
PostgreSQL 和 MySQL 之间的性能差异
导读:在本文中,我们将讨论工作负载分析和运行查询,一起了解两个数据库系统在 JSON、索引和并发方面的性能差异。

简介
在管理数据库时,性能是一项非常重要而又复杂的任务。它可能会受到系统的配置、硬件甚至设计的影响。有趣的是,PostgreSQL和MySQL都配置了兼容性和稳定性,这取决于我们的数据库设计的硬件基础架构。
虽然PostgreSQL(或Postgres)和MySQL有一些相似之处,但它们也有独特的特性,在特定情况下,其中一个会更优秀。在表现方面,他们有很多不同。
在本文中,我们将讨论工作负载分析和运行的查询。然后,我们将进一步解释一些基本配置,以改进MySQL和PostgreSQL数据库的性能。之后,我们将概述MySQL和PostgreSQL之间的一些关键区别。
如何衡量性能
MySQL作为快速读取大量工作负载的数据库而享有盛誉,尽管在与写入操作混合使用时经常牺牲并发性。
PostgreSQL(俗称Postgres)将自己展示为最先进的开源关系数据库,并且已开发为符合标准且功能丰富的数据库。
以前,Postgres的性能更加平衡,即,读取通常比MySQL慢,但后来它得到了改进,现在可以更有效地写入大量数据,从而使并发处理更好。MySQL和Postgres的最新版本略微消除了两个数据库之间的性能差异。
在MySQL中使用旧的MyISAM 引擎可以非常快速地读取数据。不幸的是,在最新版本的MySQL中尚不可用。但是,如果使用InnoDB(允许关键约束,事务),则差异可以忽略不计。这些功能对于企业或消费者规模的应用程序至关重要,因此不能选择使用旧引擎。好消息是,MySQL不断得到改进,以减少大量数据写入之间的差异。
甲数据库基准是用于表征和比较的性能(时间,存储器,或质量)可再现的试验框架数据库在这些系统上的系统或算法。这种实用的框架定义了被测系统,工作量,指标和实验。
在接下来的4部分中,我们将概述MySQL和PostgreSQL之间的一些关键区别。
JSON查询在Postgres中更快
在本节中,我们将看到PostgreSQL和MySQL之间的基准测试差异。
执行的步骤
创建一个项目(Java,Node或Ruby),其中使用的DB是PostgreSQL和MySQL。
创建一个示例JSON对象以执行WRITE和READ操作。
整个JSON对象的大小假定为〜14 MB,在数据库中创建约200–210个条目。
统计数据
PostgreSQL:平均时间(毫秒):写:2279.25 | 阅读:31.65 | 更新:26.26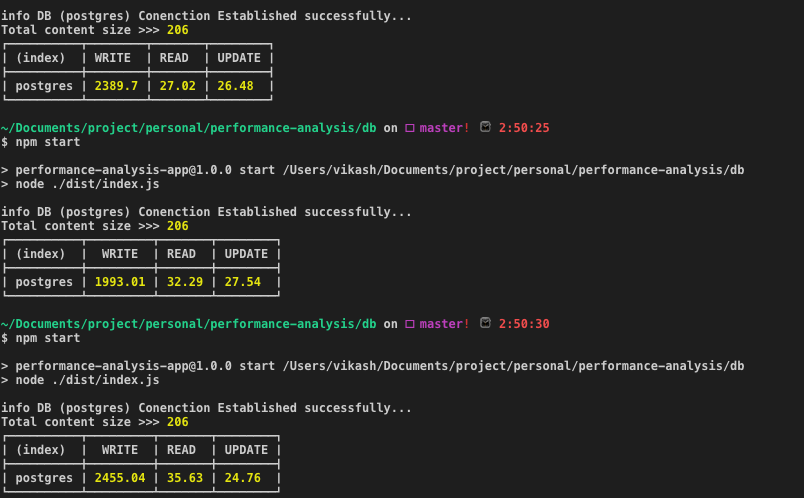
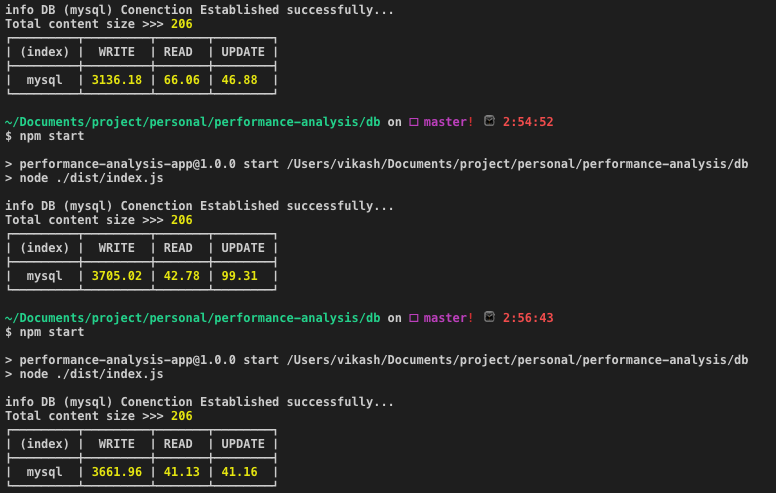
MySQL:平均时间(以毫秒为单位):写:3501.05 | 阅读:49.99 | 更新:62.45
指标
索引是所有数据库中的关键因素。它提高了数据库性能,因为它允许数据库服务器查找和检索特定行比没有索引快得多。但是,索引整体上给数据库系统增加了特殊的开销,因此应该明智地使用它们。如果没有索引,则数据库服务器将从第一行开始,然后通读整个表以找到相关的行:表越大,操作成本就越高。PostgreSQL和MySQL都有处理索引的特定方法。
标准B树索引:PostgreSQL包括对常规B树索引和哈希索引的内置支持。PostgreSQL中的索引还支持以下功能:
表达式索引:可以使用表达式或函数结果的索引而不是列的值来创建。
部分索引:仅索引表的一部分。
让我们假设我们在PostgreSQL中有一个名为users的表,其中表中的每一行代表一个用户。该表定义如下。CREATE TABLE users ( id SERIAL PRIMARY KEY, email VARCHAR DEFAULT NULL, name VARCHAR); 现在,让我们假设我们在上表中创建以下索引。

