
【CV】语义分割:最简单的代码实现!
分割对于图像解释任务至关重要,那就不要落后于流行趋势,让我们来实施它,我们很快就会成为专业人士!
什么是语义分割?
它描述了将图像的每个像素与类别标签(例如花、人、道路、天空、海洋或汽车)相关联的过程,即我们要输入图像,然后为该图像中的每个像素输出一个类别决策。例如下面这个输入图像,这是一只坐在床上的狗:

因此,在输出中,我们希望为每个像素定义一组类别,即狗、床、后面的桌子和橱柜。在语义分割之后,图像看起来像这样:

关于语义分割的一件有趣的事情是它不区分实例,即如果此图像中有两只狗,它们将仅被描述为一个标签,即 dog ,而不是 dog1 和 dog2。
语义分割一般用于:
自动驾驶
工业检验
卫星图像中值得注意的区域分类
医学影像监查
语义分割实现:
第一种方法是滑动窗口,我们将输入图像分解成许多小的局部图像,但是这种方法在计算上会很昂贵。所以,我们在实践中并没有真正使用这个方法。
另一种方法是完全卷积网络,其中网络有一整堆卷积层,没有完全连接的层,从而保留了输入的空间大小,这在计算上也是极其昂贵的。
第三个也是最好的一个方法,那就是对图像进行上采样和下采样。因此,我们不需要对图像的完整空间分辨率进行所有卷积,我们可能会在原始分辨率下遍历少量卷积层,然后对该特征图进行下采样,然后对其进行上采样。
在这里,我们只想在网络的后半部分提高我们预测的空间分辨率,以便我们的输出图像现在可以与我们的输入图像具有相同的维度。它的计算效率要高得多,因为我们可以使网络非常深,并以更便宜的空间分辨率运行。

让我们在代码中实现这一点:
导入处理所需的必要库,即
Pytorch 的重要功能,例如数据加载器、变量、转换和优化器相关函数。
导入 VOC12 和 cityscapes 的数据集类,从 transform.py 文件导入 Relabel、ToLabel 和 Colorize 类,从 iouEval.py 文件中导入 iouEval 类。
#SSCV IIITH 2K19import randomimport timeimport numpy as npimport torchprint(torch.__version__)import mathfrom PIL import Image, ImageOpsfrom torch.optim import SGD, Adam, lr_schedulerfrom torch.autograd import Variablefrom torch.utils.data import DataLoaderfrom torchvision.transforms import Resizefrom torchvision.transforms import ToTensor, ToPILImagefrom dataset import cityscapesfrom dataset import idd_liteimport sysprint(sys.executable)from transform import Relabel, ToLabel, Colorizeimport matplotlibfrom matplotlib import pyplot as plt%matplotlib inlineimport importlibfrom iouEval import iouEval, getColorEntry #importing iouEval class from the iouEval.py filefrom shutil import copyfile
定义几个全局参数:
NUM_CHANNELS = 3 #RGB ImagesNUM_CLASSES = 8 #IDD Lite has 8 labels or Level1 hierarchy of labelsUSE_CUDA = torch.cuda.is_available()IMAGE_HEIGHT = 160DATA_ROOT = ‘/tmp/school/6-segmentation/user/1/6-segmentation/idd1_lite’BATCH_SIZE = 2NUM_WORKERS = 4NUM_EPOCHS = 100ENCODER_ONLY = Truedevice = torch.device(“cuda” )#device = ‘cuda’color_transform = Colorize(NUM_CLASSES)image_transform = ToPILImage()IOUTRAIN = FalseIOUVAL = True
增强,即对图像和目标执行随机增强的不同功能:
class MyCoTransform(object):def __init__(self, enc, augment=True, height=160):self.enc=encself.augment = augmentself.height = heightpassdef __call__(self, input, target):# Resizing data to required sizeinput = Resize((self.height,320), Image.BILINEAR)(input)target = Resize((self.height,320), Image.NEAREST)(target)if(self.augment):# Random horizontal fliphflip = random.random()if (hflip < 0.5):input = input.transpose(Image.FLIP_LEFT_RIGHT)target = target.transpose(Image.FLIP_LEFT_RIGHT)#Random translation 0–2 pixels (fill rest with padding)transX = random.randint(0, 2)transY = random.randint(0, 2)input = ImageOps.expand(input, border=(transX,transY,0,0), fill=0)target = ImageOps.expand(target, border=(transX,transY,0,0), fill=7) #pad label filling with 7input = input.crop((0, 0, input.size[0]-transX, input.size[1]-transY))target = target.crop((0, 0, target.size[0]-transX, target.size[1]-transY))input = ToTensor()(input)target = ToLabel()(target)target = Relabel(255,7)(target)return input, target
加载数据:我们将遵循 pytorch 推荐的语义,并使用数据加载器加载数据。
best_acc = 0co_transform = MyCoTransform(ENCODER_ONLY, augment=True, height=IMAGE_HEIGHT)co_transform_val = MyCoTransform(ENCODER_ONLY, augment=False, height=IMAGE_HEIGHT)#train datadataset_train = idd_lite(DATA_ROOT, co_transform, ‘train’)print(len(dataset_train))#test datadataset_val = idd_lite(DATA_ROOT, co_transform_val, ‘val’)print(len(dataset_val))loader_train = DataLoader(dataset_train, num_workers=NUM_WORKERS, batch_size=BATCH_SIZE, shuffle=True)loader_val = DataLoader(dataset_val, num_workers=NUM_WORKERS, batch_size=BATCH_SIZE, shuffle=False)
既然是分类问题,我们就使用交叉熵损失,但为什么呢?
答案是负对数,在较小值的时候效果不好,并且在较大值的时候效果也不好。因为我们将损失函数加到所有正确的类别上,实际发生的情况是,每当网络为正确的类别,分配高置信度时,损失就低,但是当网络为正确的类别时分配低置信度,损失就高。
criterion = torch.nn.CrossEntropyLoss()现在让我们加载模型并优化它!
model_file = importlib.import_module(‘erfnet’)model = model_file.Net(NUM_CLASSES).to(device)optimizer = Adam(model.parameters(), 5e-4, (0.9, 0.999), eps=1e-08, weight_decay=1e-4)start_epoch = 1
所以,编码的最终本质就是训练!
import ossteps_loss = 50my_start_time = time.time()for epoch in range(start_epoch, NUM_EPOCHS+1):— — — TRAINING — EPOCH”, epoch, “ — — -”)epoch_loss = []time_train = []doIouTrain = IOUTRAINdoIouVal = IOUVALif (doIouTrain):iouEvalTrain = iouEval(NUM_CLASSES)model.train()for step, (images, labels) in enumerate(loader_train):start_time = time.time()inputs = images.to(device)targets = labels.to(device)outputs = model(inputs, only_encode=ENCODER_ONLY)# zero the parameter gradientsoptimizer.zero_grad()# forward + backward + optimizeloss = criterion(outputs, targets[:, 0])loss.backward()optimizer.step()epoch_loss.append(loss.item())— start_time)if (doIouTrain):#start_time_iou = time.time()targets.data)#print (“Time to add confusion matrix: “, time.time() — start_time_iou)# print statisticsif steps_loss > 0 and step % steps_loss == 0:average = sum(epoch_loss) / len(epoch_loss): {average:0.4} (epoch: {epoch}, step: {step})’, “// Avg time/img: %.4f s” % (sum(time_train) / len(time_train) / BATCH_SIZE))average_epoch_loss_train = sum(epoch_loss) / len(epoch_loss)iouTrain = 0if (doIouTrain):iou_classes = iouEvalTrain.getIoU()iouStr = getColorEntry(iouTrain)+’{:0.2f}’.format(iouTrain*100) + ‘\033[0m’print (“EPOCH IoU on TRAIN set: “, iouStr, “%”)my_end_time = time.time()— my_start_time)
在训练了 100 个 epoch 之后,我们会看到:

