
实例分割新思路之SOLO v1&v2深度解析
前言
实例分割一般有两种做法,一种是top-down,既先检测 bbox,后在每个bbox中进行mask的分割,例如Mask R-CNN。第二种为bottom-up做法,先分割出每一个像素,再进行归类。本文介绍的两篇论文另辟蹊径, 直接分割实例 mask,属于box-free的做法。正如YOLO大神Joseph Redmon所说“Boxes are stupid anyway though, I’m probably a true believer in masks except I can’t get YOLO to learn them“。本文就是摒弃了boxes进行实例分割,因此有必要对该论文进行深入分析。
论文地址:v1: https://arxiv.org/abs/1912.04488 ,v2: https://arxiv.org/abs/2003.10152。
参考的代码为在mmdetection的基础上实现的:https://github.com/WXinlong/SOLO
SOLO v1
head设计
首先思考一个问题,能否像语义分割一样进行实例分割?实例分割和语义分割在算法处理上最大的不同就是,实例分割需要处理同类别的实例重叠或粘连的问题。那么如果将不同的实例分配到不同的输出channel上,不就可以解决这个问题了吗?本文作者正是这种思路,不过这样也面临两个问题: 一是通道分配顺序的问题,语义分割是根据类别进行通道分配的。而对于实例分割,相同类别的不同实例需要分配到不同通道上,需要解决按照什么样的规则分配。二是尺度问题,不同尺度的物体利用相同大小的输出来预测会导致正负样本不平衡,以及小目标分割边缘不够精细的问题。对于这两个问题,本文作者给出了解答。作者首先对MS COCO数据集进行统计,发现在验证集中,绝大多数(约98.9%)的实例要么中心位置不同,要么大小不同。因此可以通过中心位置和对象大小直接区分实例, 既location 和 sizes。所以作者利用位置来分配实例应该落入哪一个通道,利用FPN来解决尺度问题。
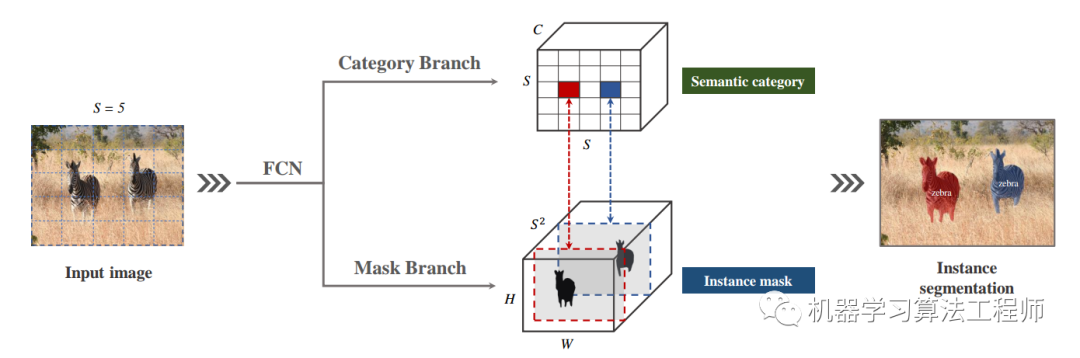
具体做法为:
类似YOLO中的做法,首先将图片等分为 个格子。网络输出为两个分支:分类分支和mask分支。分类分支的大小为,为类别数量。mask分支大小为,为预测的最大实例个数,按照从上到下从左到右的方式与原图位置对应起来。当目标物体中心落入哪一个格子,分类分支对应位置以及mask分支对应通道负责该物体的预测。例如实例分配到格子, 则mask分支上通道 负责预测该目标的mask, 每个格子都只属于一个单独的实例。这就是论文对Locations的设计。
而对于Sizes,则采用通用做法:FPN。大的特征图负责预测小的目标,小的特征图负责预测大的目标。FPN也可以一定程度上缓解目标重叠的问题,尺度不同的实例会被分配到不同FPN输出层中进行预测。
正负样本分配策略
包括两个方面,一是FPN同一层正负样本分配的策略。二是FPN不同层正负样本分配的策略。
FPN同一层
对于给定gt mask的质心、宽度w和高度h,设置比例因子,这里。当被缩小后的box落入原图上某几个格子,这些格子对应的分类分支位置以及mask分支channel为正样本,否则为负样本。每一个gt平均有3个正样本。代码如下:
# 分类分支的正负样本分配,这里的top,down,left,right为gt box缩小sigma倍后的box上下左右值
cate_label[top:(down+1), left:(right+1)] = gt_label
