实例分割(Instance Segmentation)任务有着广阔的应用和发展前景。来自腾讯 PCG 应用研究中心 (ARC)和华中科技大学的研究者们通过充分挖掘并利用Query在端到端实例分割任务中与实例存在一一对应的特性,提出基于Query的实例分割新方法,在速度和精度上均超过现有算法。
在今年的计算机视觉顶级会议 ICCV 2021 上,腾讯 PCG 应用研究中心(ARC)与华中科技大学电信学院人工智能研究所联合提出业内领先的端到端实例分割算法 QueryInst。实例分割是视觉感知的基础问题,QueryInst 算法充分利用了 Query 与实例之间的一一对应关系,搭建了简洁且高效的实例分割模型。该算法在实例分割基线数据集 COCO、Cityscapes 以及视频实例分割基线数据集 YouTube-VIS 上进行了验证,在精度和速度方面都全面超越之前的 SOTA 方法,充分展示了 Query 机制在物体分割方向的超强实力。



实例分割(Instance Segmentation)任务是计算机视觉的经典任务之一。与目标检测、语义分割不同,实例分割任务聚焦于细粒度的图像理解,旨在对图片中感兴趣类别的实例进行像素级别的前景掩码预测。通过实例分割算法,可以获得图像的离散语义标签,从而进一步辅助下游的图像感知和图像生成。

