
华为北大等联手打造的Transformer竟在CV领域超过了CNN:多项底层视觉任务达到SOTA

本文转载自量子位
量子位 报道 | 公众号 QbitAI
提起Transformer,就会想到BERT、GPT-3。
但其实,这个在各种自然语言处理任务中「混迹」,强大的无监督预训练模型,现在已经在「计算机视觉」的道路上越走越远了。
这不最近,北京大学,联合华为诺亚方舟实验室、悉尼大学、鹏城实验室提出了一个图像处理Transformer(IPT)。

它是一种处理底层视觉任务(如降噪、超分、去雨)的全新预训练模型。
为了最大化挖掘模型的能力,研究人员使用 ImageNet 数据集对模型进行预训练,结果经过预训练的模型只需要做一些简单微调即可适用于多种下游任务。
最终,IPT模型在多个底层视觉任务中的表现都达到了SOTA的水准。
图像处理Transformer
从IPT的结构上看,它具备「多头多尾」结构,对于不同的视觉任务,只需要改变头和尾部的结构即可,多种任务共享同一个Transformer 模块。
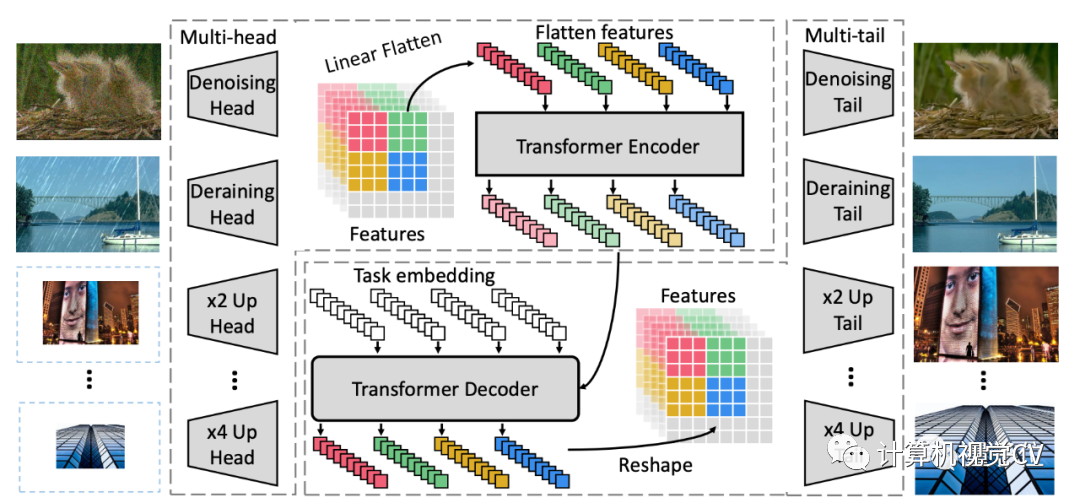
我们知道Transformer在自然语言处理任务中,输入是单词序列。那么在图像处理任务中,输入输出的都是图像。
除了处理超分辨率任务之外,其他视觉任务图片输入输出的维度相同。Transformer模块在这当中负责特征图处理的任务,头部和尾部的结构则负责图像维度匹配。
具体来说,IPT整体架构由四个部分组成:
头部,采用多头架构,每个头由三个卷积层组成来分别处理每个任务。
这部分主要负责从输入的损坏图像中提取特征,比如低分辨率、需降噪的图像。
Transformer 编码器,在特征输入Transformer模块前,将给定的特征分割成特征块,每个特征块被视作一个「word」。
Transformer 解码器,与编码器采用了同样的架构。将解码器的输出作为Transformer的输入。
为了适应多任务,研究人员还加入了一个可学习的任务编码。
总的来说,这两部分用于恢复输入数据中的缺失信息。

△去雨任务上的视觉效果
尾部,与头部结构相同,用于将特征映射到重建图像中。
随后,研究人员使用 ImageNet 数据集对模型进行预训练。最终,该模型只需要在特定任务的数据集上进行**「微调」**,即可在此任务上达到很好的效果。
在微调阶段,只有特定任务所对应的头尾结构以及 Transformer 模块被激活训练,与此任务无关的头尾模块会被暂时冻结。
在多个底层视觉任务中达到SOTA
IPT与HAN、RDN、RCDNet在超分辨率、降噪、去雨任务上的性能对比中,均取得了0.4到2.0dB不等的性能提升。
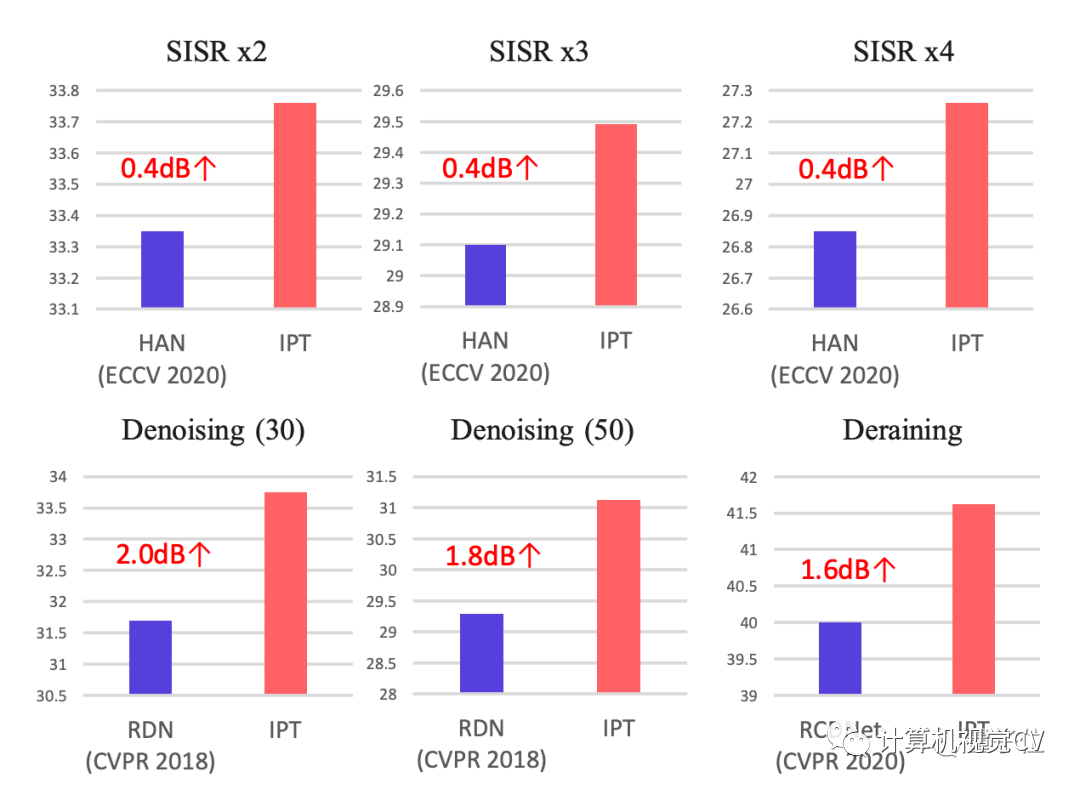
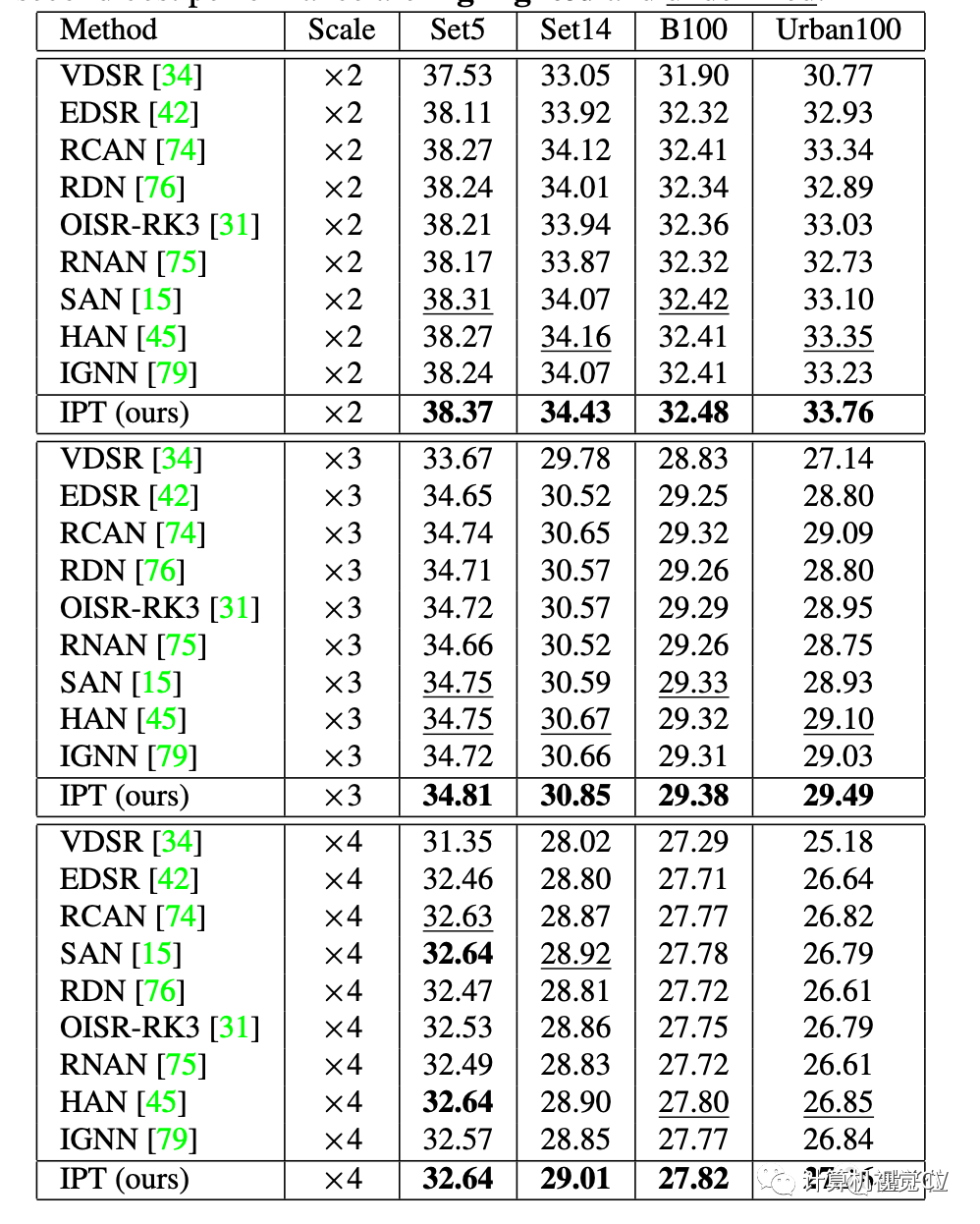
具体到超分任务上,在 Set5、Set14、B100 以及 Urban100 四个数据集上的结果,IPT 模型在所有设定下均取得了最好的结果。
尤其是在 Urban100 数据集上,和当前最好的超分辨率算法相比,IPT 模型展现出了大幅度的优势。
而在降噪任务上,IPT也都表现出了类似的性能。
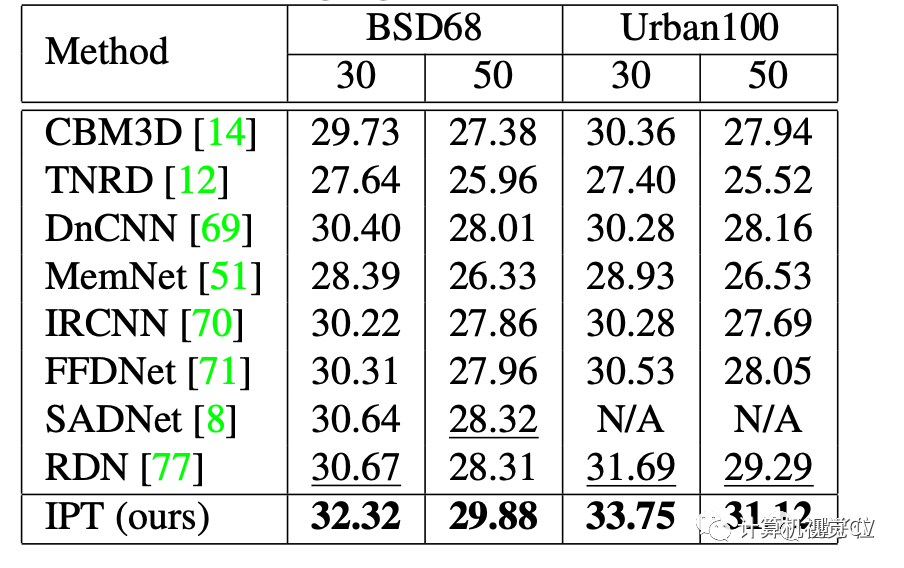
△降噪任务上的性能对比
从实验结果看到,Transformer在底层视觉任务上的表现似乎还不错,甚至超过了CNN的实力。
论文链接:
https://arxiv.org/abs/2012.00364