# 对于mask分支的正样本分配,在0.2倍的gt box内grid cell对应的通道均分配为mask正样本
seg_mask = mmcv.imrescale(seg_mask, scale=1. / output_stride)
seg_mask = torch.Tensor(seg_mask)
for i in range(top, down+1):
for j in range(left, right+1):
label = int(i * num_grid + j)
ins_label[label, :seg_mask.shape[0], :seg_mask.shape[1]] = seg_mask
FPN不同层
论文设置scale_ranges=((1, 96), (48, 192), (96, 384), (192, 768), (384, 2048)),分别对应不同FPN的输出层。当实例的尺度落入某一个区间,则该FPN分支负责该实例的预测。由于不同区间存在重叠的情况,因此会存在不同FPN层预测相同的目标,这样同样会增加正样本的数量。代码如下:
gt_areas = torch.sqrt((gt_bboxes_raw[:, 2] - gt_bboxes_raw[:, 0]) * (gt_bboxes_raw[:, 3] - gt_bboxes_raw[:, 1])) # gt的面积, 这里采用的是sqrt(W*H)
# 对FPN进行遍历, 区间为 scale_ranges=((1, 96), (48, 192), (96, 384), (192, 768), (384, 2048)), gt_areas所属哪一个区间, 则该层FPN负责该实例的预测
for (lower_bound, upper_bound), stride, featmap_size, num_grid in zip(self.scale_ranges, self.strides, featmap_sizes, self.seg_num_grids):
hit_indices = ((gt_areas >= lower_bound) & (gt_areas <= upper_bound)).nonzero().flatten() # 收集该层负责的个数
if len(hit_indices) == 0:
continue
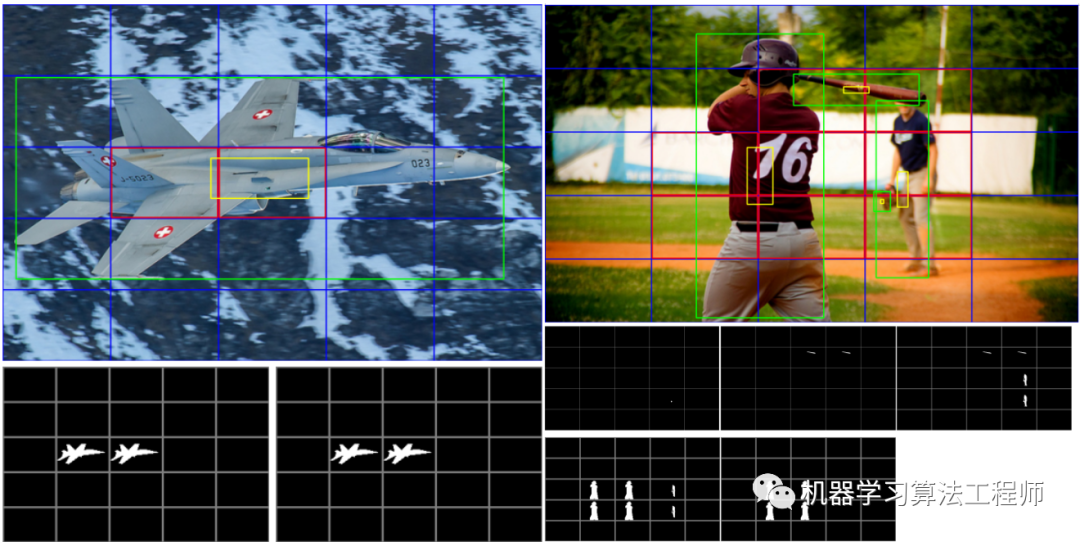
可视化分析
为了更清晰理解样本分配策略,这里进行了可视化。如图所示,在原图中,蓝色框表示图片等分的格子,这里设置分为5X5个格子。绿色框为目标物体的gt box,黄色框表示缩小到0.2倍数的box,红色框表示负责预测该实例的格子。下方黑白图为mask分支的target可视化,为了便于显示,这里对不同通道进行了拼接。左边的第一幅图,图中有一个实例,其gt box缩小到0.2倍占据两个格子,因此这两个格子负责预测该实例。下方的mask分支,只有两个FPN的输出匹配到了该实例,因此在红色格子对应的channel负责预测该实例的mask。第二幅图,图中分布大小不同的实例,可见在FPN输出的mask分支上,从小到大负责不同尺度的实例。这里值得注意的是,FPN输出的mask分支,其尺度并不是统一的,而是从大到小的,这里为了便于显示才缩放到统一尺寸上。
CoordConv