验证:
#Validate on val images after each epoch of training— — — VALIDATING — EPOCH”, epoch, “ — — -”)model.eval()epoch_loss_val = []time_val = []if (doIouVal):iouEvalVal = iouEval(NUM_CLASSES)for step, (images, labels) in enumerate(loader_val):start_time = time.time()inputs = images.to(device)targets = labels.to(device)with torch.no_grad():outputs = model(inputs, only_encode=ENCODER_ONLY)#outputs = model(inputs)loss = criterion(outputs, targets[:, 0])epoch_loss_val.append(loss.item())— start_time)#Add batch to calculate TP, FP and FN for iou estimationif (doIouVal):#start_time_iou = time.time()targets.data)#print (“Time to add confusion matrix: “, time.time() — start_time_iou)if steps_loss > 0 and step % steps_loss == 0:average = sum(epoch_loss_val) / len(epoch_loss_val)loss: {average:0.4} (epoch: {epoch}, step: {step})’,Avg time/img: %.4f s” % (sum(time_val) / len(time_val) / BATCH_SIZE))average_epoch_loss_val = sum(epoch_loss_val) / len(epoch_loss_val)iouVal = 0if (doIouVal):iou_classes = iouEvalVal.getIoU()print(iou_classes)iouStr = getColorEntry(iouVal)+’{:0.2f}’.format(iouVal*100) + ‘\033[0m’print (“EPOCH IoU on VAL set: “, iouStr, “%”)

可视化输出:
# Qualitative Analysisdataiter = iter(loader_val)images, labels = dataiter.next()if USE_CUDA:images = images.to(device)inputs = images.to(device)with torch.no_grad():outputs = model(inputs, only_encode=ENCODER_ONLY)label = outputs[0].max(0)[1].byte().cpu().datalabel_color = Colorize()(label.unsqueeze(0))label_save = ToPILImage()(label_color)plt.figure()plt.imshow(ToPILImage()(images[0].cpu()))plt.figure()plt.imshow(label_save)
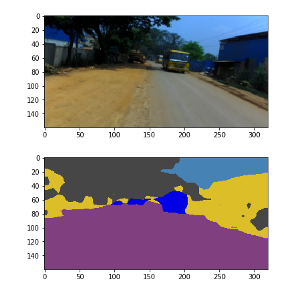
很快我们就可以准备好我们的模型了!
随意使用我们新设计的模型,尝试增加更多的 epoch 并观察我们的模型表现得更好!
因此,简而言之,现在我们将能够轻松地将图像的每个像素与类标签相关联,并可以调整超参数以查看显示的更改。本文展示了语义分割的基础知识,要对实例进行分类,我们需要进行实例分割,这是语义分割的高级版本。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码: