
深度学习局限何在?
来自 | pnas.org 作者 | M. Mitchell Waldrop
本文近日发表在 PNAS 上,讨论了深度学习取得的成就、推动条件和广泛存在的问题,并从「补充」而不是「推翻」的论点探讨了如何改进人工智能研究方法的方向。文中引用了大量的 DeepMind 发表过的论文,基本思想是提倡延续上世纪 80 年代的符号 AI 方法论,将深度学习结合图网络等实现完整的类人智能。
本文作者 M. Mitchell Waldrop 是威斯康星大学基本粒子物理学博士,曾担任 Nature、Science 等顶级期刊撰稿人、编辑,出版过《复杂》等科学著作。
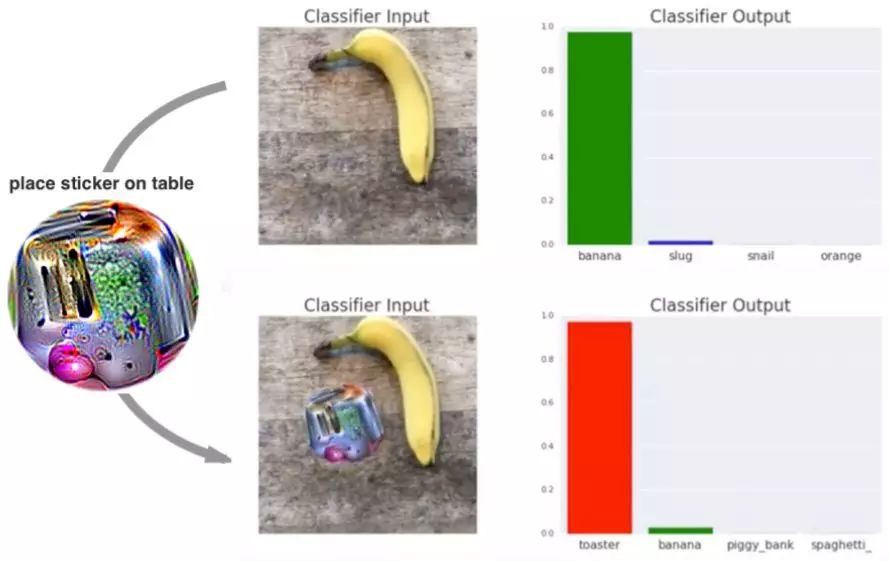
上图中是一根香蕉,然而人工智能却将其识别为烤面包机,即使它使用了在自动驾驶、语音理解和多种 AI 应用中表现出色的强大深度学习技术。这意味着 AI 已经见过了几千张香蕉、蛞蝓、蜗牛和类似外观的物体,然后对新输入的图像预测其中物体的类别。然而这种系统很容易被误导,图像中只是多了一张贴纸,就让系统的预测产生严重偏离。

深度学习方法中的明显缺点引起了研究员和大众的关注,如无人驾驶汽车等技术,它们使用深度学习技术进行导航,带来了广为人知的灾难事件。图片来源:Shutterstock.com/MONOPOLY919。
上述这个被深度学习研究者称之为「对抗攻击」的案例是由谷歌大脑提出的,它暗示着 AI 在达到人类智能上仍有很长的路要走。「我最初认为对抗样本只是一个小烦恼,」多伦多大学的计算机科学家、深度学习先驱之一 Geoffrey Hinton 说:「但我现在认为这个问题可能非常重要,它告诉我们,我们到底做错了什么。」
这是很多人工智能从业者的同感,任何人都可以轻易说出一长串深度学习的弊端。例如,除了易受欺骗之外,深度学习还存在严重的低效率问题。「让一个孩子学会认识一头母牛,」Hinton 说,「他们的母亲不需要说'牛'一万次」,但深度学习系统学习『牛』时需要这么多次。人类通常仅从一两个例子中就能学习新概念。
然后是不透明问题。深度学习系统训练好之后,我们无法确定它是如何做出决定的。「在许多情况下,这是不可接受的,即使它得到了正确的答案,」计算神经科学家、负责剑桥 MIT-IBM Watson AI 实验室的 David Cox 说。假设一家银行使用人工智能来评估你的信誉,然后拒绝给你一笔贷款,「美国多个州的法律都规定必须解释其中的原因,」他说。
也许这里面最重要的就是缺乏常识的问题了。深度学习系统可能在识别像素分布的模式上很擅长,但是它们无法理解模式的含义,更不用说理解模式背后的原因了。「在我看来,当前的系统还不知道沙发和椅子是用来坐的,」DeepMind 的 AI 研究员 Greg Wayne 说。
深度学习暴露的越来越多的弱点正在引起公众对人工智能的关注。特别是在无人驾驶汽车领域,它们使用类似的深度学习技术进行导航,曾经导致了广为人知的灾难和死亡事故。
尽管如此,无可否认,深度学习是一种非常强大的工具。深度学习使得部署应用程序(例如面部识别和语音识别)变得非常常见,这些应用程序在十年前几乎不可能完成。「所以我很难想象深度学习会在这种时候被抛弃,」Cox 说。「更大的可能是对深度学习方法进行修改或增强。」
大脑战争
今天的深度学习革命的根源在于 20 世纪 80 年代的「大脑战争」,当时两种不同的人工智能流派相互争执不休。
一种方法现在被称为「老式的 AI」,自 20 世纪 50 年代以来一直占据着该领域的主导地位,也被称为符号 AI,它使用数学符号来表示对象和对象之间的关系。加上由人类建立的广泛的知识库,这些系统被证明在推理方面非常擅长。但是到了 20 世纪 80 年代,人们越来越清楚地认识到,符号 AI 在处理现实生活中的符号、概念和推理的动态时表现得非常糟糕。
为了应对这些缺点,另一派研究人员开始倡导人工神经网络或连接人工智能,他们是当今深度学习系统的先驱。这种系统的基本思想是通过传播模拟节点(人脑中神经元的类似物)网络中的信号来对其进行处理。信号沿着连接(突触的类似物)从节点传递到节点。类似于真实的大脑,学习是调整可放大或抑制每个连接所携带信号的「权重」的问题。
在实践中,大多数网络将节点排列为一系列层,这些层大致类似于皮层中的不同处理中心。因此,专门用于图像的网络将具有一层输入节点,这些节点对单个像素做出响应,就像视杆细胞和视锥细胞对光线照射视网膜做出响应一样。一旦被激活,这些节点通过加权连接将其激活级别传播到下一级别的其它节点,这些节点组合输入信号并依次激活(或不激活)。这个过程一直持续到信号到达节点的输出层,其中激活模式提供最终预测。例如,输入图像是数字「9」。如果答案是错误的,例如说输入图像是一个「0」。网络会执行反向传播算法在层中向下运行,调整权重以便下次获得更好的结果。
到 20 世纪 80 年代末,在处理嘈杂或模糊的输入时,神经网络已经被证明比符号 AI 好得多。然而,这两种方法之间的对峙仍未得到解决,主要是因为当时计算机能拟合的人工智能系统非常有限。无法确切知道这些系统能够做什么。
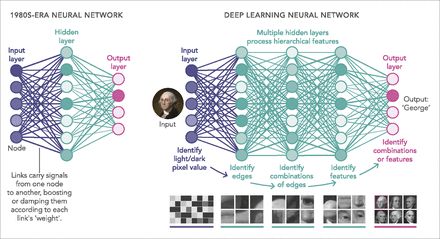
AI 的「神经网络」模型通过类似于神经元的节点网络发送信号。信号沿着连接传递到节点。「学习」会通过调整放大或抑制每个连接所承载信号的权重来改善结果。节点通常以一系列层排列,这些层大致类似于皮质中的不同处理中心。今天的计算机可以处理数十层的「深度学习」网络。图片来源:Lucy Reading-Ikkanda。
算力革命
这种理解在 21 世纪得到变革,随着数量级计算机的出现,功能更加强大的社交媒体网站提供源源不断的图像、声音和其它训练数据。
Hinton 是反向传播算法的联合提出者,也是 20 世纪 80 年代连接主义运动的领导者。他和他的学生们不断尝试训练比以前更大的网络,层数从一个或两个增加到大约六个(今天的商业网络通常使用超过 100 层的网络)。
2009 年,Hinton 和他的两名研究生表示,这种「深度学习」在语音识别上能够超越任何其它已知的方法。2012 年,Hinton 和另外两名学生发表了论文,表明深度神经网络在图像识别上可能比标准视觉系统好得多。「我们几乎将误差率减半,」他说。在这之后,深度学习应用的革命开始了。
研究人员早期更加关注扩展深度学习系统的训练方式,Matthew Botvinick 说。他在 2015 年从普林斯顿的神经科学小组离开,学术休假一年,进入 DeepMind,从那时起一直没有离开。语音和图像识别系统都使用了监督学习,他说:「这意味着每张图片都有一个正确的答案,比如猫的图像的类别必须是'猫'。如果网络预测错误,你就告诉它什么是正确的答案。」然后网络使用反向传播算法来改进其下一个猜测。
Botvinick 说,如果有精心标记的训练样例,监督学习的效果会很好。但一般而言,情况并非如此。它根本不适用于诸如玩视频游戏等没有正确或错误答案的任务,其中仅有成功或失败的策略。
Botvinick 解释说,对于那些情况(事实上,在现实世界的生活中),你需要强化学习。例如,玩视频游戏的强化学习系统学会寻求奖励,并避免惩罚。
2015 年,当 DeepMind 的一个小组训练网络玩经典的 Atari 2600 街机游戏时,首次成功实现了深度强化学习。「网络将在游戏中接收屏幕图像作为输入,」随后加入该公司的 Botvinick 说,「在输出端有指定动作的图层,比如如何移动操纵杆。」该网络的表现达到甚至超过了人类 Atari 玩家。2016 年,DeepMind 研究人员使用掌握了相同网络的更精细版本的 AlphaGo 在围棋上击败了人类世界冠军。
深度学习之外
不幸的是,这些里程碑式的成就都没有解决深度学习的根本问题。以 Atari 系统为例,智能体必须玩上千轮才能掌握多数人类几分钟之内就能学会的游戏。即便如此,网络也无法理解或解释屏幕上的拍子等物体。因此 Hinton 的问题也可以用在这里:到底哪里还没做好?
也许没有哪里没做好。也许我们需要的只是更多的连接、更多的层以及更加复杂的训练方法。毕竟,正如 Botvinick 所指出的,神经网络在数学上等同于一台通用计算机,也就是说只要你能找到正确的连接权重,就没有神经网络处理不了的计算——至少理论上是这样。
但在实践中,出现的错误却可能是致命的——这也是为什么人们越发感觉深度学习的劣势需要从根本上解决。
扩展训练数据的范围是一种简单的解决方法。例如,在 2018 年 5 月发表的一篇论文中,Botvinick 的 DeepMind 团队研究了神经网络在多个任务上训练时发生了什么。他们发现,只要有足够的从后面的层往前传递(这一特性可以让网络随时记住自己在做什么)的「循环」连接,网络就能自动从前面的任务中学习,从而加速后续任务的学习速度。这至少是人类「元学习」(学习如何学习)的一种雏形,而元学习是人类能够快速学习的一大原因。
一种更激进的可能性是,放弃只训练一个大的网络来解决问题的做法,转而让多个网络协同工作。2018 年 6 月,DeepMind 团队发表了一种新方法——生成查询网络(Generative Query Network)架构,该架构利用两个不同的网络,在没有人工输入的复杂虚拟环境中学习。一个是表征网络,本质上是利用标准的图像识别学习来识别在任何给定时刻 AI 能看到的东西。与此同时,生成网络学习获取第一个网络的输出,并生成整个环境的 3D 模型——实际上是对 AI 看不到的对象和特征进行预测。例如,如果一张桌子只有三条腿可见,上述 3D 模型将生成同样大小、形状及颜色的第四条腿。
Botvinick 表示,这些预测反过来又能让系统比使用标准的深度学习方法更快地学习。「一个试图预测事物的智能体会在每一个时间步上自动得到反馈,因为它可以看到自己的预测结果如何。」因此,智能体可以不断更新、优化模型。更妙的是,这种学习是自监督的:研究者不必标记环境中任何事物,甚至也不用提供奖励或惩罚。
一种更彻底的方法是不要再让网络在每一个问题中都从头开始学习。「白板」(blank-slate)方法的确可以让网络自由地发现研究者从未想过的对象、动作的表征方式,也有可能发现一些完全出人意料的玩游戏策略。但人类从来不会从 0 开始:无论如何,人类至少会利用从之前经历中学到的或在进化过程中留在大脑中的先验知识。
例如,婴儿似乎生来就有许多固有的「归纳偏置」,使他们能够以惊人的速度吸收某些核心概念。到了 2 个月大的时候,他们就已经开始掌握一些直观的物理规律,包括物体存在的概念,这些物体倾向于沿着连续的路径移动,当它们接触时,不会互相穿过。这些婴儿也开始拥有一些基础的心理直觉,包括识别面孔的能力,以及认识到世界上存在其他自主行动的智能体。
拥有这种内置的直觉偏置可能会帮助深层神经网络以同样的速度快速学习,因此该领域的许多研究人员优先考虑这种思路。实际上,仅仅在过去的 1 到 2 年里,一种名为图网络的方法就在社区内引起了不小的轰动,这是一种颇有前景的方法。Botvinick 表示,「这种深度学习系统拥有固有偏置,倾向于将事物表征为对象和关系。」例如,某些物体(如爪子、尾巴、胡须)可能都属于一个稍大的对象(猫),它们之间的关系是「A 是 B 的一部分」。同样地,「球 A 和方块 B」之间的关系可能是「相邻」,「地球」绕着「太阳」转……通过大量其他示例——其中任何示例都可以表征为一个抽象图,其中的节点对应于对象,连接对应于关系。
图网络是一种神经网络,它将图作为输入(而不是原始像素或声波),然后学会推理和预测对象及其关系如何随时间演变。(某些应用程序可能会使用独立的标准图像识别网络来分析场景并预先挑选出对象。)
图网络方法已经被证明在各种应用程序上都可以快速学习和达到人类级别的性能,包括复杂的视频游戏。如果它继续像研究人员所希望的那样发展,它就可以通过提高训练速度和效率来缓解深度学习的巨量数据需求问题,并且可以使网络更不容易受到对抗性攻击。因为系统表征的是物体,而不是像素的模式,这使得其不会被少量噪音或无关的杂物轻易误导。
Botvinick 坦言,任何领域都不会轻易或快速地取得根本性进展。但即便如此,他还是坚信:「这些挑战是真实存在的,但并非死路一条。」
推荐阅读
全网最全速查表:Python 机器学习 搭建完美的Python 机器学习开发环境 训练集,验证集,测试集,交叉验证 Matplotlib 三连弹