本文利用了CoordConv,目的是为了加强卷积神经网络对位置信息的处理。CoordConv做法非常简单, 直接在原始tensor上利用concatenate的方式扩两个通道,分别存储x和y的坐标,并归一化到[-1,1]之间。显式地把位置信息带入到下一个卷积操作里面。不过CoordConv也引起了一些争议,但该论文(SOLO)中使用还是起到了不错的效果,本文不去讨论。这一点,原作在知乎也给出了自己的看法:
关于CoordConv和Dice Loss:这些并不是比普通Conv和BCE Loss更高级的东西,只是在我们这种情况下更适用而已: CoordConv用来提供全局位置信息,Dice Loss来解决分割区域小的问题。而Mask R-CNN是没有这样的需求的。
具体做法如下,创建一个包含像素坐标tensor(标准化至),和原始通道concatenate,因此可以看到Channel数为(256+2),最后两个通道提供全图位置信息,再送入到后续的卷积运算中。代码如下:
ins_feat = x # 当前实例特征tensor
# 生成从-1到1的线性值
x_range = torch.linspace(-1, 1, ins_feat.shape[-1], device=ins_feat.device)
y_range = torch.linspace(-1, 1, ins_feat.shape[-2], device=ins_feat.device)
y, x = torch.meshgrid(y_range, x_range) # 生成二维坐标网格
y = y.expand([ins_feat.shape[0], 1, -1, -1]) # 扩充到和ins_feat相同维度
x = x.expand([ins_feat.shape[0], 1, -1, -1])
coord_feat = torch.cat([x, y], 1) # 位置特征
ins_feat = torch.cat([ins_feat, coord_feat], 1) # concatnate一起作为下一个卷积的输入
Decoupled head
由于mask分支预测个通道, 如果grid cell 设置过多的话,该输出通道会过于庞大。因此论文提出Decoupled head的改进方式。具体见下图,将mask分支拆分为X方向和Y方向两个分支,每一个分支的通道数为。将两个分支按照element-wise的方式进行相乘获取mask输出,这样预测通道由原来的变为了个,实验发现精度并没有明显的损失。此时想要获取第个格子预测的mask,只需要将Y分支的第个通道和X分支的第个通道取出来,进行element-wise乘即可,其中 。
代码如下:
# 利用两个kernel=3的卷积分别输出x和y两个分支
self.dsolo_ins_list_x = nn.ModuleList()
self.dsolo_ins_list_y = nn.ModuleList()
for seg_num_grid in self.seg_num_grids:
self.dsolo_ins_list_x.append(nn.Conv2d(self.seg_feat_channels, seg_num_grid, 3, padding=1))
self.dsolo_ins_list_y.append(nn.Conv2d(self.seg_feat_channels, seg_num_grid, 3, padding=1))
# 获取最终预测的mask, x和y分支直接相乘, 注意两个分支提前经过sigmoid。x_inds和y_inds是提前计算出来的
seg_masks_soft = seg_preds_x[x_inds, ...] * seg_preds_y[y_inds, ...]
loss
loss包括两部分,分别是分类分支的loss和mask分支的loss。分类loss直接使用FocalLoss,注意这里输出采用的是sigmoid激活。总loss为:
mask分支loss如下:
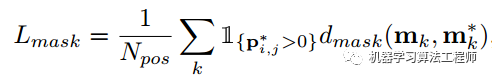
值得注意的是,mask分支的loss仅仅在(为target在位置分类标签)。「可见在没有分配到的目标的输出层,是不计算loss的,既该层被当做忽略样本。」
对于作者尝试了BCE、FocalLoss以及Dice loss(DL),发现DL优于FL和BCE。Dice loss 会侧向于对正样本的挖掘,之前的文章做过深入的分析。mask的loss 代码如下:
loss_ins = []
for input, target in zip(ins_preds, ins_labels):
if input.size()[0] == 0:
continue
input = torch.sigmoid(input) # mask分支经过sigmoid的激活
loss_ins.append(dice_loss(input, target)) # dice loss
loss_ins = torch.cat(loss_ins).mean()
loss_ins = loss_ins * self.ins_loss_weight # ins_loss_weight 为 0.3
预测过程
因此整个预测的过程为:
提取所有分类分支的预测概率值,并利用阈值(例如0.1)进行过滤; 获取过滤后剩下的分类位置对应的索引; 将X分支通道和Y分支通道利用element-wise相乘的方式获取该类别的mask; 利用阈值(例如0.5)对mask进行筛选; 对所有mask进行nms; 将最终mask缩放到原图大小。
solo v2
v2在v1的基础上进行改进,其网格设计、正负样本分配策略、CoordConv、loss等操作完全继承与V1。主要区别有以下两点:
继续优化改进了mask输出的head,利用动态的方式获取;
提出了Matrix NMS,可以更快速的进行mask的NMS;
动态mask head
v1采用的是Decoupled head的方式,分别预测X分支和Y分支,使用的时候再进行element-wise相乘。v2继续进行了优化,提出了dynamic head。如下图,mask预测分为了kernel 分支和feature 分支。
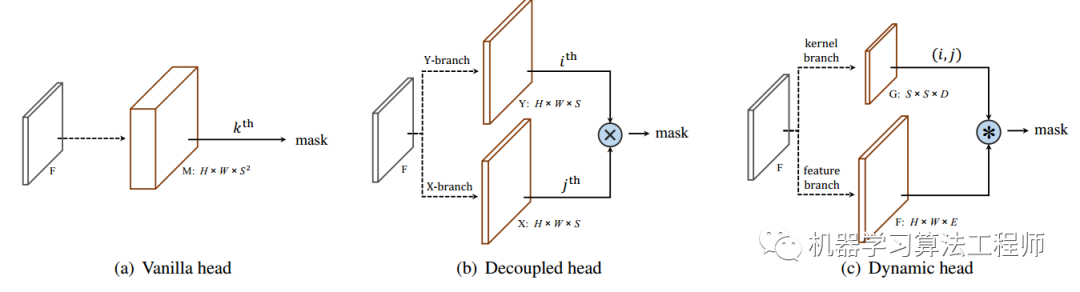
「feature 分支:」
直接将FPN的输出进行融合为一个tensor,融合的方式为卷积+上采样来保证所有层尺寸相同,最终为输入图片1/4大小。值得注意的是在FPN最小输出层的处理上,同样利用了CoordConv来保证位置编码被输入进行。融合方式如下:
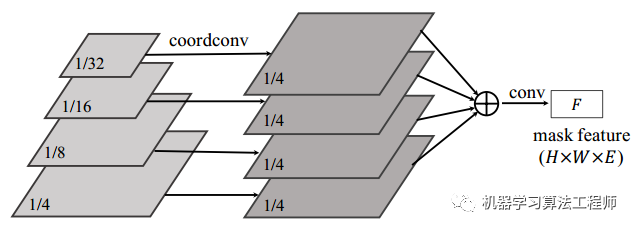
「kernel分支:」
kernel分别直接来自FPN每个分支,和FPN的数目是对应上的。因此对于每一个FPN分支来说:
# 直接进行双线性插值,尺度变化为: [1,256+2,h,w] -> [1,256+2,S,S]
# 这里的256+2同样利用了CorrdConv,S为grid cell的个数
kernel_feat = F.interpolate(kernel_feat, size=seg_num_grid, mode='bilinear')
#后续还有一些卷积操作,最终输出的tensor为[1,256,S,S]
对于最终每一个的 tensor,可以理解为有个卷积核,分别提取对应位置的mask。计算loss的时候,只需要根据target分配的位置,从中提取对应的tensor作为卷积核对feature进行的卷积操作,即可以提取预测的mask。预测过程中,只需要将经过阈值过滤的类别得分对应的位置提取卷积核进行卷积提取mask操作既可,提高了运算的速度。
Matrix NMS
文章提出了Matrix NMS,可以理解为:Matrix NMS 结合soft NMS 、 Fast NMS ,并实现对mask 求IOU。这里分别回顾一下这三种技术:
「soft NMS」:NMS改进之一,为了防止IOU较大且非虚检的预测被删掉,来自论文《Improving Object Detection With One Line of Code》。传统的NMS将IOU大于阈值的检测框直接删掉,而soft NMS将IOU大于阈值框得分做了惩罚,惩罚分为线性惩罚和高斯惩罚两种。当所有box经过惩罚修正后,再利用阈值对box进行过滤。代码解析如下:
if method == 'linear': # 线性惩罚,惩罚因子为:1-iou,注意只有iou大于阈值的才进行惩罚
weight = np.ones_like(iou)
weight[iou > iou_thr] -= iou[iou > iou_thr]
elif method == 'gaussian': # 高斯惩罚, 所有的box均会被惩罚
weight = np.exp(-(iou * iou) / sigma)
else: # 传统方法,直接将iou大于iou_thr的box的得分置0
weight = np.ones_like(iou)
weight[iou > iou_thr] = 0
# 对所有box的score进行更新
dets[1:, 4] *= weight
「Fast NMS」:NMS改进之一,目的是为了提速,来自论文YOLACT。由于IOU计算具有对称性,即,因此该方法是利用triu函数对IOU 矩阵进行上三角化,然后对IOU Matrix执行按列取最大值操作,再抑制IOU大于阈值的box。代码如下:
def fast_nms(boxes, scores, NMS_threshold=0.5):
scores, idx = scores.sort(1, descending=True)
boxes = boxes[idx] # 对框按得分降序排列
iou = box_iou(boxes, boxes) # 获取IoU矩阵
iou.triu_(diagonal=1) # 对IoU矩阵上三角化
keep = iou.max(dim=0)[0] < NMS_threshold # 列最大值向量,二值化
return boxes[keep], scores[keep]
「mask求IOU」:由于box 求IOU比较简单,这里不再给出。而mask 求IOU,会比box复杂,也更耗时,这里给出直接求出IOU matrix的方式:
def mask_iou(masks1,masks2):
n_samples = masks1.size()[0] # mask的个数
sum_masks = seg_masks.sum((1, 2)).float() # 求面积操作
seg_masks = seg_masks.reshape(n_samples, -1).float() # 将wh拉成一个维度
# IOU即为交并比,这里进行求相交的部分
inter_matrix = torch.mm(seg_masks, seg_masks.transpose(1, 0))
# 求并的部分
sum_masks_x = sum_masks.expand(n_samples, n_samples)
# iou.
iou_matrix = (inter_matrix / (sum_masks_x + sum_masks_x.transpose(1, 0) - inter_matrix)).triu(diagonal=1) # 计算IoU矩阵并进行上三角化
return iou_matrix
本文中提出了Matrix NMS,使用并行的矩阵运算单次地实现NMS,不需要多次迭代。Matrix NMS可以做到在不到1ms的时间里处理500张mask,并且比目前最快的Faster NMS要高0.4% AP。论文给出的伪代码如下:
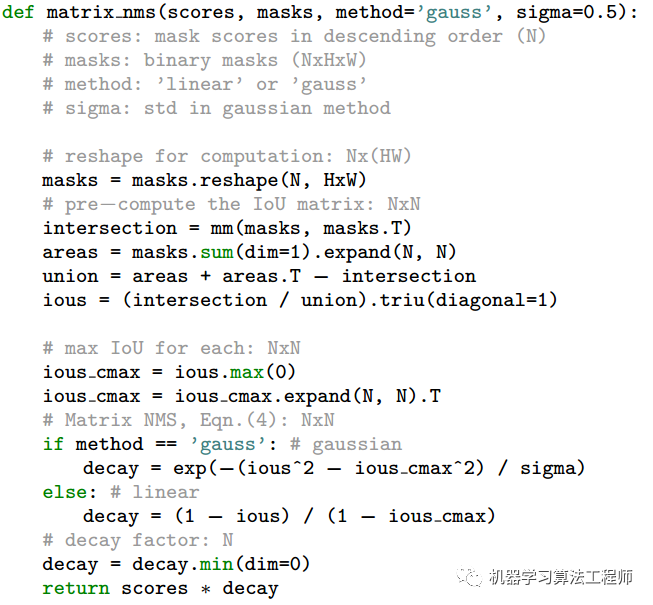
预测过程
预测过程和v1类似,主要区别是v2提取mask的利用分类分支对应的卷积核,对特征图进行卷积求mask。另外,获取得到的所有mask进行Matrix NMS合并重复的mask。
后记
SOLO利用直接预测mask的方式进行实例分割,并做到的非常不错的效果,是一种很好的思路,期待后续会有新版本的出现。
机器学习算法工程师
一个用心的公众号