在计算机视觉的发展长河中涌现了许多经典的实例分割算法。Mask R-CNN 基于 Faster R-CNN 网络,通过 RoIAlign 操作以及新引入的 Mask Head 完成掩码的预测。Cascade Mask R-CNN 通过结合 Cascade R-CNN 以及 Mask R-CNN,以一种级联的形式来产生更加准确、精细的掩码预测。HTC (Hybrid Task Cascade)在对 Cascade Mask R-CNN 的结构进行仔细分析后,通过调整网络的级联方式,并引入 Mask Information Flow 以及语义辅助分支来进一步增强实例分割的效果,在相当长的一段时间内,HTC 占据着实例分割领域的领先地位。DETR 提出基于 Query(Query based)的端到端物体检测算法,该方法摆脱了之前物体预测总是基于固定空间位置的锚框 / 锚点(anchor based/keypoint based),转而依赖于可学习的向量进行预测。训练过程中,预测的结果与实际的真实值之间进行一一匹配,匹配的结果确定了预测损失的计算。这种一一匹配的方式有效地避免了网络产生重复冗余的预测,从而在推理阶段中可以不依赖于非极大值抑制等后处理算法,实现了端到端的目标检测。后续的 Deformable DETR、Sparse R-CNN 等工作进一步提高了基于 Query 的端到端物体检测算法的收敛速度以及精度。与之前基于锚框 / 锚点(anchor based/keypoint based)的方法相比,基于 Query 的方法已经取得了可媲美的结果。在基于 Query 的目标检测算法快速发展的同时,如何拓展这种目标检测算法,使之有效的拓展到实例分割领域即为该论文探讨的问题。该论文通过大量的分析和实验论证说明:构建有效的基于 Query 的端到端实例分割算法不能简单地参考之前实例分割算法的思路,充分利用 Query 预测值与真实值之间一一对应的关系是提高算法模型精度和效率的关键。参照 Mask R-CNN 与 Cascade Mask R-CNN 的设计思路,该论文首先提出了采用上述与之类似的简单掩码分割头(Vanilla Mask Head)的网络设计。在这种设计下,模型的掩码预测完全依赖于边界框(bounding box)和骨干网络提取的特征,通过 RoIAlign 操作进行局部特征提取之后,一个由若干卷积层组成的掩码预测头负责预测该区域的前景掩码。
在实验过程中,研究者发现直接使用上述简单的实例分割框架并不能得到很好的效果。原因之一在于上述框架并没有很好地利用 Query 所包含的实例特征。于是研究者们在上述结构的基础上通过引入多头注意力机制(Multi Head Self Attention)以及动态卷积(Dynamic Convolution)来解决该问题。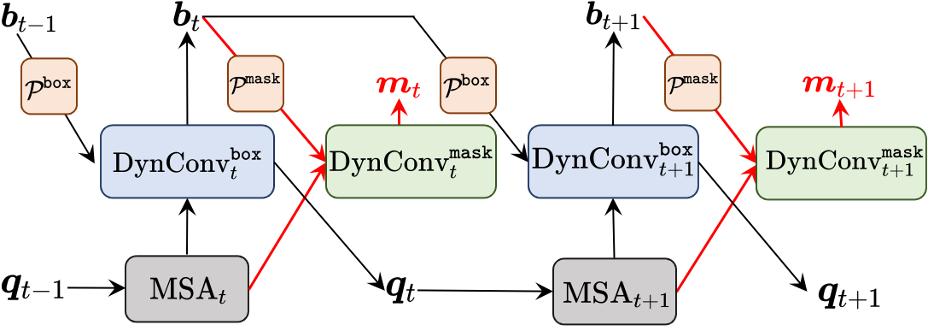
上图展示了该论文所提出的算法 QueryInst 的结构图。可以看出,Query 在检测和分割中依次与特征进行交互,使得 Query 在多任务(检测、分割、分类)中可以提取到不同层级的特征。其次,在不断的级联中,Query 在不同层级中也构建了有效的信息流动。这种跨任务、跨层级的信息流动有效地提高了检测、分类以及分割任务的表现。视频实例分割将实例分割任务从图像域拓展到视频域。为了验证所提算法在不同任务场景下的鲁棒性,研究者们进一步在 QueryInst 的基础上,通过增加动态的跟踪任务头以及跟踪策略,提出了面向视频实例分割场景的 QueryTrack。
如上图所示,QueryTrack 遵循着被广泛采用的「先检测后跟踪」的范式,通过在 QueryInst 框架上添加动态的跟踪任务头来预测实例在连续视频帧中的身份信息,以此来完成时间域上的视频实例关联。为了验证所提出的 QueryInst 在实例分割任务上的有效性,该论文选取了 COCO 实例分割数据集、Cityscapes 实例分割数据集以及 YouTube-VIS 视频实例分割数据集进行验证。COCO 实例分割数据集是实例分割领域使用最广泛的基线数据集之一,Cityscapes 数据集是面向自动驾驶场景下的实例分割数据集。YouTube-VIS 是视频实例分割领域中广泛采用的大规模基线数据集。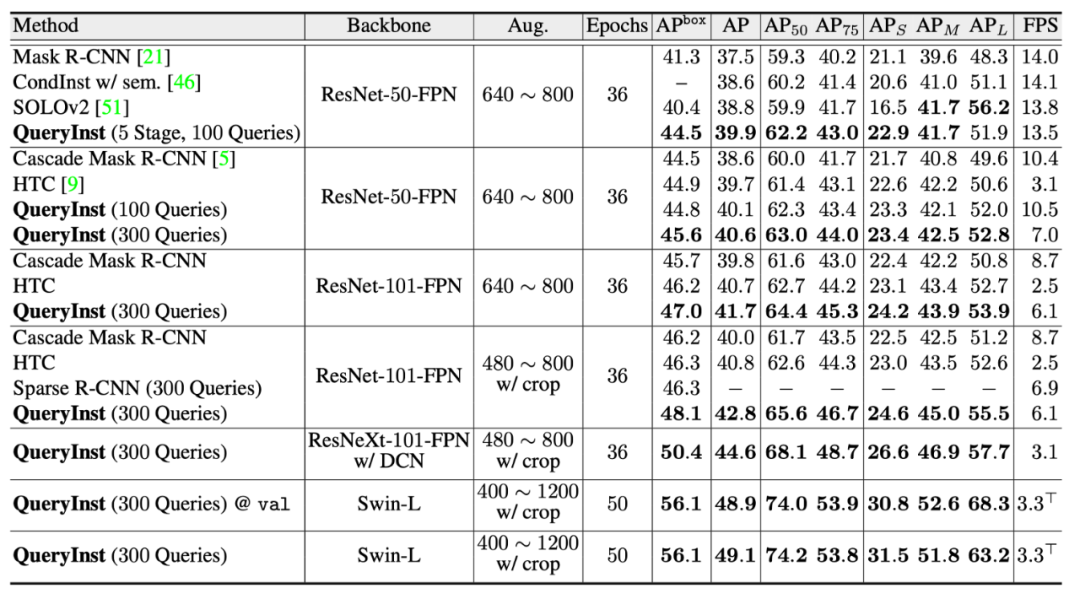
上表展示了 QueryInst 在 COCO 测试集上的实例分割表现。从上述结果中可以看出,QueryInst 在大量不同数据增强的实验中均表现出了最佳的性能,超过了当前实例分割领域中广泛使用的 Mask R-CNN、Cascade Mask R-CNN 以及 HTC 等算法。在 Swin Transformer 的加持下,QueryInst 可以达到验证集 48.9,测试集 49.1 的 Mask AP。
上表为 QueryInst 在 Cityscapes 测试集上的实例分割结果,在相同的骨干网络下,QueryInst 在 Cityscapes 数据集上也超越了 Mask R-CNN、UPSNet、CondInst 等一众模型,取得了较好的实例分割效果。为了进一步探究 Query 在实例分割过程中所扮演的角色,研究者对掩码动态卷积前后的特征进行了可视化。如下图所示,可以观察到,在与 Query 进行动态卷积交互之后,实例的前景特征得到了相当程度的强化,与背景特征之间产生了很好的区分度,这充分地说明了 Query 在算法中的作用。
在 2021 年 YouTube-VIS 视频实例分割比赛中,基于 QueryInst 的视频实例分割模型 QueryTrack 在 YouTube-VIS 数据集上取得了验证集 54.3 AP,测试集 52.3 AP 的成绩,斩获比赛亚军。相较于冠军方法采用了额外数据集辅助训练、多模型联合预测等一系列训练、推理技巧取得测试集 54.1 AP的成绩,该研究的方法仅采用了单模型、单尺度且无额外数据集的训练、推理策略。该比赛吸引了包括 Facebook AI,百度,UIUC 和 CUHK 等著名公司及高校。
研究者认为,QueryInst 充分利用了 Query 与实例一对一的特性,其高精度、高速度的特性将会保证其在计算机视觉的多种下游任务中获得广泛的应用。

该方法是由腾讯 PCG 应用研究中心(ARC)和华中科技大学电信学院人工智能研究所的研究者提出的。应用研究中心被称为腾讯 PCG 的「侦察兵」、「特种兵」,站在腾讯探索挑战智能媒体相关前沿技术的第一线。华中科技大学电信学院人工智能研究所长期致力于目标检测、分割等计算机视觉核心问题的研究,并服务于国家和企业的重大需求。© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

