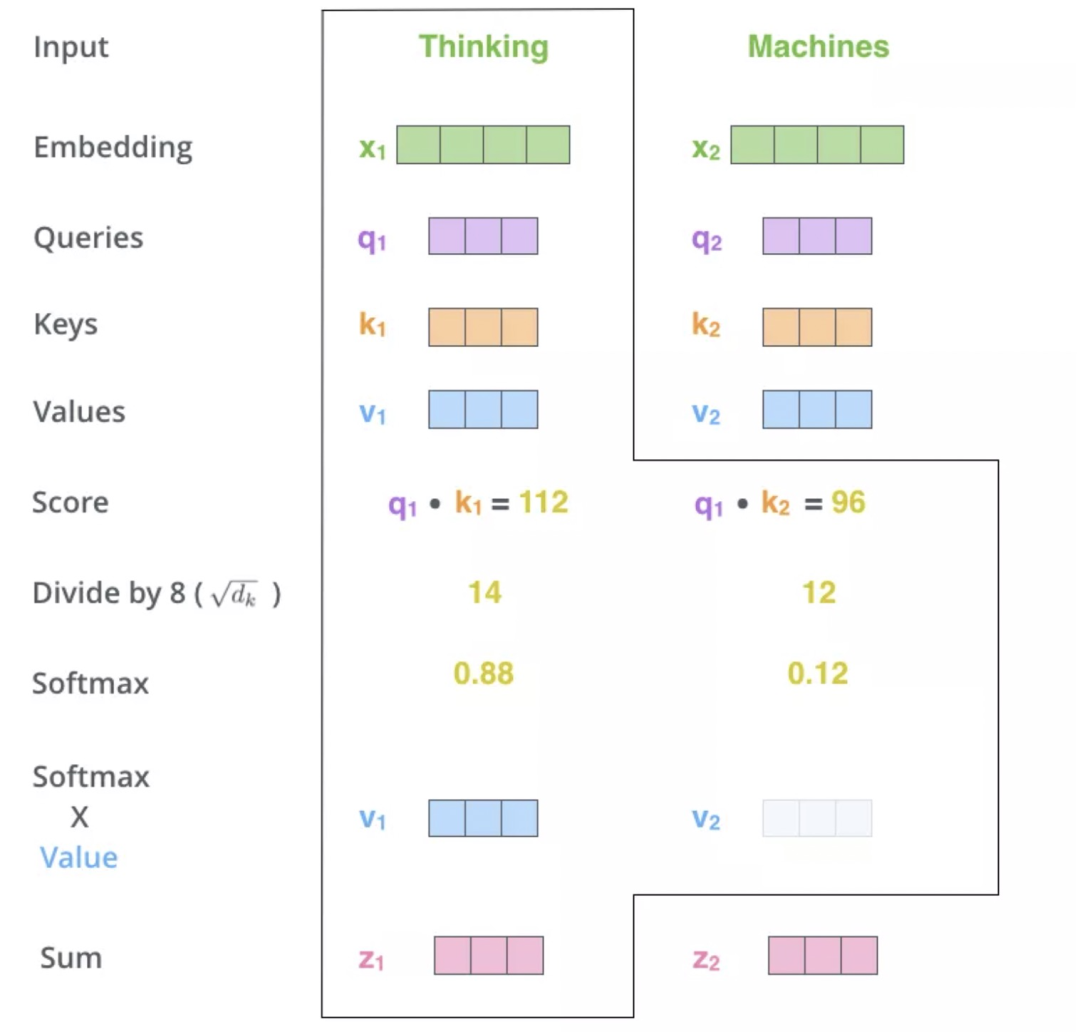
这样,自注意力的计算就完成了。得到的向量就可以传递给前馈神经网络。
2.2.3 Multi-Headed Attention
通过增加一种叫做"多头"注意力("multi-headed"attention)的机制,论文进一步完善了自注意力层。
接下来我们将看到,对于“多头”注意力机制,我们有多个Query/Key/Value权重矩阵集 (Transformer使用八个注意力头)。
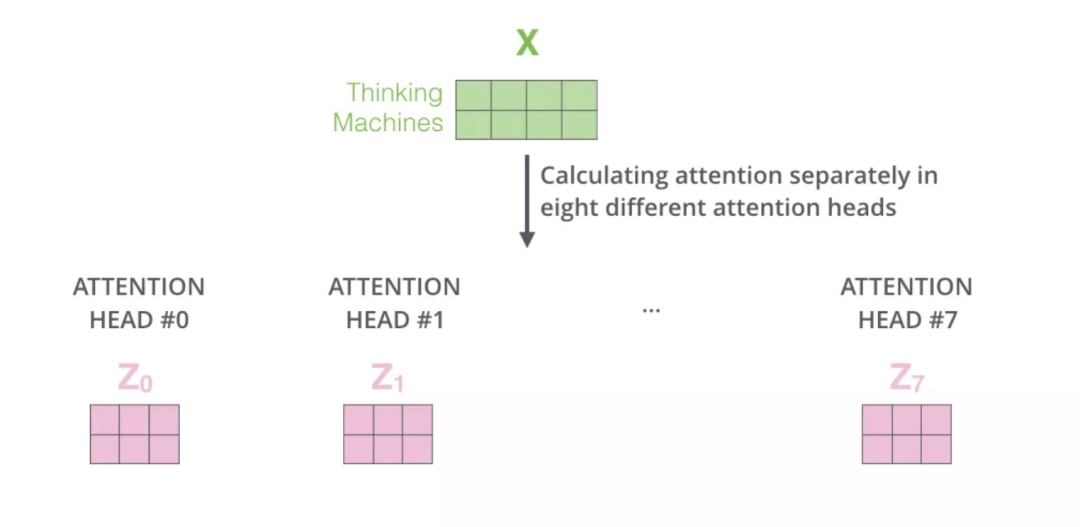
现在对于每一个词语,我们有了八个向量 ! ,它们分别由八个head产生。但是对于下一个feed-forward层,我们应该把每个词语都用一个向量来表示。所以下一步,我们需要把这八个向量压缩成一个向量。
可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵 与它们相乘:
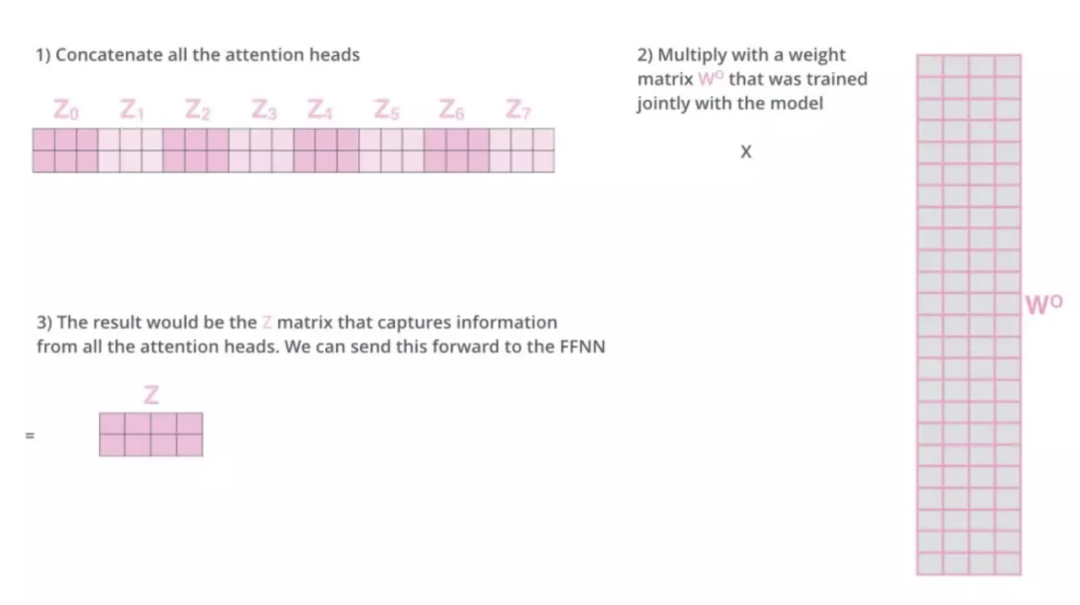
这几乎就是多头自注意力的全部。这确实有好多矩阵,我们试着把它们集中在一个图片中,这样可以一眼看清。
既然我们已经摸到了注意力机制的这么多“头”,那么让我们重温之前的例子,看看我们在例句中编码“it”一词时,不同的注意力“头”集中在哪里:

当我们编码“it”一词时,一个注意力头集中在“animal”上,而另一个则集中在“tired”上,从某种意义上说,模型对“it”一词的表达在某种程度上是“animal”和“tired”的代表。
2.2.4 The Residuals and Layer normalization
在继续进行下去之前,我们需要提到一个encoder中的细节:在每个encoder中都有一个残差连接,并且都跟随着一个Layer Normalization(层-归一化)步骤。
如果我们去「可视化」这些向量以及这个和自注意力相关联的layer-norm操作,那么看起来就像下面这张图描述一样:
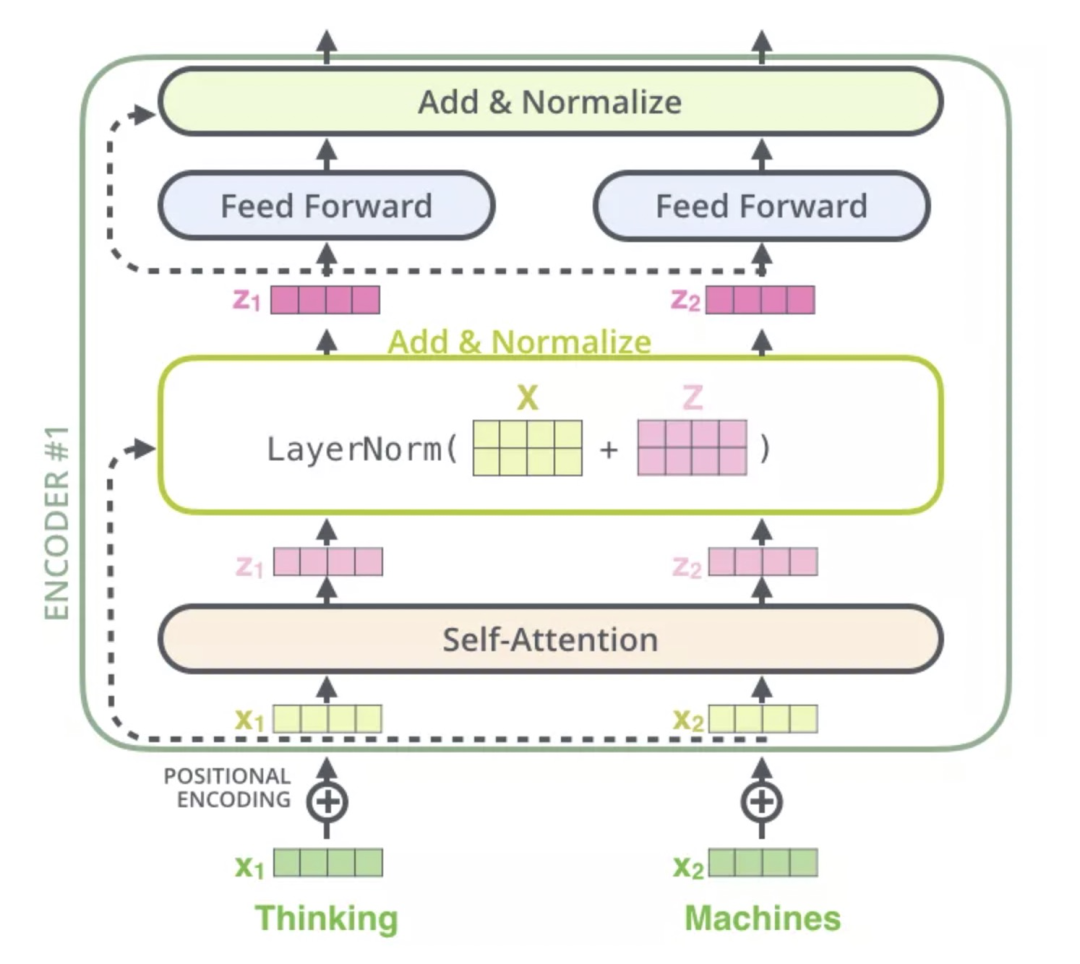
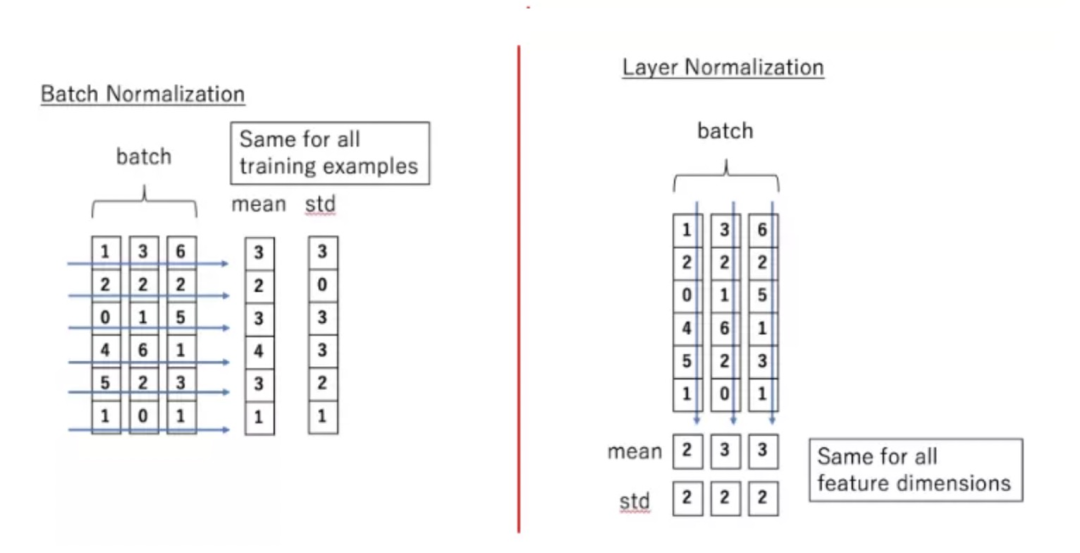
Layer-Norm也是归一化数据的一种方式,不过 Layer-Norm 是在每一个样本上计算均值和方差,而不是 Batch-Norm 那种在批方向计算均值和方差!
2.2.5 小结
这几乎就是Encoder的全部。Encoder就是用来给input一个比较好的embedding,使用self-attention来使一个词的embedding包含了上下文的信息,而不是简单的查look-up table。Transformer使用了多层(6层)的Encoder是为了把握一些高阶的信息。
2.3 Decoder层
2.3.1 简介
从更高的角度来看,Transformer的Decoder作用和普通seq2seq一样:从
以对话系统为例:
「Our Input:」 “Hi how are you”
「Transformer Output:」 “I am fine”
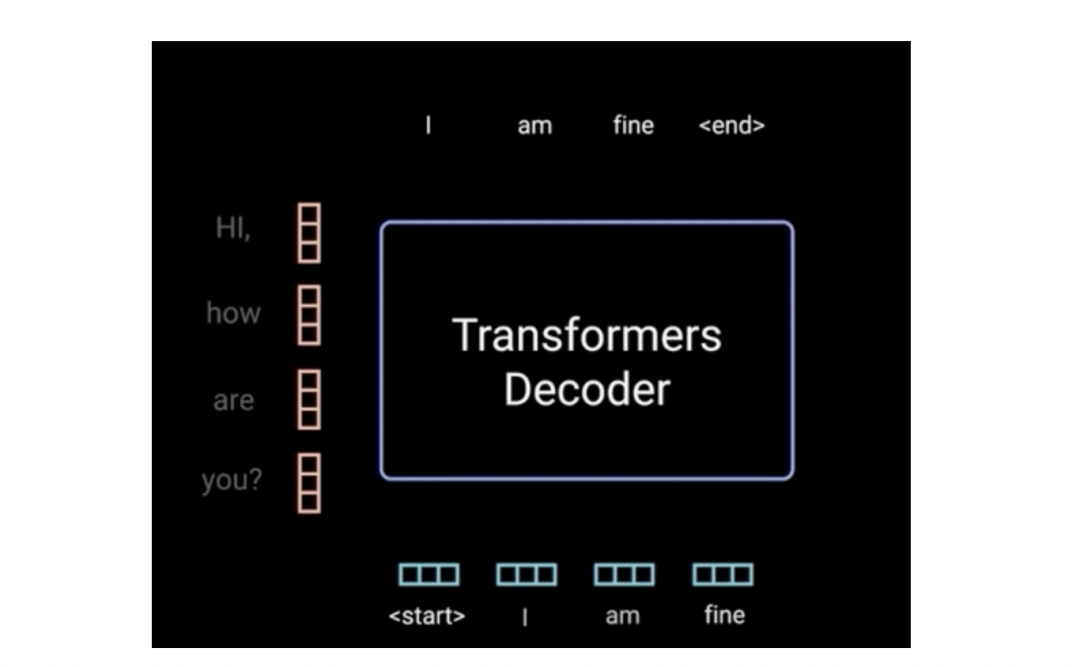
下面我们来详细介绍Decoder的内部结构。
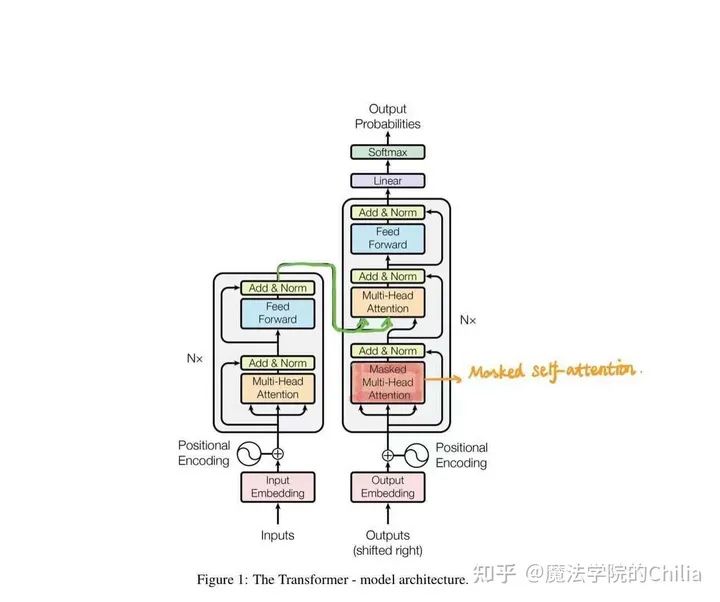
2.3.2 Masked Multi-Head Attention
和Encoder一样,Decoder先经过embedding+positional encoding之后得到了一个embedding,输入到multi-head attention中。
和前面不同的是,Decoder的self-attention层其实是「masked」 multi-head attention。mask表示掩码,它对某些值进行掩盖。这是为了防止Decoder在计算某个词的attention权重时“看到”这个词后面的词语。
Since the decoder is auto-regressive and generates the sequence word by word, you need to prevent it from conditioning to future tokens. For example, when computing attention scores on the word "am", you should not have access to the word "fine", because that word is a future word that was generated after. The word "am" should only have access to itself and the words before it. This is true for all other words, where they can only attend to previous words.

「Look-head mask」 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的「解码」输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为 「-inf」 。把这个矩阵加在每一个序列上,就可以达到我们的目的:

加上-inf的目的是,做softmax之后-inf会变成0:
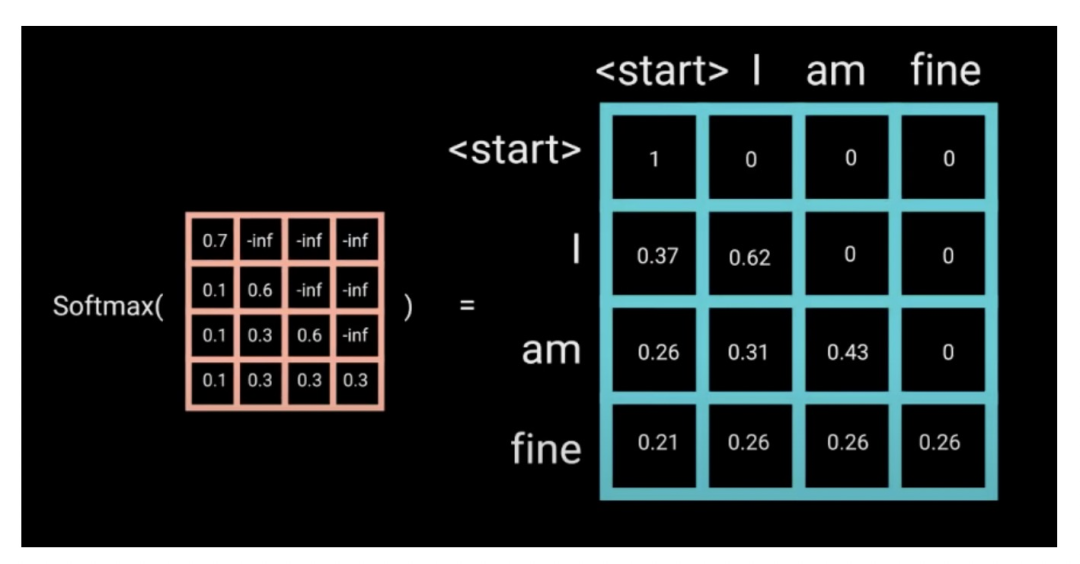
这个mask是Decoder中self-attention和Encoder中的self-attention唯一有区别的地方。
2.3.3 第二个Multi-head Attention -- 普通attention
For this layer, the encoder's outputs are keys and values, and the first multi-headed attention layer outputs are the queries. This process matches the encoder's input to the decoder's input, allowing the decoder to decide which encoder input is relevant to put a focus on.
3. Q/A
(1) Transformer为什么需要进行Multi-head Attention?
原论文中说进行Multi-head Attention的原因是将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。其实直观上也可以想到,如果自己设计这样的一个模型,必然也不会只做一次attention,多次attention综合的结果至少能够起到增强模型的作用,也可以「类比CNN中同时使用多个卷积核的作用」,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
(2) Transformer相比于RNN/LSTM,有什么优势?
RNN系列的模型,「并行计算」能力很差,因为 T 时刻的计算依赖 T-1 时刻的隐层计算结果。 Transformer的特征抽取能力也比RNN系列的模型要好,使用了self-attention和多头机制来让源序列和目标序列自身的embedding表示所蕴含的信息更加丰富。
(3)Transformer如何并行化的?
Transformer的并行化我认为主要体现在self-attention模块。对于某个序列 ,self-attention模块可以直接计算 的点乘结果,而RNN系列的模型就必须按照顺序从 计算到 .
本文参考资料
Attention is All you need: https://arxiv.org/abs/1706.03762
[2]Illustrated Guide to Transformers- Step by Step Explanation: https://towardsdatascience.com/illustrated-guide-to-transformers-step-by-step-explanation-f74876522bc0
[3]Self-Attention 与 Transformer: https://www.6aiq.com/article/1584719677724
- END -
往期精彩回顾 本站qq群554839127,加入微信群请扫码: