
超全总结!华为诺亚视觉Transformer综述解读
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
2021年对计算机视觉来说是非常重要的一年,各个任务的SOTA不断被刷新。这么多种Vision Transformer模型,到底该选哪一个?新手入坑该选哪个方向?华为诺亚方舟实验室的这一篇综述或许能给大家带来帮助。
综述论文链接:
https://ieeexplore.ieee.org/document/9716741/
诺亚开源模型:
https://github.com/huawei-noah
华为A+M社区:
https://www.mindspore.cn/resources/hub
如何将Transformer应用于计算机视觉(CV)任务,引起了越来越多研究人员的兴趣。在过去很长一段时间内,CNN成为视觉任务中的主要模型架构,但如今Transformer呈现出巨大的潜力,有望在视觉领域中打败CNN的霸主地位。谷歌提出了ViT架构,首先将图像切块,然后用纯Transformer架构直接应用于图像块序列,就能完成对图像的分类,并在多个图像识别基准数据集上取得了优越的性能。除图像分类任务之外,Transformer还被用于解决其他视觉问题,包括目标检测(DETR),语义分割(SETR),图像处理(IPT)等等。由于其出色的性能,越来越多的研究人员提出了基于Transformer的模型来改进各种视觉任务。为了让大家对视觉Transformer在这两年的飞速发展有一个清晰的感受,图1展示了视觉Transformer的发展里程碑,从图像分类到目标检测,从图片生成到视频理解,视觉Transformer展现出了非常强的性能。
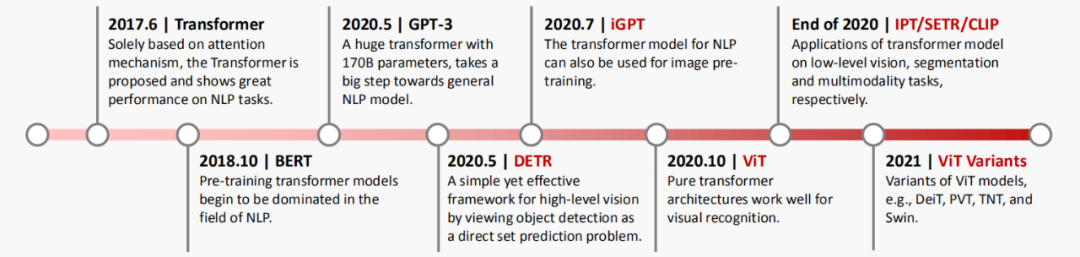 图1 视觉Transformer的发展历程
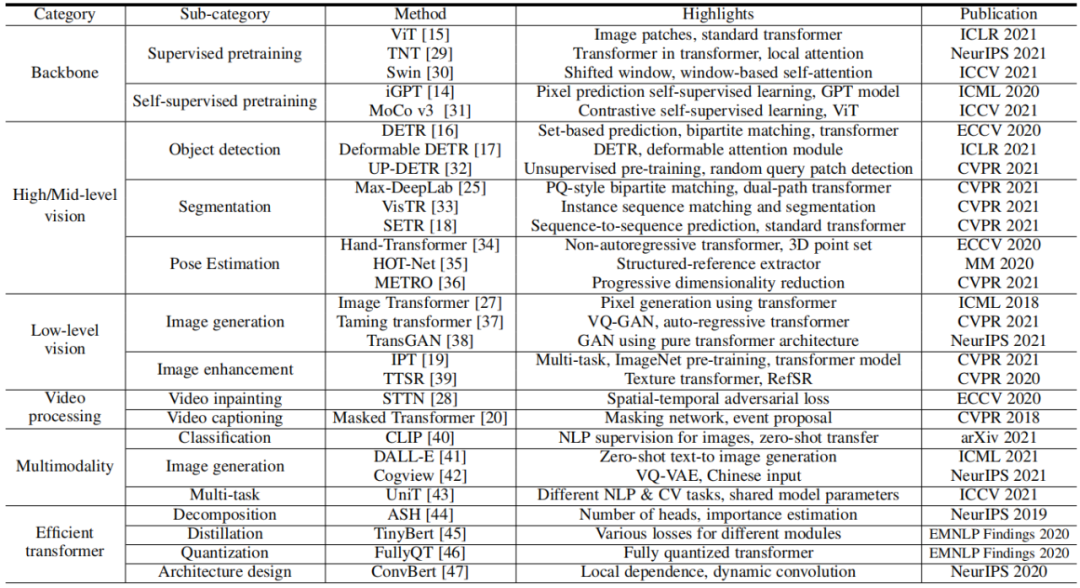
图1 视觉Transformer的发展历程按照视觉Transformer的设计和应用场景,本文对视觉Transformer模型进行了系统性的归类,如表1所示:骨干网络、高/中层视觉、底层视觉、多模态等,并且在每一章中针对任务特点进行详细分析和对比;
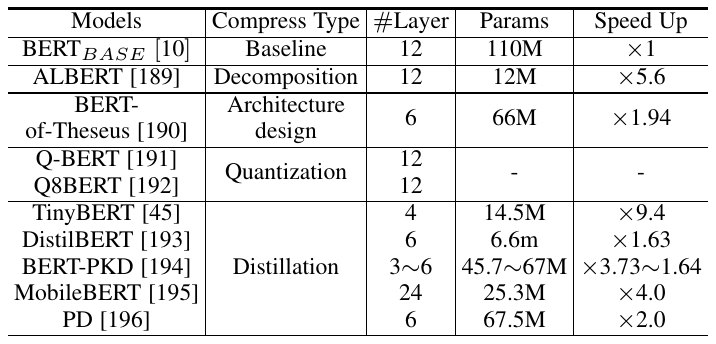
本文针对高效的视觉Transformer进行了详细的分析,尤其是在标准数据集和硬件上进行了精度和速度的评测,并讨论了一些Transformer模型压缩和加速的方法;
华为是一家具有软硬件全栈AI解决方案的公司,基于A+M生态,在Transformer领域已经做出了很多有影响力的工作,基于这些经验并且联合了业界知名学者一起进行了深入思考和讨论,给出了几个很有潜力的未来方向,供大家参考。
https://arxiv.org/abs/2104.12369
https://arxiv.org/abs/1909.00204
https://arxiv.org/abs/1909.10351
https://arxiv.org/abs/2012.00364
https://arxiv.org/abs/2111.07783
https://arxiv.org/abs/2103.00112
骨干网络
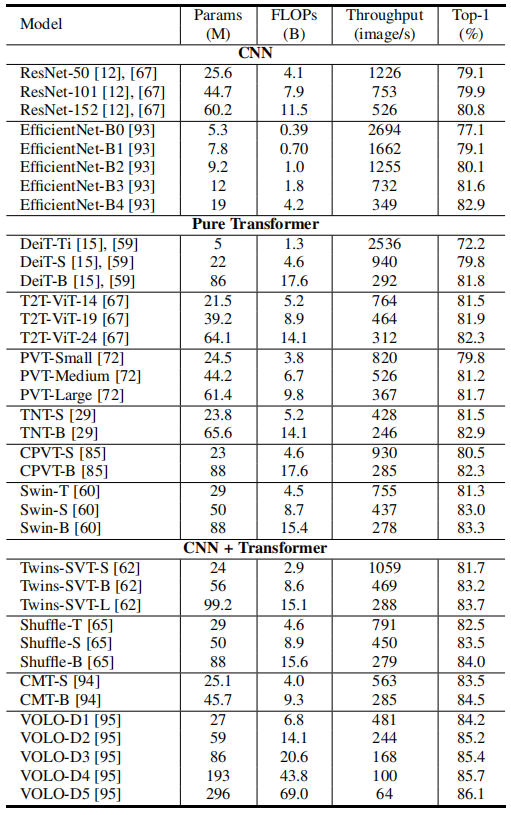
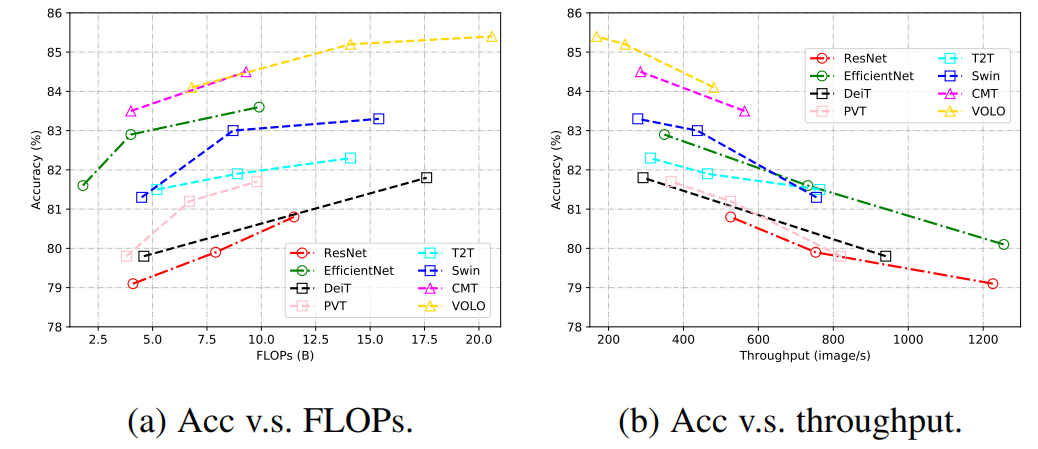
目标检测
底层视觉
多模态
高效Transformer
未来展望
业界流行有各种类型的神经网络,如CNN、RNN和Transformer。在CV领域,CNN曾经是主流选择,但现在Transformer变得越来越流行。CNN可以捕捉归纳偏置,如平移等变和局部性,而ViT使用大规模训练来超越归纳偏置。从现有的观察来看,CNN在小数据集上表现良好,而Transformer在大数据集上表现更好。而在视觉任务中,究竟是使用CNN还是Transformer,或者兼二者之所长,是一个值得探究的问题。
大多数现有的视觉Transformer模型设计为只处理一项任务,而许多NLP模型,如GPT-3,已经演示了Transformer如何在一个模型中处理多项任务。CV领域的IPT能够处理多个底层视觉任务,例如超分辨率、图像去雨和去噪。Perceiver和Perceiver IO 也是可以在多个领域工作的Transformer模型,包括图像、音频、多模态和点云。将所有视觉任务甚至其他任务统一到一个Transformer(即一个大统一模型)中是一个令人兴奋的课题。
另一个方向是开发高效的视觉Transformer;具体来说,如果让Transformer具有更高精度和更低资源消耗。性能决定了该模型是否可以应用于现实世界的应用,而资源成本则影响其在硬件设备上的部署。而通常精度与资源消耗息息相关,因此确定如何在两者之间实现更好的平衡是未来研究的一个有意义的课题。
通过使用大量数据进行训练,Transformer可以在NLP和CV不同任务上得到领先的性能。最后,文章还留下一个问题:Transformer能否通过更简单的计算范式和大量数据训练获得令人满意的结果?
本文仅做学术分享,如有侵权,请联系删文。