上面显示的两个索引有什么区别?第一索引#1是部分索引,而索引#2是表达式索引。如PostgreSQL文档所述,
“部分索引建立在由条件表达式定义的表中的行的子集上(称为部分索引的谓词)。索引仅包含满足谓词的那些表行的条目。使用局部索引的主要原因是避免索引常见的值。由于查询通常会出现的值(占所有表行百分之几的查询)无论如何都会遍历大多数表,因此使用索引的好处是微不足道的。更好的策略是创建部分索引,其中这些行完全排除在外。部分索引减少了索引的大小,因此加快了使用索引的查询的速度。它还将加快许多写入操作的速度,因为不需要在所有情况下都更新索引”-部分索引的文档-Postgres Docs。
MySQL:大多数MySQL索引(PRIMARY KEY,UNIQUE,INDEX和FULLTEXT)都位于B树中。例外包括使用R树的空间数据类型的索引。MySQL还支持哈希索引,而InnoDB引擎对FULLTEXT索引使用倒排列表。
数据库复制
涉及到PostgreSQL和MySQL的另一个性能差异是复制。复制是将数据从一个数据库服务器复制到另一台服务器上的另一数据库的能力。信息的这种分布意味着用户现在可以访问数据而不会直接影响其他用户。数据库复制的困难任务之一是协调整个分布式系统中的数据一致性。MySQL和PostgreSQL提供了几种可能的数据库复制选项。除了一个主服务器,一个备用数据库和多个备用数据库之外,PostgreSQL和MySQL还提供以下复制选项:
多版本并发控制
当用户同时读写数据库时,这种现象称为并发。因此,多个客户端同时读取和写入会导致各种边缘情况/竞赛条件,即,对于相同的记录X和许多其他条件,先读取后写入。各种现代数据库都利用事务来减轻并发问题。
Postgres是第一个推出多版本并发控制(MVCC)的DBMS,这意味着读取永远不会阻止写入,反之亦然。此功能是企业偏爱Postgres而不是MySQL的主要原因之一。
“与大多数其他使用锁进行并发控制的数据库系统不同,Postgres通过使用多版本模型来维护数据一致性。此外,在查询数据库时,每个事务都会看到一段时间的数据快照(数据库版本)。以前,无论基础数据的当前状态如何,它都可以保护事务避免查看由同一数据行上的(其他)并发事务更新引起的不一致数据,从而为每个数据库会话提供事务隔离。” 多版本并发控制” — PostgreSQL文档
MVCC允许多个读取器和写入器同时与Postgres数据库进行交互,从而避免了每次有人与数据进行交互时都需要读写锁的情况。附带的好处是此过程可显着提高效率。MySQL 利用InnoDB存储引擎,支持同一行的写和读,以免彼此干扰。MySQL每次将数据写入一行时,也会将一个条目写入回滚段。此数据结构存储用于将行恢复到其先前状态的“撤消日志”。之所以称为“回滚段”,是因为它是用于处理回滚事务的工具。
“ InnoDB是一个多版本存储引擎:它保留有关已更改行的旧版本的信息,以支持诸如并发和回滚之类的事务功能。该信息存储在表空间中称为回滚段的数据结构中(在类似数据之后)。InnoDB使用回滚段中的信息来执行事务回滚中所需的撤消操作。它还使用该信息来构建行的早期版本以实现一致的读取。” - InnoDB的多版本- MySQL的MVCC
结论
在本文中,我们处理了PostgreSQL和MySQL之间的一些性能差异。重要的是要注意,数据库性能取决于其他几个因素,例如硬件,操作系统类型,最重要的是,您对目标数据库的理解。PostgreSQL和MySQL都有其独特的特质和缺点,但是了解什么功能适合项目并集成这些功能最终会提高性能。
我很想听听您在数据库性能方面的经验。
作者:Blessing Krofegha
来源:https://dzone.com/articles/performance-differences-between-postgres-and-mysql
推荐阅读: