
三个优秀的语义分割框架 PyTorch实现

【导语】
本文基于动手深度学习项目讲解了FCN进行自然图像语义分割的流程,并对U-Net和Deeplab网络进行了实验,在Github和谷歌网盘上开源了代码和预训练模型,训练和预测的脚本已经做好封装,读者可以自行下载使用。

1 前言
Colab pro,大家下载模型做预测即可。下载VOC数据集,将 JPEGImagesSegmentationClass两个文件夹放入到data文件夹下。终端切换到目标目录,运行 python train.py -h查看训练
(torch) qust116-jq@qustx-X299-WU8:~/语义分割$ python train.py -h
usage: train.py [-h] [-m {Unet,FCN,Deeplab}] [-g GPU]
choose the model
optional arguments:
-h, --help show this help message and exit
-m {Unet,FCN,Deeplab}, --model {Unet,FCN,Deeplab}
输入模型名字
-g GPU, --gpu GPU 输入所需GPU
python train.py -m Unet -g 0预测需要手动修改 predict.py中的模型
d2l(动手学深度学习)的讲解到最后一部分。2 数据集


全卷积网络将中间层特征图的高和宽变换回输入图像的尺寸:这是通过中引入的转置卷积(transposed convolution)层实现的。因此,输出的类别预测与输入图像在像素级别上具有一一对应关系:给定空间维上的位置,通道维的输出即该位置对应像素的类别预测。%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
3.1 网络结构

pretrained_net。该模型的最后几层包括全局平均汇聚层和全连接层,然而全卷积网络中不需要它们。pretrained_net = torchvision.models.resnet18(pretrained=True)
list(pretrained_net.children())[-3:]
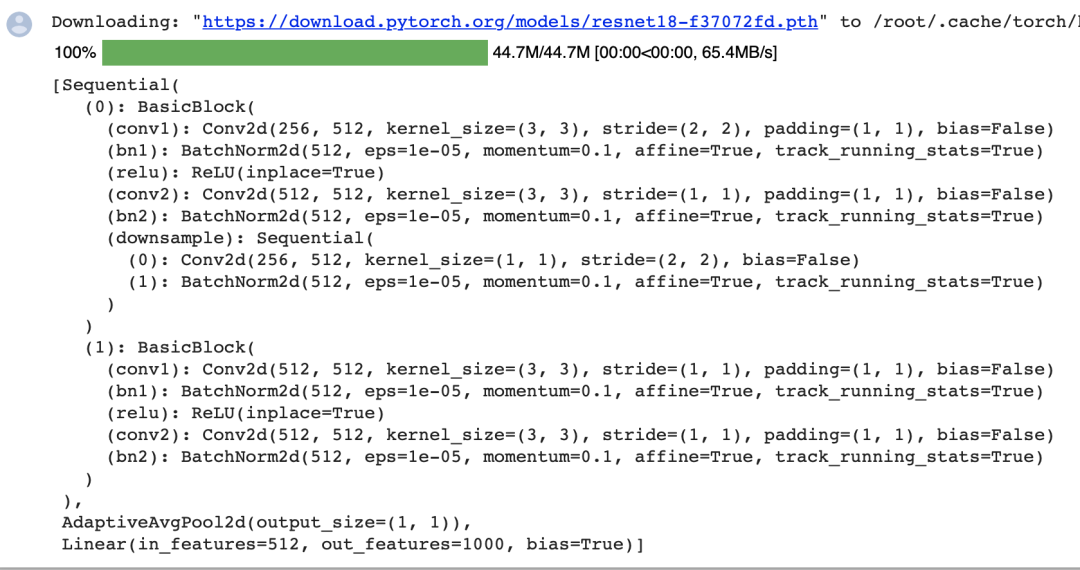
net。它复制了Resnet-18中大部分的预训练层,但除去最终的全局平均汇聚层和最接近输出的全连接层。net = nn.Sequential(*list(pretrained_net.children())[:-2])
net的前向计算将输入的高和宽减小至原来的,即10和15。X = torch.rand(size=(1, 3, 320, 480))
net(X).shape

num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes, num_classes,
kernel_size=64, padding=16, stride=32))
3.2 初始化转置卷积层
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
filt = (1 - torch.abs(og[0] - center) / factor) * \
(1 - torch.abs(og[1] - center) / factor)
weight = torch.zeros((in_channels, out_channels,
kernel_size, kernel_size))
weight[range(in_channels), range(out_channels), :, :] = filt
return weight
conv_trans = nn.ConvTranspose2d(3, 3, kernel_size=4, padding=1, stride=2,
bias=False)
conv_trans.weight.data.copy_(bilinear_kernel(3, 3, 4));
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W);
3.3 训练
def loss(inputs, targets):
return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
4 开源代码和Dataset



!python3 train.py -m Unet -g 0


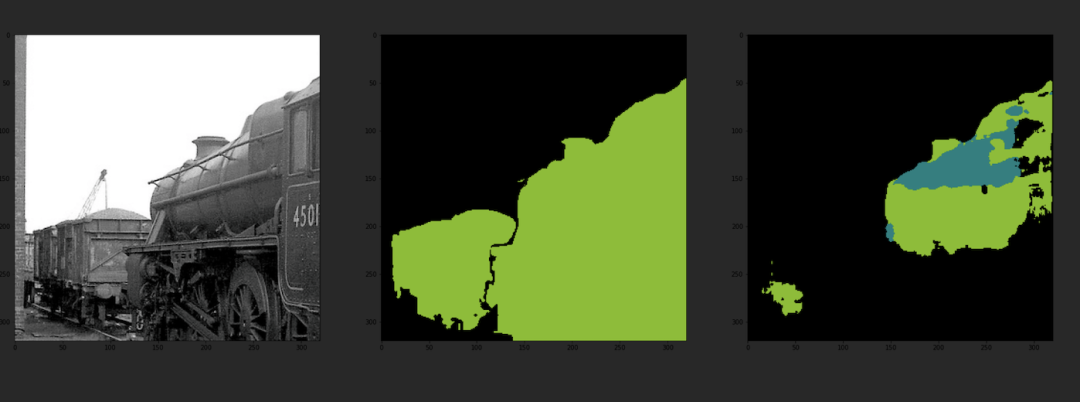
5 总结
6 参考
——The End——

推荐阅读
深度学习attention机制中的Q,K,V分别是从哪来的?
觉得有用,麻烦给个赞和在看~ 
评论